 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Oculomotor Behaviors from Scanpath
Aug 11, 2021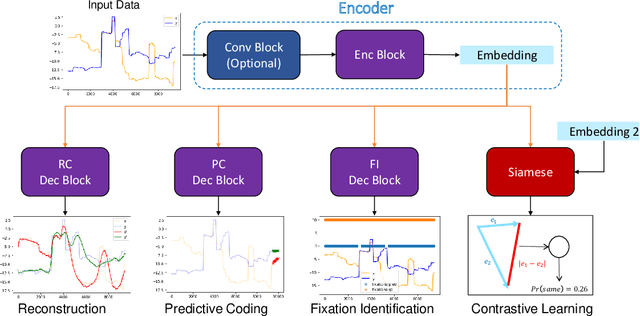
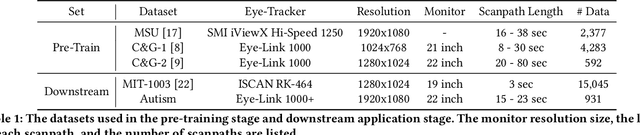
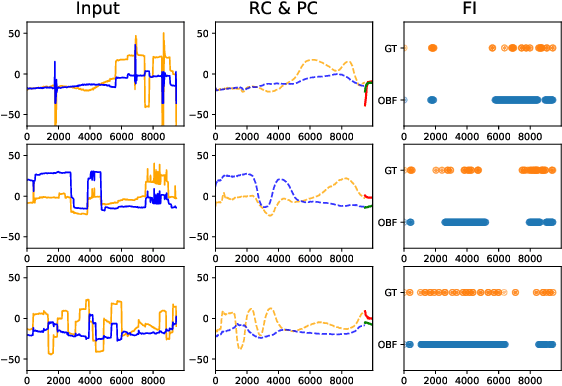
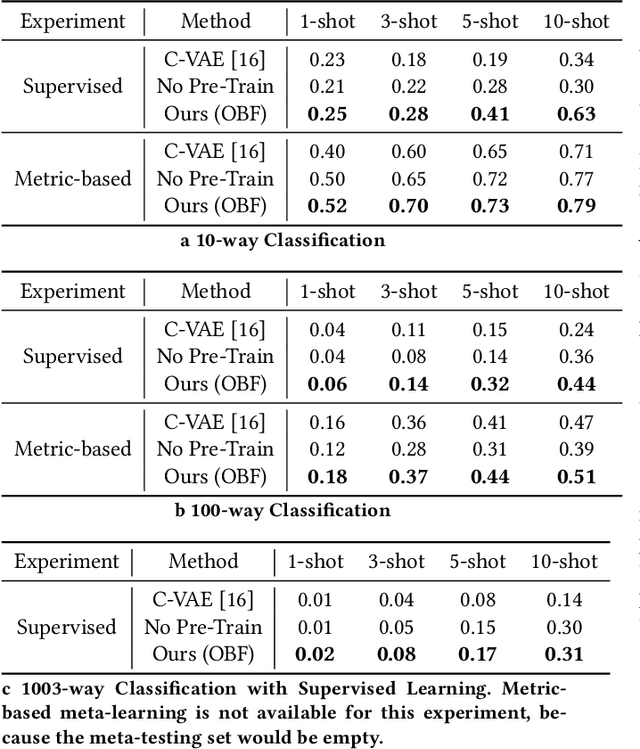
Identifying oculomotor behaviors relevant for eye-tracking applications is a critical but often challenging task. Aiming to automatically learn and extract knowledge from existing eye-tracking data, we develop a novel method that creates rich representations of oculomotor scanpaths to facilitate the learning of downstream tasks. The proposed stimulus-agnostic Oculomotor Behavior Framework (OBF) model learns human oculomotor behaviors from unsupervised and semi-supervised tasks, including reconstruction, predictive coding, fixation identification, and contrastive learning tasks. The resultant pre-trained OBF model can be used in a variety of applications. Our pre-trained model outperforms baseline approaches and traditional scanpath methods in autism spectrum disorder and viewed-stimulus classification tasks. Ablation experiments further show our proposed method could achieve even better results with larger model sizes and more diverse eye-tracking training datasets, supporting the model's potential for future eye-tracking applications. Open source code: http://github.com/BeibinLi/OBF.
Sparsely Grouped Input Variables for Neural Networks
Nov 29, 2019

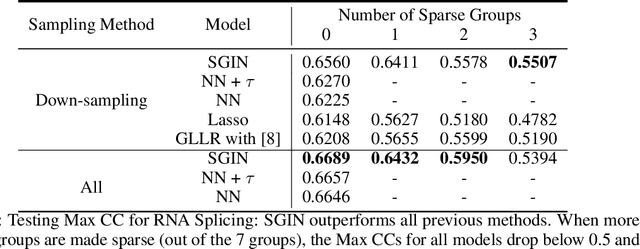
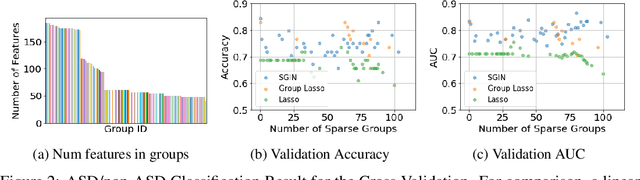
In genomic analysis, biomarker discovery, image recognition, and other systems involving machine learning, input variables can often be organized into different groups by their source or semantic category. Eliminating some groups of variables can expedite the process of data acquisition and avoid over-fitting. Researchers have used the group lasso to ensure group sparsity in linear models and have extended it to create compact neural networks in meta-learning. Different from previous studies, we use multi-layer non-linear neural networks to find sparse groups for input variables. We propose a new loss function to regularize parameters for grouped input variables, design a new optimization algorithm for this loss function, and test these methods in three real-world settings. We achieve group sparsity for three datasets, maintaining satisfying results while excluding one nucleotide position from an RNA splicing experiment, excluding 89.9% of stimuli from an eye-tracking experiment, and excluding 60% of image rows from an experiment on the MNIST dataset.