 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Planning Shape on Dyna-style Planning in High-dimensional State Spaces
Jun 08, 2018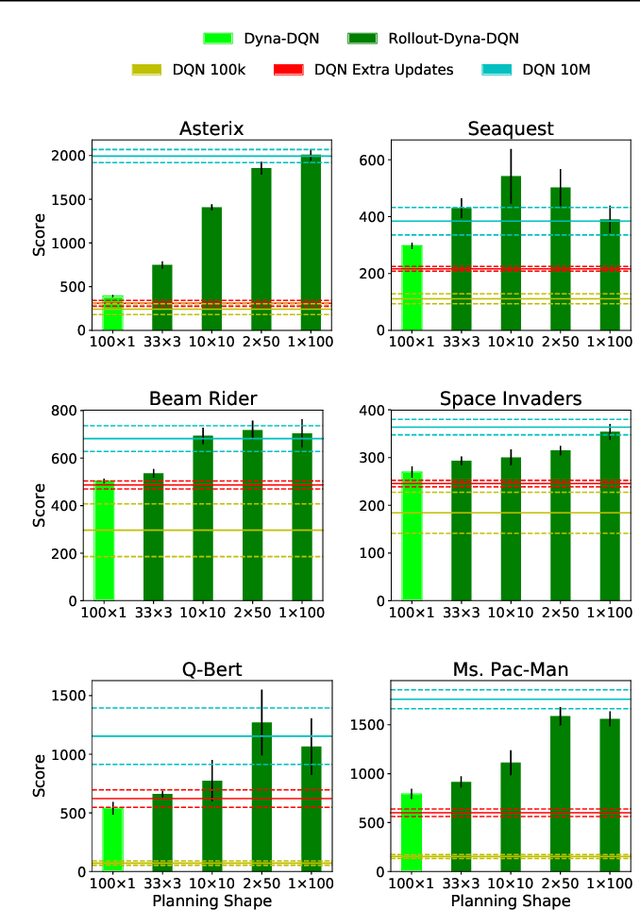

Dyna is an architecture for reinforcement learning agents that interleaves planning, acting, and learning in an online setting. This architecture aims to make fuller use of limited experience to achieve better performance with fewer environmental interactions. Dyna has been well studied in problems with a tabular representation of states, and has also been extended to some settings with larger state spaces that require function approximation. However, little work has studied Dyna in environments with high-dimensional state spaces like images. In Dyna, the environment model is typically used to generate one-step transitions from selected start states. We applied one-step Dyna to several games from the Arcade Learning Environment and found that the model-based updates offered surprisingly little benefit, even with a perfect model. However, when the model was used to generate longer trajectories of simulated experience, performance improved dramatically. This observation also holds when using a model that is learned from experience; even though the learned model is flawed, it can still be used to accelerate learning.
Learning the Reward Function for a Misspecified Model
Jun 08, 2018

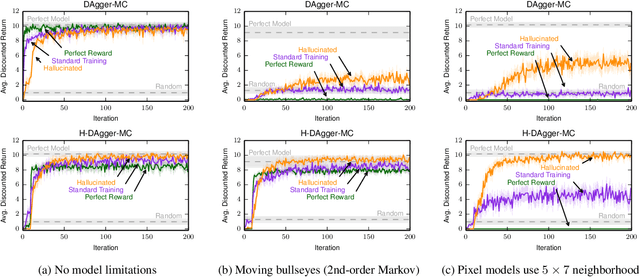
In model-based reinforcement learning it is typical to decouple the problems of learning the dynamics model and learning the reward function. However, when the dynamics model is flawed, it may generate erroneous states that would never occur in the true environment. It is not clear a priori what value the reward function should assign to such states. This paper presents a novel error bound that accounts for the reward model's behavior in states sampled from the model. This bound is used to extend the existing Hallucinated DAgger-MC algorithm, which offers theoretical performance guarantees in deterministic MDPs that do not assume a perfect model can be learned. Empirically, this approach to reward learning can yield dramatic improvements in control performance when the dynamics model is flawed.
Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents
Dec 01, 2017
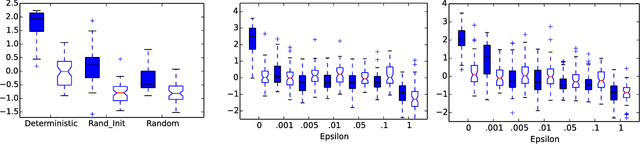


The Arcade Learning Environment (ALE) is an evaluation platform that poses the challenge of building AI agents with general competency across dozens of Atari 2600 games. It supports a variety of different problem settings and it has been receiving increasing attention from the scientific community, leading to some high-profile success stories such as the much publicized Deep Q-Networks (DQN). In this article we take a big picture look at how the ALE is being used by the research community. We show how diverse the evaluation methodologies in the ALE have become with time, and highlight some key concerns when evaluating agents in the ALE. We use this discussion to present some methodological best practices and provide new benchmark results using these best practices. To further the progress in the field, we introduce a new version of the ALE that supports multiple game modes and provides a form of stochasticity we call sticky actions. We conclude this big picture look by revisiting challenges posed when the ALE was introduced, summarizing the state-of-the-art in various problems and highlighting problems that remain open.
Self-Correcting Models for Model-Based Reinforcement Learning
Jul 26, 2017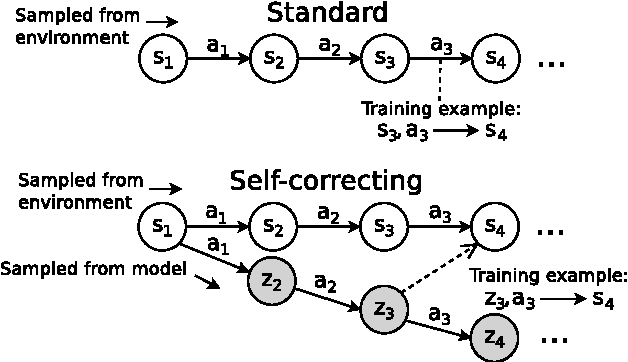

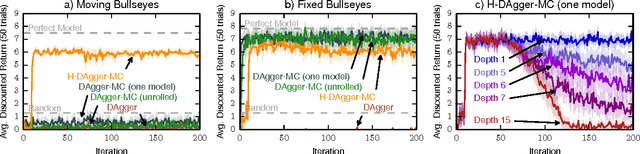
When an agent cannot represent a perfectly accurate model of its environment's dynamics, model-based reinforcement learning (MBRL) can fail catastrophically. Planning involves composing the predictions of the model; when flawed predictions are composed, even minor errors can compound and render the model useless for planning. Hallucinated Replay (Talvitie 2014) trains the model to "correct" itself when it produces errors, substantially improving MBRL with flawed models. This paper theoretically analyzes this approach, illuminates settings in which it is likely to be effective or ineffective, and presents a novel error bound, showing that a model's ability to self-correct is more tightly related to MBRL performance than one-step prediction error. These results inspire an MBRL algorithm for deterministic MDPs with performance guarantees that are robust to model class limitations.
* Original paper appeared in Proceedings of the 31st AAAI Conference on Artificial Intelligence, 2017. This version incorporates the appendix into document (rather than as supplementary material), corrects a minor error in Lemma 1, and fixes some type-os
State of the Art Control of Atari Games Using Shallow Reinforcement Learning
Apr 21, 2016


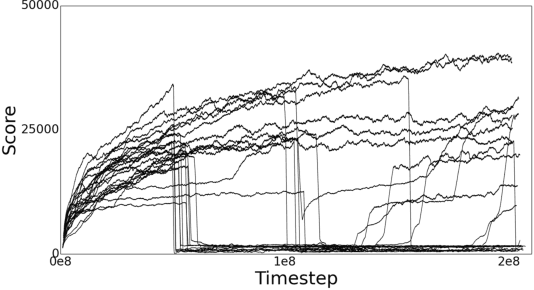
The recently introduced Deep Q-Networks (DQN) algorithm has gained attention as one of the first successful combinations of deep neural networks and reinforcement learning. Its promise was demonstrated in the Arcade Learning Environment (ALE), a challenging framework composed of dozens of Atari 2600 games used to evaluate general competency in AI. It achieved dramatically better results than earlier approaches, showing that its ability to learn good representations is quite robust and general. This paper attempts to understand the principles that underlie DQN's impressive performance and to better contextualize its success. We systematically evaluate the importance of key representational biases encoded by DQN's network by proposing simple linear representations that make use of these concepts. Incorporating these characteristics, we obtain a computationally practical feature set that achieves competitive performance to DQN in the ALE. Besides offering insight into the strengths and weaknesses of DQN, we provide a generic representation for the ALE, significantly reducing the burden of learning a representation for each game. Moreover, we also provide a simple, reproducible benchmark for the sake of comparison to future work in the ALE.
Learning to Make Predictions In Partially Observable Environments Without a Generative Model
Jan 16, 2014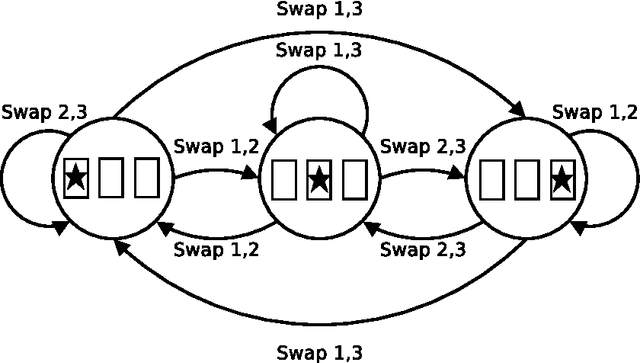


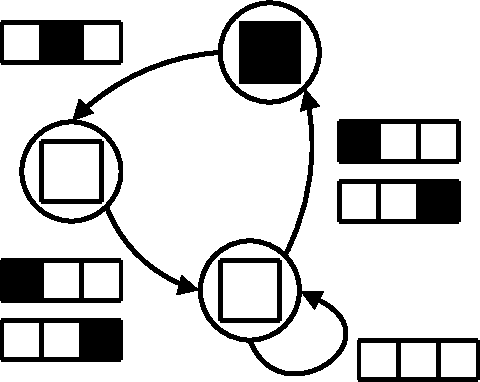
When faced with the problem of learning a model of a high-dimensional environment, a common approach is to limit the model to make only a restricted set of predictions, thereby simplifying the learning problem. These partial models may be directly useful for making decisions or may be combined together to form a more complete, structured model. However, in partially observable (non-Markov) environments, standard model-learning methods learn generative models, i.e. models that provide a probability distribution over all possible futures (such as POMDPs). It is not straightforward to restrict such models to make only certain predictions, and doing so does not always simplify the learning problem. In this paper we present prediction profile models: non-generative partial models for partially observable systems that make only a given set of predictions, and are therefore far simpler than generative models in some cases. We formalize the problem of learning a prediction profile model as a transformation of the original model-learning problem, and show empirically that one can learn prediction profile models that make a small set of important predictions even in systems that are too complex for standard generative models.