 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccode: an end-to-end machine learning pipeline for transcription of historical population censuses
Paper and Code
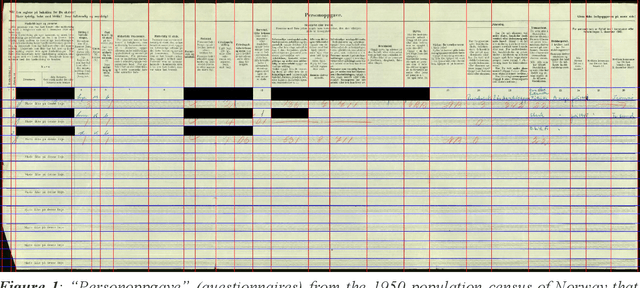
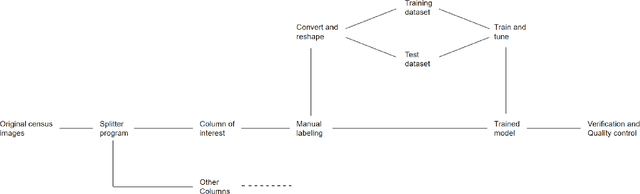
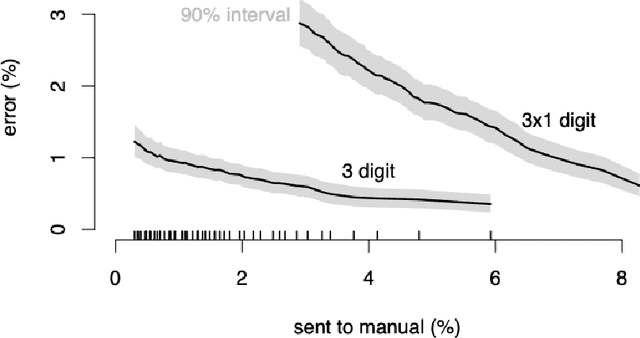
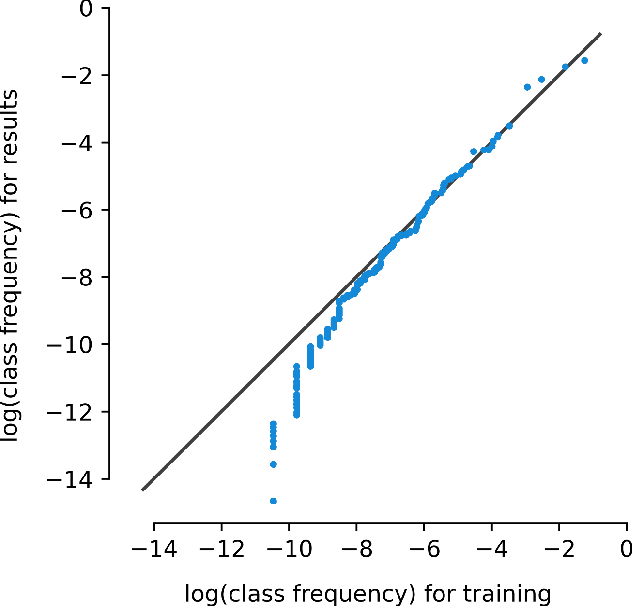
Machine learning approaches achieve high accuracy for text recognition and are therefore increasingly used for the transcription of handwritten historical sources. However, using machine learning in production requires a streamlined end-to-end machine learning pipeline that scales to the dataset size, and a model that achieves high accuracy with few manual transcriptions. In addition, the correctness of the model results must be verified. This paper describes our lessons learned developing, tuning, and using the Occode end-to-end machine learning pipeline for transcribing 7,3 million rows with handwritten occupation codes in the Norwegian 1950 population census. We achieve an accuracy of 97% for the automatically transcribed codes, and we send 3% of the codes for manual verification. We verify that the occupation code distribution found in our result matches the distribution found in our training data which should be representative for the census as a whole. We believe our approach and lessons learned are useful for other transcription projects that plan to use machine learning in production. The source code is available at: https://github.com/uit-hdl/rhd-codes