 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNymeriaPlus: Enriching Nymeria Dataset with Additional Annotations and Data
Mar 19, 2026The Nymeria Dataset, released in 2024, is a large-scale collection of in-the-wild human activities captured with multiple egocentric wearable devices that are spatially localized and temporally synchronized. It provides body-motion ground truth recorded with a motion-capture suit, device trajectories, semi-dense 3D point clouds, and in-context narrations. In this paper, we upgrade Nymeria and introduce NymeriaPlus. NymeriaPlus features: (1) improved human motion in Momentum Human Rig (MHR) and SMPL formats; (2) dense 3D and 2D bounding box annotations for indoor objects and structural elements; (3) instance-level 3D object reconstructions; and (4) additional modalities e.g., basemap recordings, audio, and wristband videos. By consolidating these complementary modalities and annotations into a single, coherent benchmark, NymeriaPlus strengthens Nymeria into a more powerful in-the-wild egocentric dataset. We expect NymeriaPlus to bridge a key gap in existing egocentric resources and to support a broader range of research, including unique explorations of multimodal learning for embodied AI.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Meta 3D Gen
Jul 02, 2024


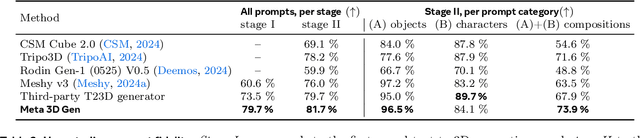
We introduce Meta 3D Gen (3DGen), a new state-of-the-art, fast pipeline for text-to-3D asset generation. 3DGen offers 3D asset creation with high prompt fidelity and high-quality 3D shapes and textures in under a minute. It supports physically-based rendering (PBR), necessary for 3D asset relighting in real-world applications. Additionally, 3DGen supports generative retexturing of previously generated (or artist-created) 3D shapes using additional textual inputs provided by the user. 3DGen integrates key technical components, Meta 3D AssetGen and Meta 3D TextureGen, that we developed for text-to-3D and text-to-texture generation, respectively. By combining their strengths, 3DGen represents 3D objects simultaneously in three ways: in view space, in volumetric space, and in UV (or texture) space. The integration of these two techniques achieves a win rate of 68% with respect to the single-stage model. We compare 3DGen to numerous industry baselines, and show that it outperforms them in terms of prompt fidelity and visual quality for complex textual prompts, while being significantly faster.
Going Deeper with Point Networks
Jul 01, 2019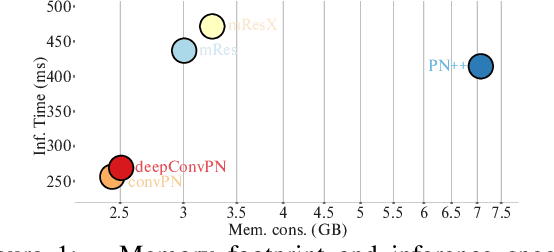

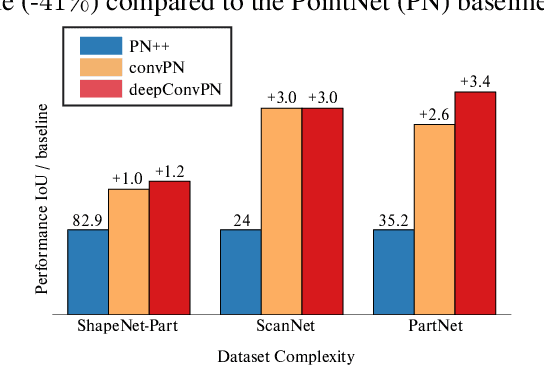
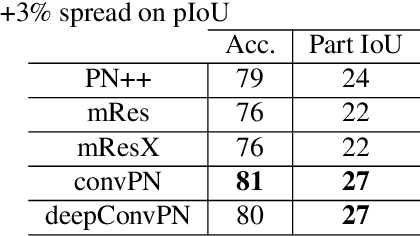
In this work, we introduce three generic point cloud processing blocks that improve both accuracy and memory consumption of state-of-the-art networks thus allowing to design deeper and more accurate networks. The novel processing blocks are: a multi-resolution point cloud processing block; a convolution-type operation for point sets that blends neighborhood information in a memory-efficient manner; and a crosslink block that efficiently shares information across low- and high-resolution processing branches. Combining these blocks allows us to design significantly wider and deeper architectures. We extensively evaluate the proposed architectures on multiple point segmentation benchmarks (ShapeNet-Part, ScanNet, PartNet) and report systematic improvements in terms of both accuracy and memory consumption by using our generic modules in conjunction with multiple recent architectures (PointNet++, DGCNN, SpiderCNN, PointCNN). We report a 3.4% increase in IoU on the -most complex- PartNet dataset while decreasing memory footprint by 57%.