 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore efficient manual review of automatically transcribed tabular data
Jun 28, 2023Machine learning methods have proven useful in transcribing historical data. However, results from even highly accurate methods require manual verification and correction. Such manual review can be time-consuming and expensive, therefore the objective of this paper was to make it more efficient. Previously, we used machine learning to transcribe 2.3 million handwritten occupation codes from the Norwegian 1950 census with high accuracy (97%). We manually reviewed the 90,000 (3%) codes with the lowest model confidence. We allocated those 90,000 codes to human reviewers, who used our annotation tool to review the codes. To assess reviewer agreement, some codes were assigned to multiple reviewers. We then analyzed the review results to understand the relationship between accuracy improvements and effort. Additionally, we interviewed the reviewers to improve the workflow. The reviewers corrected 62.8% of the labels and agreed with the model label in 31.9% of cases. About 0.2% of the images could not be assigned a label, while for 5.1% the reviewers were uncertain, or they assigned an invalid label. 9,000 images were independently reviewed by multiple reviewers, resulting in an agreement of 86.43% and disagreement of 8.96%. We learned that our automatic transcription is biased towards the most frequent codes, with a higher degree of misclassification for the lowest frequency codes. Our interview findings show that the reviewers did internal quality control and found our custom tool well-suited. So, only one reviewer is needed, but they should report uncertainty.
What is the state of the art? Accounting for multiplicity in machine learning benchmark performance
Mar 10, 2023Machine learning methods are commonly evaluated and compared by their performance on data sets from public repositories. This allows for multiple methods, oftentimes several thousands, to be evaluated under identical conditions and across time. The highest ranked performance on a problem is referred to as state-of-the-art (SOTA) performance, and is used, among other things, as a reference point for publication of new methods. Using the highest-ranked performance as an estimate for SOTA is a biased estimator, giving overly optimistic results. The mechanisms at play are those of multiplicity, a topic that is well-studied in the context of multiple comparisons and multiple testing, but has, as far as the authors are aware of, been nearly absent from the discussion regarding SOTA estimates. The optimistic state-of-the-art estimate is used as a standard for evaluating new methods, and methods with substantial inferior results are easily overlooked. In this article, we provide a probability distribution for the case of multiple classifiers so that known analyses methods can be engaged and a better SOTA estimate can be provided. We demonstrate the impact of multiplicity through a simulated example with independent classifiers. We show how classifier dependency impacts the variance, but also that the impact is limited when the accuracy is high. Finally, we discuss a real-world example; a Kaggle competition from 2020.
Occode: an end-to-end machine learning pipeline for transcription of historical population censuses
Jun 07, 2021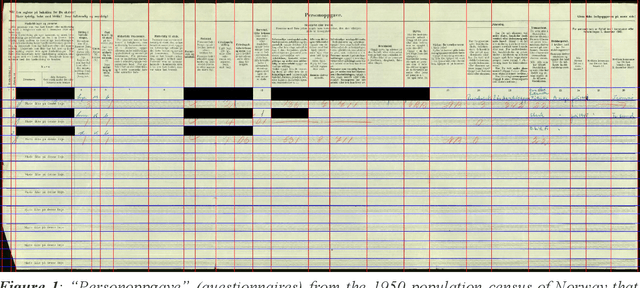
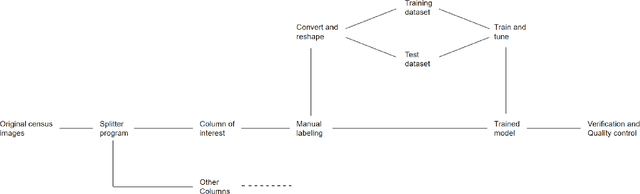
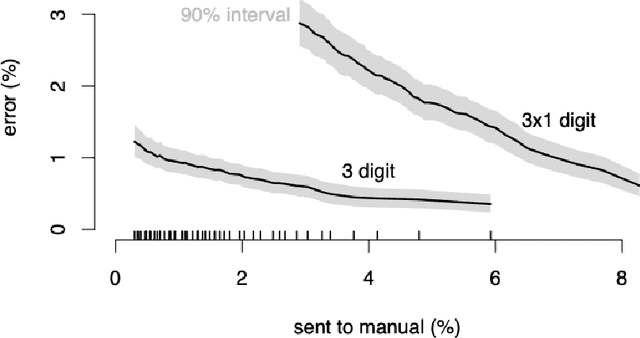
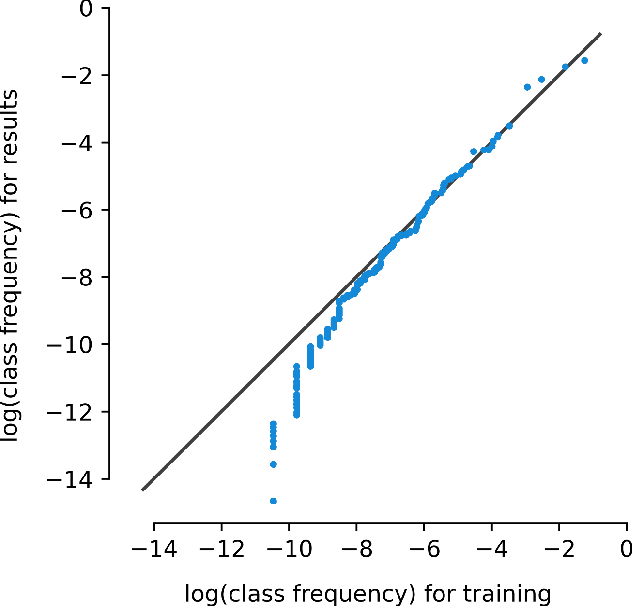
Machine learning approaches achieve high accuracy for text recognition and are therefore increasingly used for the transcription of handwritten historical sources. However, using machine learning in production requires a streamlined end-to-end machine learning pipeline that scales to the dataset size, and a model that achieves high accuracy with few manual transcriptions. In addition, the correctness of the model results must be verified. This paper describes our lessons learned developing, tuning, and using the Occode end-to-end machine learning pipeline for transcribing 7,3 million rows with handwritten occupation codes in the Norwegian 1950 population census. We achieve an accuracy of 97% for the automatically transcribed codes, and we send 3% of the codes for manual verification. We verify that the occupation code distribution found in our result matches the distribution found in our training data which should be representative for the census as a whole. We believe our approach and lessons learned are useful for other transcription projects that plan to use machine learning in production. The source code is available at: https://github.com/uit-hdl/rhd-codes
Interactive exploration of population scale pharmacoepidemiology datasets
May 20, 2020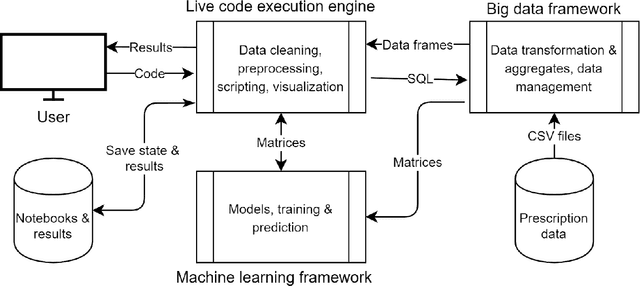
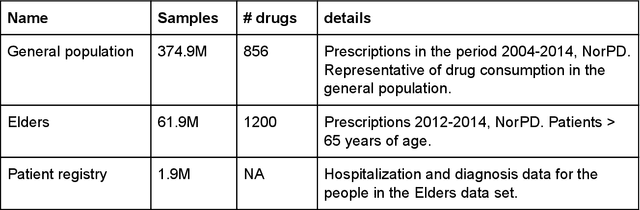

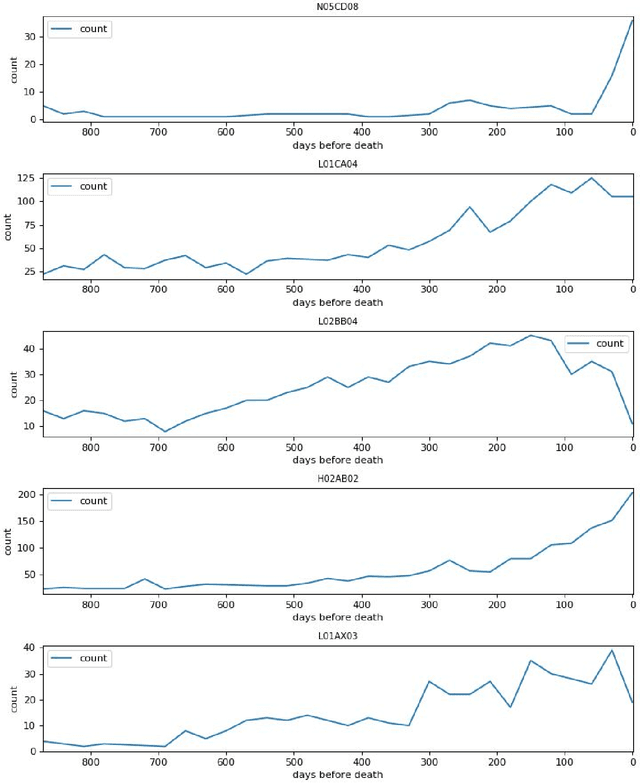
Population-scale drug prescription data linked with adverse drug reaction (ADR) data supports the fitting of models large enough to detect drug use and ADR patterns that are not detectable using traditional methods on smaller datasets. However, detecting ADR patterns in large datasets requires tools for scalable data processing, machine learning for data analysis, and interactive visualization. To our knowledge no existing pharmacoepidemiology tool supports all three requirements. We have therefore created a tool for interactive exploration of patterns in prescription datasets with millions of samples. We use Spark to preprocess the data for machine learning and for analyses using SQL queries. We have implemented models in Keras and the scikit-learn framework. The model results are visualized and interpreted using live Python coding in Jupyter. We apply our tool to explore a 384 million prescription data set from the Norwegian Prescription Database combined with a 62 million prescriptions for elders that were hospitalized. We preprocess the data in two minutes, train models in seconds, and plot the results in milliseconds. Our results show the power of combining computational power, short computation times, and ease of use for analysis of population scale pharmacoepidemiology datasets. The code is open source and available at: https://github.com/uit-hdl/norpd_prescription_analyses
Convolutional neural network for breathing phase detection in lung sounds
Mar 25, 2019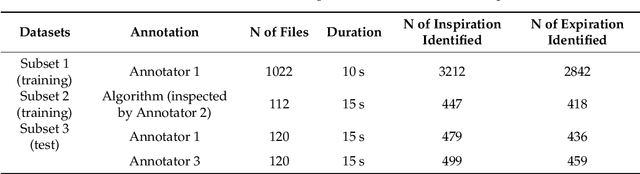



We applied deep learning to create an algorithm for breathing phase detection in lung sound recordings, and we compared the breathing phases detected by the algorithm and manually annotated by two experienced lung sound researchers. Our algorithm uses a convolutional neural network with spectrograms as the features, removing the need to specify features explicitly. We trained and evaluated the algorithm using three subsets that are larger than previously seen in the literature. We evaluated the performance of the method using two methods. First, discrete count of agreed breathing phases (using 50% overlap between a pair of boxes), shows a mean agreement with lung sound experts of 97% for inspiration and 87% for expiration. Second, the fraction of time of agreement (in seconds) gives higher pseudo-kappa values for inspiration (0.73-0.88) than expiration (0.63-0.84), showing an average sensitivity of 97% and an average specificity of 84%. With both evaluation methods, the agreement between the annotators and the algorithm shows human level performance for the algorithm. The developed algorithm is valid for detecting breathing phases in lung sound recordings.
Feature Extraction for Machine Learning Based Crackle Detection in Lung Sounds from a Health Survey
Dec 23, 2017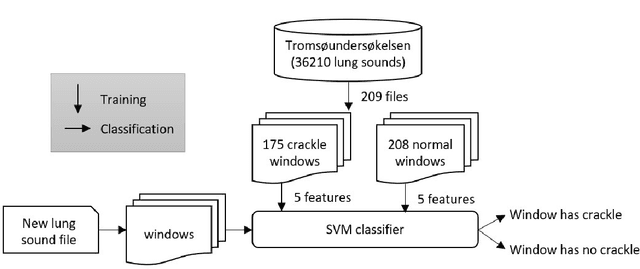
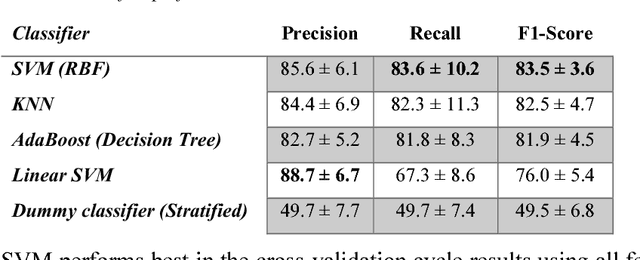
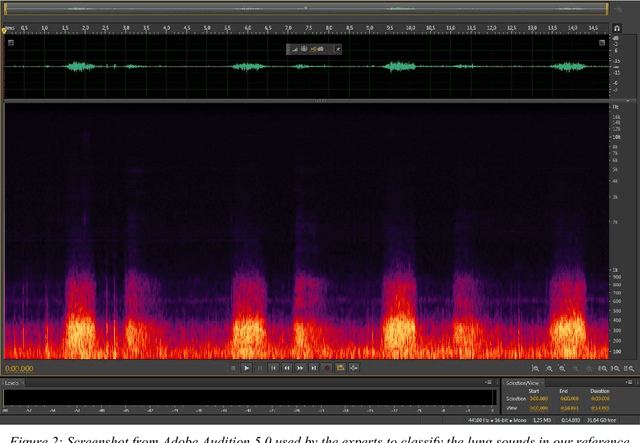
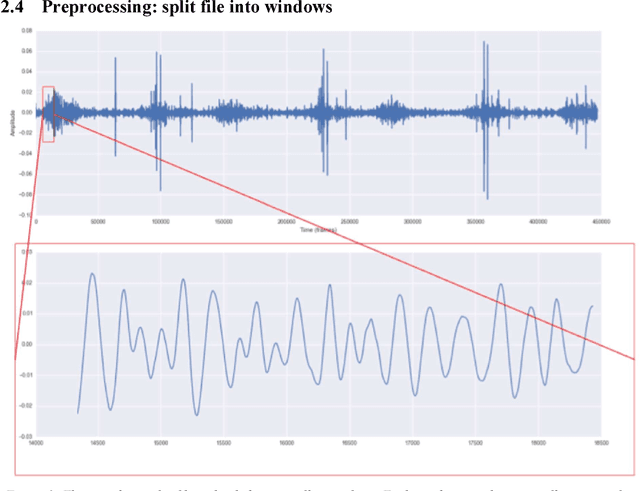
In recent years, many innovative solutions for recording and viewing sounds from a stethoscope have become available. However, to fully utilize such devices, there is a need for an automated approach for detecting abnormal lung sounds, which is better than the existing methods that typically have been developed and evaluated using a small and non-diverse dataset. We propose a machine learning based approach for detecting crackles in lung sounds recorded using a stethoscope in a large health survey. Our method is trained and evaluated using 209 files with crackles classified by expert listeners. Our analysis pipeline is based on features extracted from small windows in audio files. We evaluated several feature extraction methods and classifiers. We evaluated the pipeline using a training set of 175 crackle windows and 208 normal windows. We did 100 cycles of cross validation where we shuffled training sets between cycles. For all the division between training and evaluation was 70%-30%. We found and evaluated a 5-dimenstional vector with four features from the time domain and one from the spectrum domain. We evaluated several classifiers and found SVM with a Radial Basis Function Kernel to perform best. Our approach had a precision of 86% and recall of 84% for classifying a crackle in a window, which is more accurate than found in studies of health personnel. The low-dimensional feature vector makes the SVM very fast. The model can be trained on a regular computer in 1.44 seconds, and 319 crackles can be classified in 1.08 seconds. Our approach detects and visualizes individual crackles in recorded audio files. It is accurate, fast, and has low resource requirements. It can be used to train health personnel or as part of a smartphone application for Bluetooth stethoscopes.