 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive exploration of population scale pharmacoepidemiology datasets
Paper and Code
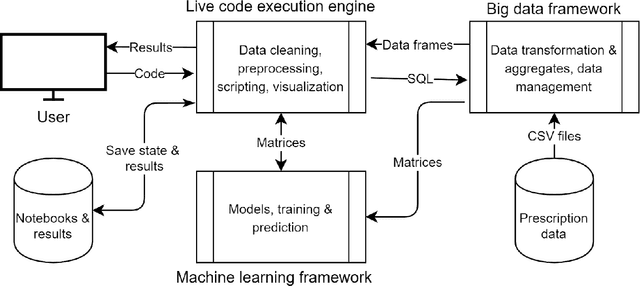
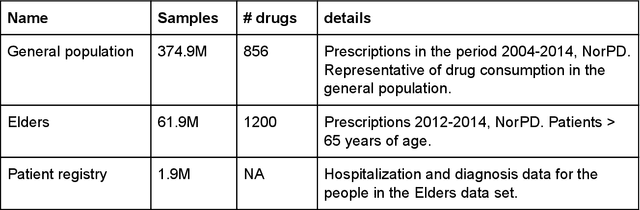

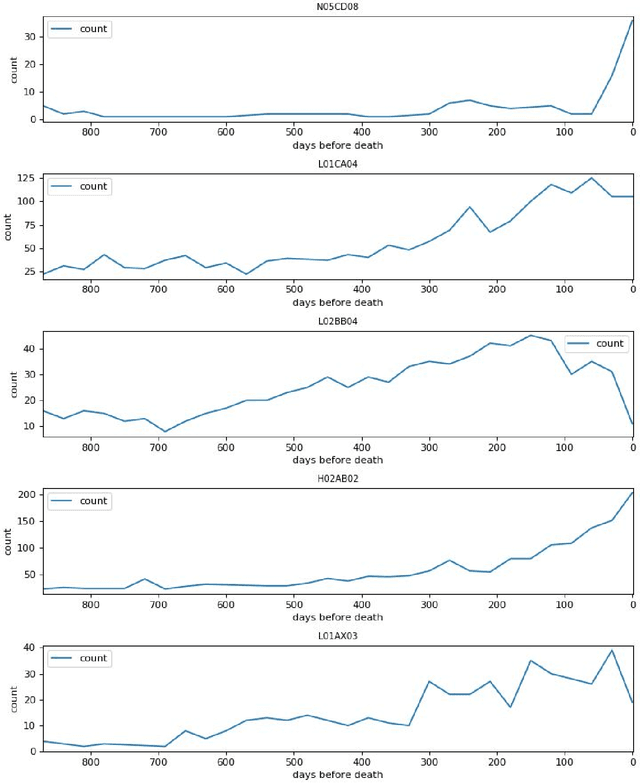
Population-scale drug prescription data linked with adverse drug reaction (ADR) data supports the fitting of models large enough to detect drug use and ADR patterns that are not detectable using traditional methods on smaller datasets. However, detecting ADR patterns in large datasets requires tools for scalable data processing, machine learning for data analysis, and interactive visualization. To our knowledge no existing pharmacoepidemiology tool supports all three requirements. We have therefore created a tool for interactive exploration of patterns in prescription datasets with millions of samples. We use Spark to preprocess the data for machine learning and for analyses using SQL queries. We have implemented models in Keras and the scikit-learn framework. The model results are visualized and interpreted using live Python coding in Jupyter. We apply our tool to explore a 384 million prescription data set from the Norwegian Prescription Database combined with a 62 million prescriptions for elders that were hospitalized. We preprocess the data in two minutes, train models in seconds, and plot the results in milliseconds. Our results show the power of combining computational power, short computation times, and ease of use for analysis of population scale pharmacoepidemiology datasets. The code is open source and available at: https://github.com/uit-hdl/norpd_prescription_analyses