 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Feedfoward Neural Networks are Almost All You Need for Time Series Forecasting
Mar 30, 2025



Time series data are everywhere -- from finance to healthcare -- and each domain brings its own unique complexities and structures. While advanced models like Transformers and graph neural networks (GNNs) have gained popularity in time series forecasting, largely due to their success in tasks like language modeling, their added complexity is not always necessary. In our work, we show that simple feedforward neural networks (SFNNs) can achieve performance on par with, or even exceeding, these state-of-the-art models, while being simpler, smaller, faster, and more robust. Our analysis indicates that, in many cases, univariate SFNNs are sufficient, implying that modeling interactions between multiple series may offer only marginal benefits. Even when inter-series relationships are strong, a basic multivariate SFNN still delivers competitive results. We also examine some key design choices and offer guidelines on making informed decisions. Additionally, we critique existing benchmarking practices and propose an improved evaluation protocol. Although SFNNs may not be optimal for every situation (hence the ``almost'' in our title) they serve as a strong baseline that future time series forecasting methods should always be compared against.
KirchhoffNet: A Circuit Bridging Message Passing and Continuous-Depth Models
Oct 24, 2023In this paper, we exploit a fundamental principle of analog electronic circuitry, Kirchhoff's current law, to introduce a unique class of neural network models that we refer to as KirchhoffNet. KirchhoffNet establishes close connections with message passing neural networks and continuous-depth networks. We demonstrate that even in the absence of any traditional layers (such as convolution, pooling, or linear layers), KirchhoffNet attains 98.86% test accuracy on the MNIST dataset, comparable with state of the art (SOTA) results. What makes KirchhoffNet more intriguing is its potential in the realm of hardware. Contemporary deep neural networks are conventionally deployed on GPUs. In contrast, KirchhoffNet can be physically realized by an analog electronic circuit. Moreover, we justify that irrespective of the number of parameters within a KirchhoffNet, its forward calculation can always be completed within 1/f seconds, with f representing the hardware's clock frequency. This characteristic introduces a promising technology for implementing ultra-large-scale neural networks.
Nominality Score Conditioned Time Series Anomaly Detection by Point/Sequential Reconstruction
Oct 24, 2023



Time series anomaly detection is challenging due to the complexity and variety of patterns that can occur. One major difficulty arises from modeling time-dependent relationships to find contextual anomalies while maintaining detection accuracy for point anomalies. In this paper, we propose a framework for unsupervised time series anomaly detection that utilizes point-based and sequence-based reconstruction models. The point-based model attempts to quantify point anomalies, and the sequence-based model attempts to quantify both point and contextual anomalies. Under the formulation that the observed time point is a two-stage deviated value from a nominal time point, we introduce a nominality score calculated from the ratio of a combined value of the reconstruction errors. We derive an induced anomaly score by further integrating the nominality score and anomaly score, then theoretically prove the superiority of the induced anomaly score over the original anomaly score under certain conditions. Extensive studies conducted on several public datasets show that the proposed framework outperforms most state-of-the-art baselines for time series anomaly detection.
Learning from Multiple Annotator Noisy Labels via Sample-wise Label Fusion
Jul 22, 2022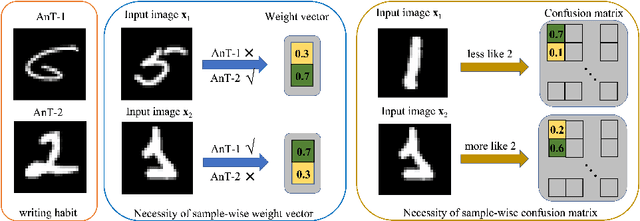
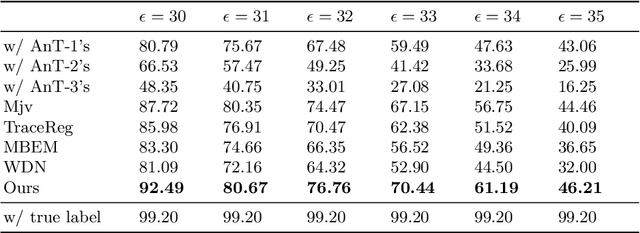
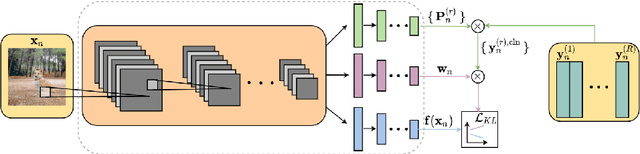
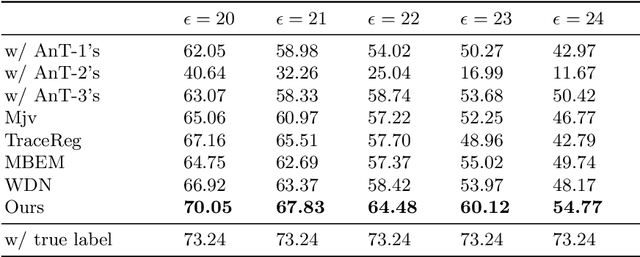
Data lies at the core of modern deep learning. The impressive performance of supervised learning is built upon a base of massive accurately labeled data. However, in some real-world applications, accurate labeling might not be viable; instead, multiple noisy labels (instead of one accurate label) are provided by several annotators for each data sample. Learning a classifier on such a noisy training dataset is a challenging task. Previous approaches usually assume that all data samples share the same set of parameters related to annotator errors, while we demonstrate that label error learning should be both annotator and data sample dependent. Motivated by this observation, we propose a novel learning algorithm. The proposed method displays superiority compared with several state-of-the-art baseline methods on MNIST, CIFAR-100, and ImageNet-100. Our code is available at: https://github.com/zhengqigao/Learning-from-Multiple-Annotator-Noisy-Labels.
FreDo: Frequency Domain-based Long-Term Time Series Forecasting
May 24, 2022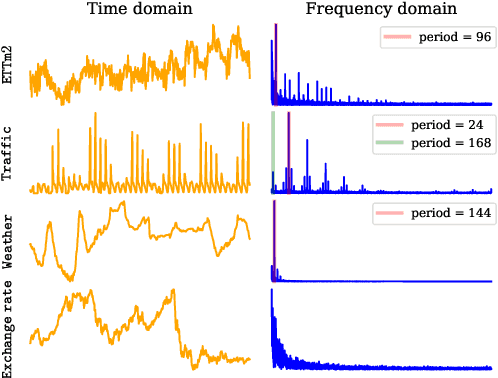
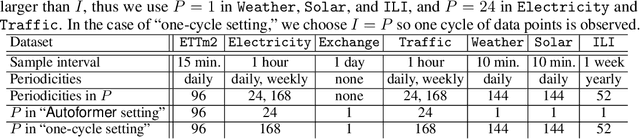
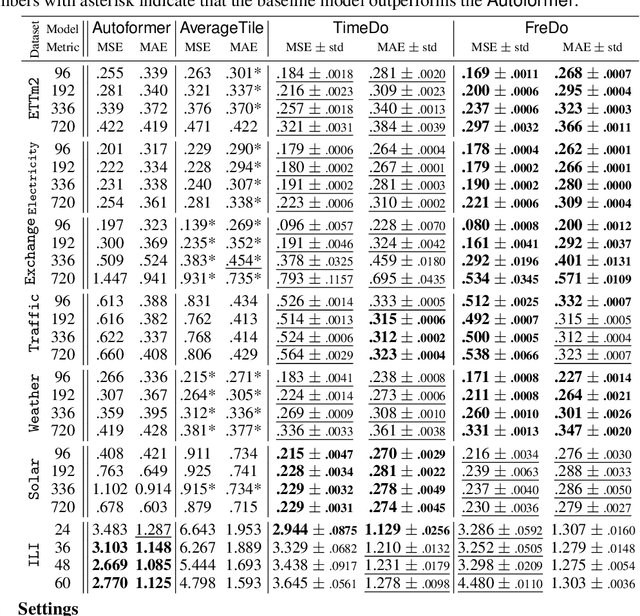
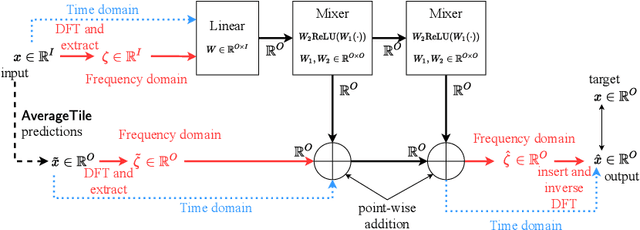
The ability to forecast far into the future is highly beneficial to many applications, including but not limited to climatology, energy consumption, and logistics. However, due to noise or measurement error, it is questionable how far into the future one can reasonably predict. In this paper, we first mathematically show that due to error accumulation, sophisticated models might not outperform baseline models for long-term forecasting. To demonstrate, we show that a non-parametric baseline model based on periodicity can actually achieve comparable performance to a state-of-the-art Transformer-based model on various datasets. We further propose FreDo, a frequency domain-based neural network model that is built on top of the baseline model to enhance its performance and which greatly outperforms the state-of-the-art model. Finally, we validate that the frequency domain is indeed better by comparing univariate models trained in the frequency v.s. time domain.
Adjusting for Autocorrelated Errors in Neural Networks for Time Series Regression and Forecasting
Feb 01, 2021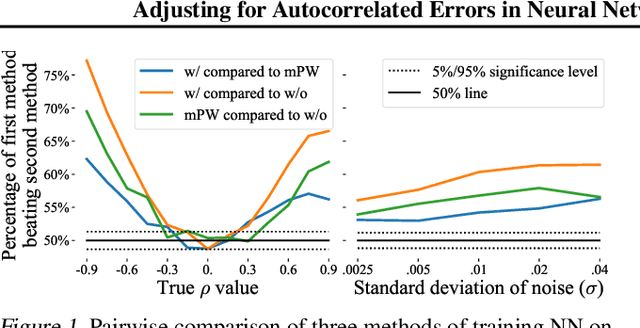
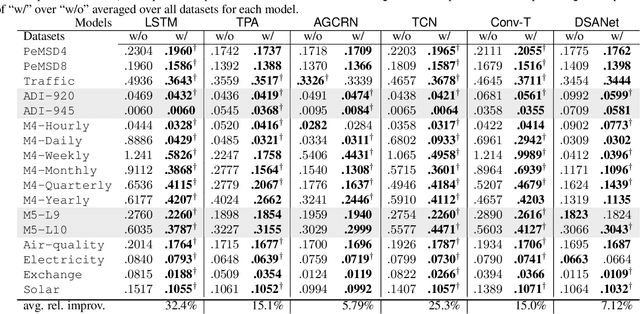
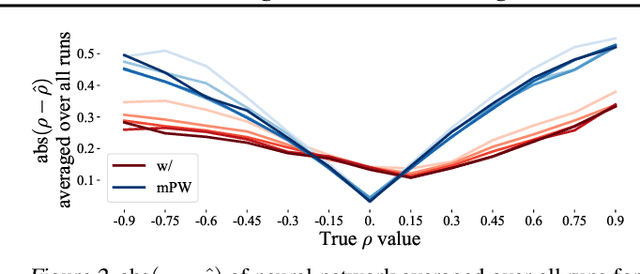
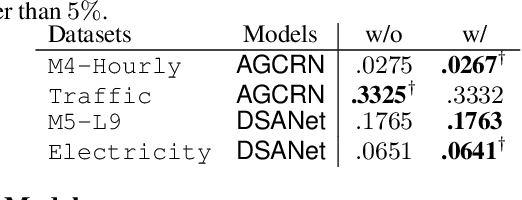
In many cases, it is difficult to generate highly accurate models for time series data using a known parametric model structure. In response, an increasing body of research focuses on using neural networks to model time series approximately. A common assumption in training neural networks on time series is that the errors at different time steps are uncorrelated. However, due to the temporality of the data, errors are actually autocorrelated in many cases, which makes such maximum likelihood estimation inaccurate. In this paper, we propose to learn the autocorrelation coefficient jointly with the model parameters in order to adjust for autocorrelated errors. For time series regression, large-scale experiments indicate that our method outperforms the Prais-Winsten method, especially when the autocorrelation is strong. Furthermore, we broaden our method to time series forecasting and apply it with various state-of-the-art models. Results across a wide range of real-world datasets show that our method enhances performance in almost all cases.
Conditioned Natural Language Generation using only Unconditioned Language Model: An Exploration
Nov 14, 2020



Transformer-based language models have shown to be very powerful for natural language generation (NLG). However, text generation conditioned on some user inputs, such as topics or attributes, is non-trivial. Past approach relies on either modifying the original LM architecture, re-training the LM on corpora with attribute labels, or having separately trained `guidance models' to guide text generation in decoding. We argued that the above approaches are not necessary, and the original unconditioned LM is sufficient for conditioned NLG. We evaluated our approaches by the samples' fluency and diversity with automated and human evaluation.
Variational inference formulation for a model-free simulation of a dynamical system with unknown parameters by a recurrent neural network
Mar 02, 2020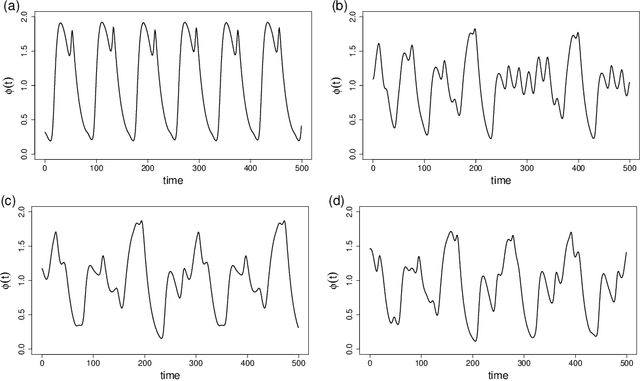

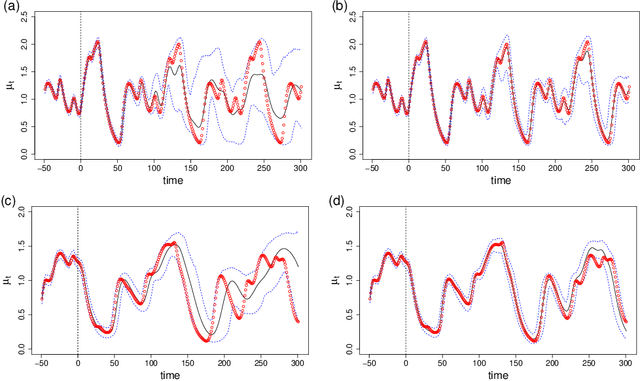

We propose a recurrent neural network for a "model-free" simulation of a dynamical system with unknown parameters without prior knowledge. The deep learning model aims to jointly learn the nonlinear time marching operator and the effects of the unknown parameters from a time series dataset. We assume that the time series data set consists of an ensemble of trajectories for a range of the parameters. The learning task is formulated as a statistical inference problem by considering the unknown parameters as random variables. A variational inference method is employed to train a recurrent neural network jointly with a feedforward neural network for an approximately posterior distribution. The approximate posterior distribution makes an inference on a trajectory to identify the effects of the unknown parameters and a recurrent neural network makes a prediction by using the outcome of the inference. In the numerical experiments, it is shown that the proposed variational inference model makes a more accurate simulation compared to the standard recurrent neural networks. It is found that the proposed deep learning model is capable of correctly identifying the dimensions of the random parameters and learning a representation of complex time series data.
LAMAL: LAnguage Modeling Is All You Need for Lifelong Language Learning
Sep 07, 2019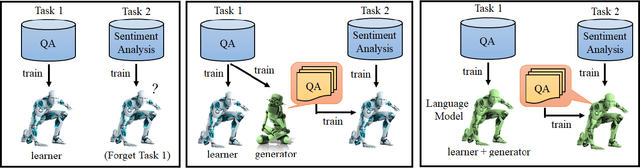
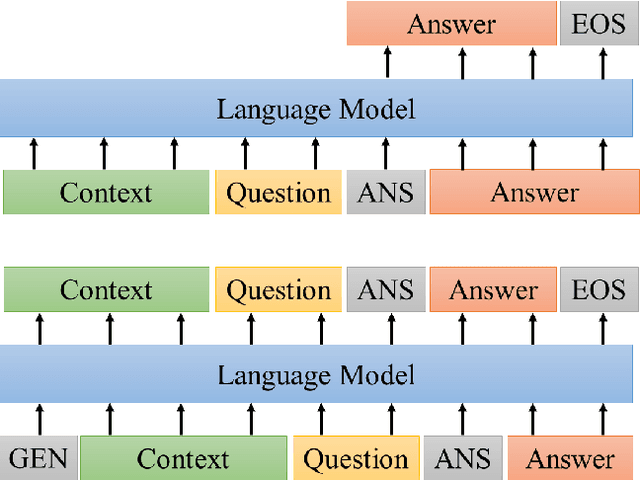
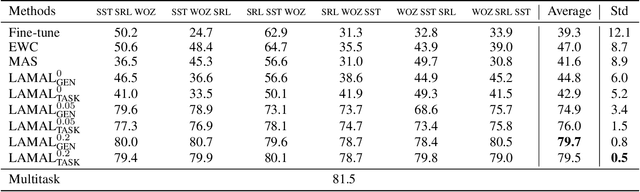
Most research on lifelong learning (LLL) applies to images or games, but not language. Here, we introduce LAMAL, a simple yet effective method for LLL based on language modeling. LAMAL replays pseudo samples of previous tasks while requiring no extra memory or model capacity. To be specific, LAMAL is a language model learning to solve the task and generate training samples at the same time. At the beginning of training a new task, the model generates some pseudo samples of previous tasks to train alongside the data of the new task. The results show that LAMAL prevents catastrophic forgetting without any sign of intransigence and can solve up to five very different language tasks sequentially with only one model. Overall, LAMAL outperforms previous methods by a considerable margin and is only 2-3\% worse than multitasking which is usually considered as the upper bound of LLL. Our source code is available at https://github.com/xxx.
Temporal Pattern Attention for Multivariate Time Series Forecasting
Sep 12, 2018
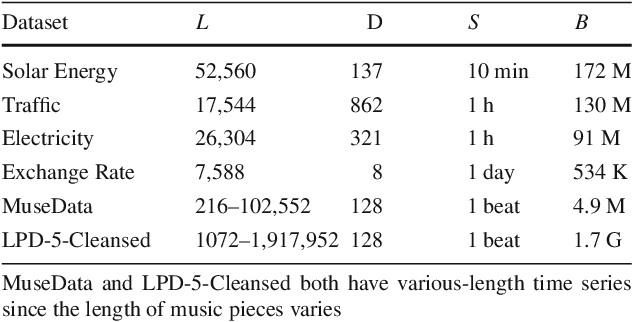
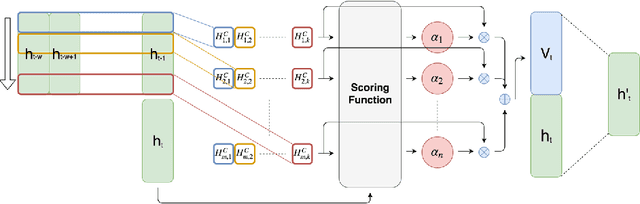
Forecasting multivariate time series data, such as prediction of electricity consumption, solar power production, and polyphonic piano pieces, has numerous valuable applications. However, complex and non-linear interdependencies between time steps and series complicate the task. To obtain accurate prediction, it is crucial to model long-term dependency in time series data, which can be achieved to some good extent by recurrent neural network (RNN) with attention mechanism. Typical attention mechanism reviews the information at each previous time step and selects the relevant information to help generate the outputs, but it fails to capture the temporal patterns across multiple time steps. In this paper, we propose to use a set of filters to extract time-invariant temporal patterns, which is similar to transforming time series data into its "frequency domain". Then we proposed a novel attention mechanism to select relevant time series, and use its "frequency domain" information for forecasting. We applied the proposed model on several real-world tasks and achieved the state-of-the-art performance in all of them with only one exception. We also show that to some degree the learned filters play the role of bases in discrete Fourier transform.