 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correcting Models for Model-Based Reinforcement Learning
Paper and Code
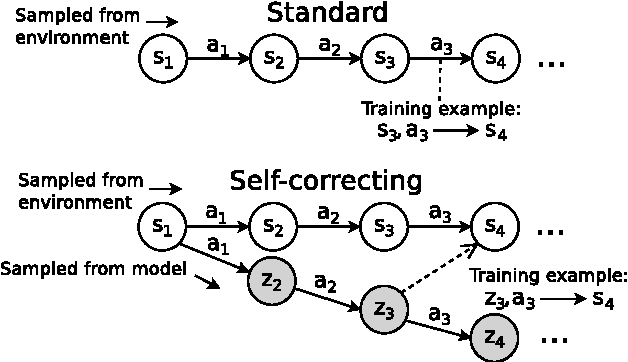

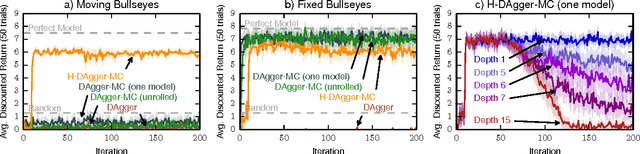
When an agent cannot represent a perfectly accurate model of its environment's dynamics, model-based reinforcement learning (MBRL) can fail catastrophically. Planning involves composing the predictions of the model; when flawed predictions are composed, even minor errors can compound and render the model useless for planning. Hallucinated Replay (Talvitie 2014) trains the model to "correct" itself when it produces errors, substantially improving MBRL with flawed models. This paper theoretically analyzes this approach, illuminates settings in which it is likely to be effective or ineffective, and presents a novel error bound, showing that a model's ability to self-correct is more tightly related to MBRL performance than one-step prediction error. These results inspire an MBRL algorithm for deterministic MDPs with performance guarantees that are robust to model class limitations.