 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPA: Constrained PARAFAC2 for Sparse & Large Datasets
Aug 27, 2018
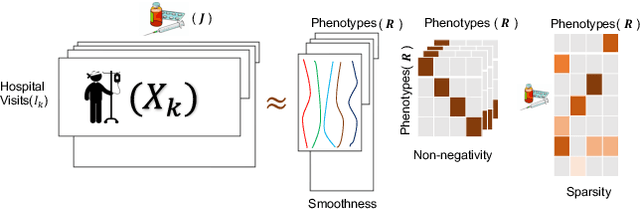

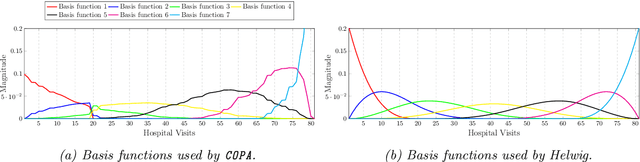
PARAFAC2 has demonstrated success in modeling irregular tensors, where the tensor dimensions vary across one of the modes. An example scenario is modeling treatments across a set of patients with the varying number of medical encounters over time. Despite recent improvements on unconstrained PARAFAC2, its model factors are usually dense and sensitive to noise which limits their interpretability. As a result, the following open challenges remain: a) various modeling constraints, such as temporal smoothness, sparsity and non-negativity, are needed to be imposed for interpretable temporal modeling and b) a scalable approach is required to support those constraints efficiently for large datasets. To tackle these challenges, we propose a {\it CO}nstrained {\it PA}RAFAC2 (COPA) method, which carefully incorporates optimization constraints such as temporal smoothness, sparsity, and non-negativity in the resulting factors. To efficiently support all those constraints, COPA adopts a hybrid optimization framework using alternating optimization and alternating direction method of multiplier (AO-ADMM). As evaluated on large electronic health record (EHR) datasets with hundreds of thousands of patients, COPA achieves significant speedups (up to 36 times faster) over prior PARAFAC2 approaches that only attempt to handle a subset of the constraints that COPA enables. Overall, our method outperforms all the baselines attempting to handle a subset of the constraints in terms of speed, while achieving the same level of accuracy. Through a case study on temporal phenotyping of medically complex children, we demonstrate how the constraints imposed by COPA reveal concise phenotypes and meaningful temporal profiles of patients. The clinical interpretation of both the phenotypes and the temporal profiles was confirmed by a medical expert.
SPARTan: Scalable PARAFAC2 for Large & Sparse Data
Mar 13, 2017

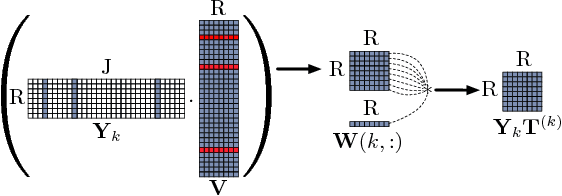
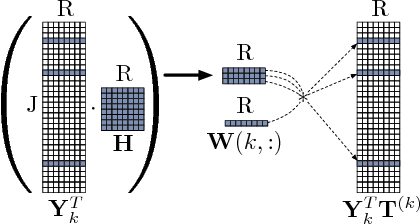
In exploratory tensor mining, a common problem is how to analyze a set of variables across a set of subjects whose observations do not align naturally. For example, when modeling medical features across a set of patients, the number and duration of treatments may vary widely in time, meaning there is no meaningful way to align their clinical records across time points for analysis purposes. To handle such data, the state-of-the-art tensor model is the so-called PARAFAC2, which yields interpretable and robust output and can naturally handle sparse data. However, its main limitation up to now has been the lack of efficient algorithms that can handle large-scale datasets. In this work, we fill this gap by developing a scalable method to compute the PARAFAC2 decomposition of large and sparse datasets, called SPARTan. Our method exploits special structure within PARAFAC2, leading to a novel algorithmic reformulation that is both fast (in absolute time) and more memory-efficient than prior work. We evaluate SPARTan on both synthetic and real datasets, showing 22X performance gains over the best previous implementation and also handling larger problem instances for which the baseline fails. Furthermore, we are able to apply SPARTan to the mining of temporally-evolving phenotypes on data taken from real and medically complex pediatric patients. The clinical meaningfulness of the phenotypes identified in this process, as well as their temporal evolution over time for several patients, have been endorsed by clinical experts.
Multi-layer Representation Learning for Medical Concepts
Feb 17, 2016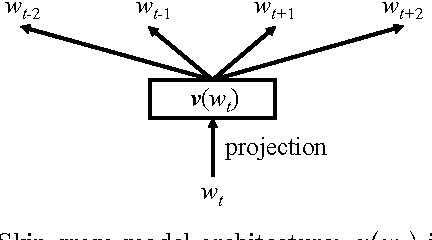
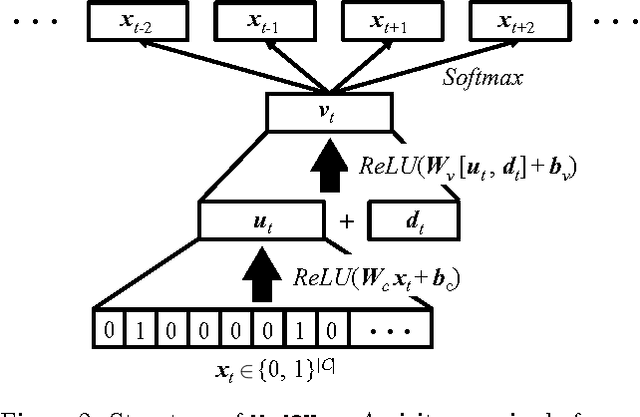
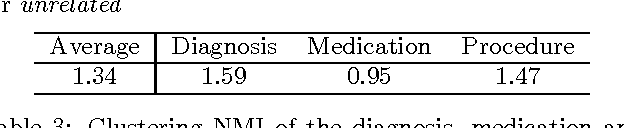
Learning efficient representations for concepts has been proven to be an important basis for many applications such as machine translation or document classification. Proper representations of medical concepts such as diagnosis, medication, procedure codes and visits will have broad applications in healthcare analytics. However, in Electronic Health Records (EHR) the visit sequences of patients include multiple concepts (diagnosis, procedure, and medication codes) per visit. This structure provides two types of relational information, namely sequential order of visits and co-occurrence of the codes within each visit. In this work, we propose Med2Vec, which not only learns distributed representations for both medical codes and visits from a large EHR dataset with over 3 million visits, but also allows us to interpret the learned representations confirmed positively by clinical experts. In the experiments, Med2Vec displays significant improvement in key medical applications compared to popular baselines such as Skip-gram, GloVe and stacked autoencoder, while providing clinically meaningful interpretation.