 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional neural network for breathing phase detection in lung sounds
Mar 25, 2019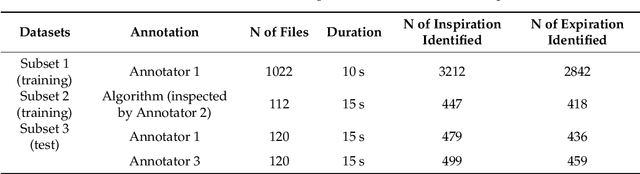



We applied deep learning to create an algorithm for breathing phase detection in lung sound recordings, and we compared the breathing phases detected by the algorithm and manually annotated by two experienced lung sound researchers. Our algorithm uses a convolutional neural network with spectrograms as the features, removing the need to specify features explicitly. We trained and evaluated the algorithm using three subsets that are larger than previously seen in the literature. We evaluated the performance of the method using two methods. First, discrete count of agreed breathing phases (using 50% overlap between a pair of boxes), shows a mean agreement with lung sound experts of 97% for inspiration and 87% for expiration. Second, the fraction of time of agreement (in seconds) gives higher pseudo-kappa values for inspiration (0.73-0.88) than expiration (0.63-0.84), showing an average sensitivity of 97% and an average specificity of 84%. With both evaluation methods, the agreement between the annotators and the algorithm shows human level performance for the algorithm. The developed algorithm is valid for detecting breathing phases in lung sound recordings.
Feature Extraction for Machine Learning Based Crackle Detection in Lung Sounds from a Health Survey
Dec 23, 2017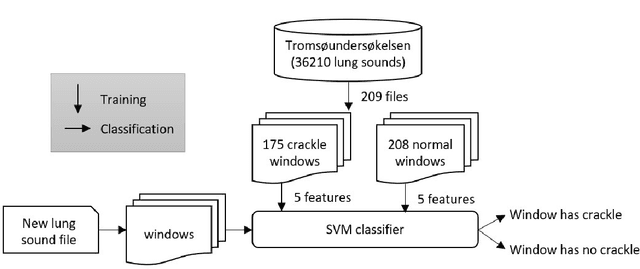
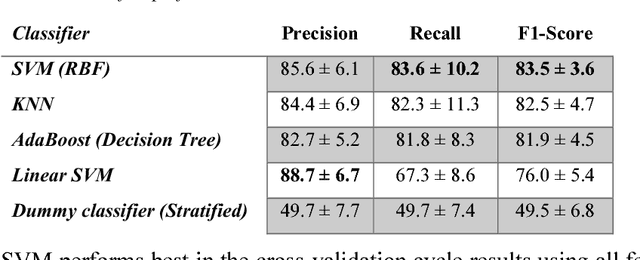
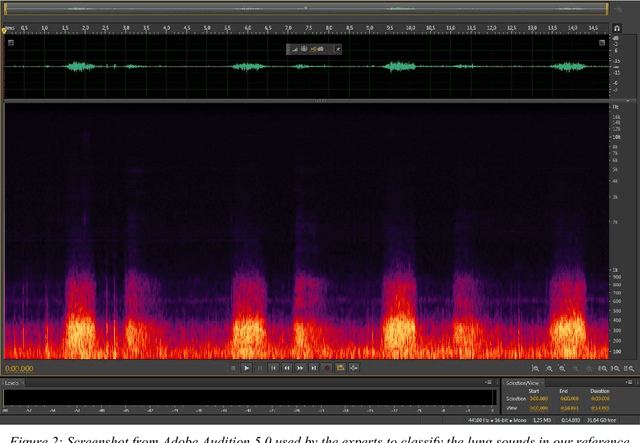
In recent years, many innovative solutions for recording and viewing sounds from a stethoscope have become available. However, to fully utilize such devices, there is a need for an automated approach for detecting abnormal lung sounds, which is better than the existing methods that typically have been developed and evaluated using a small and non-diverse dataset. We propose a machine learning based approach for detecting crackles in lung sounds recorded using a stethoscope in a large health survey. Our method is trained and evaluated using 209 files with crackles classified by expert listeners. Our analysis pipeline is based on features extracted from small windows in audio files. We evaluated several feature extraction methods and classifiers. We evaluated the pipeline using a training set of 175 crackle windows and 208 normal windows. We did 100 cycles of cross validation where we shuffled training sets between cycles. For all the division between training and evaluation was 70%-30%. We found and evaluated a 5-dimenstional vector with four features from the time domain and one from the spectrum domain. We evaluated several classifiers and found SVM with a Radial Basis Function Kernel to perform best. Our approach had a precision of 86% and recall of 84% for classifying a crackle in a window, which is more accurate than found in studies of health personnel. The low-dimensional feature vector makes the SVM very fast. The model can be trained on a regular computer in 1.44 seconds, and 319 crackles can be classified in 1.08 seconds. Our approach detects and visualizes individual crackles in recorded audio files. It is accurate, fast, and has low resource requirements. It can be used to train health personnel or as part of a smartphone application for Bluetooth stethoscopes.