 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerSoMed: A Large-Scale Balanced Dataset for Persian Social Media Text Classification
Feb 22, 2026This research introduces the first large-scale, well-balanced Persian social media text classification dataset, specifically designed to address the lack of comprehensive resources in this domain. The dataset comprises 36,000 posts across nine categories (Economic, Artistic, Sports, Political, Social, Health, Psychological, Historical, and Science & Technology), each containing 4,000 samples to ensure balanced class distribution. Data collection involved 60,000 raw posts from various Persian social media platforms, followed by rigorous preprocessing and hybrid annotation combining ChatGPT-based few-shot prompting with human verification. To mitigate class imbalance, we employed undersampling with semantic redundancy removal and advanced data augmentation strategies integrating lexical replacement and generative prompting. We benchmarked several models, including BiLSTM, XLM-RoBERTa (with LoRA and AdaLoRA adaptations), FaBERT, SBERT-based architectures, and the Persian-specific TookaBERT (Base and Large). Experimental results show that transformer-based models consistently outperform traditional neural networks, with TookaBERT-Large achieving the best performance (Precision: 0.9622, Recall: 0.9621, F1- score: 0.9621). Class-wise evaluation further confirms robust performance across all categories, though social and political texts exhibited slightly lower scores due to inherent ambiguity. This research presents a new high-quality dataset and provides comprehensive evaluations of cutting-edge models, establishing a solid foundation for further developments in Persian NLP, including trend analysis, social behavior modeling, and user classification. The dataset is publicly available to support future research endeavors.
PABSA: Hybrid Framework for Persian Aspect-Based Sentiment Analysis
Oct 05, 2025
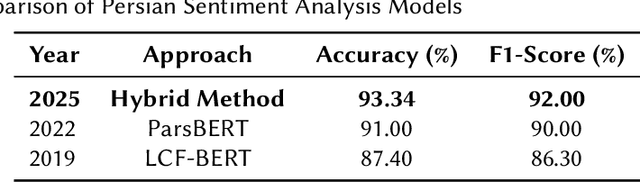
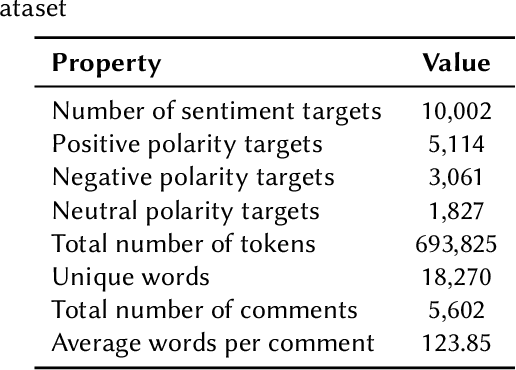
Sentiment analysis is a key task in Natural Language Processing (NLP), enabling the extraction of meaningful insights from user opinions across various domains. However, performing sentiment analysis in Persian remains challenging due to the scarcity of labeled datasets, limited preprocessing tools, and the lack of high-quality embeddings and feature extraction methods. To address these limitations, we propose a hybrid approach that integrates machine learning (ML) and deep learning (DL) techniques for Persian aspect-based sentiment analysis (ABSA). In particular, we utilize polarity scores from multilingual BERT as additional features and incorporate them into a decision tree classifier, achieving an accuracy of 93.34%-surpassing existing benchmarks on the Pars-ABSA dataset. Additionally, we introduce a Persian synonym and entity dictionary, a novel linguistic resource that supports text augmentation through synonym and named entity replacement. Our results demonstrate the effectiveness of hybrid modeling and feature augmentation in advancing sentiment analysis for low-resource languages such as Persian.
LSCP: Enhanced Large Scale Colloquial Persian Language Understanding
Mar 13, 2020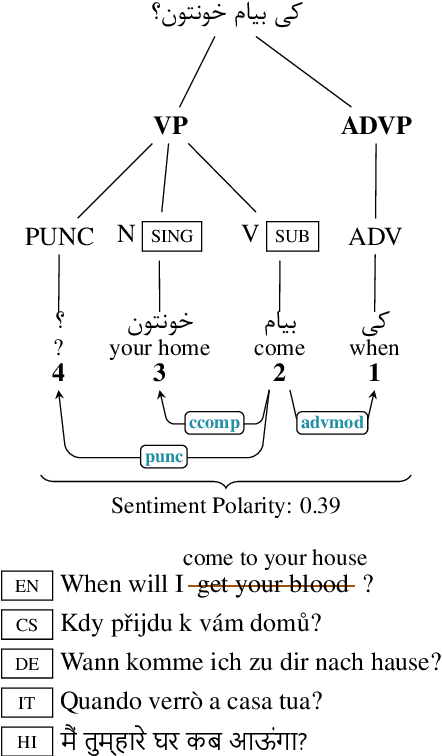

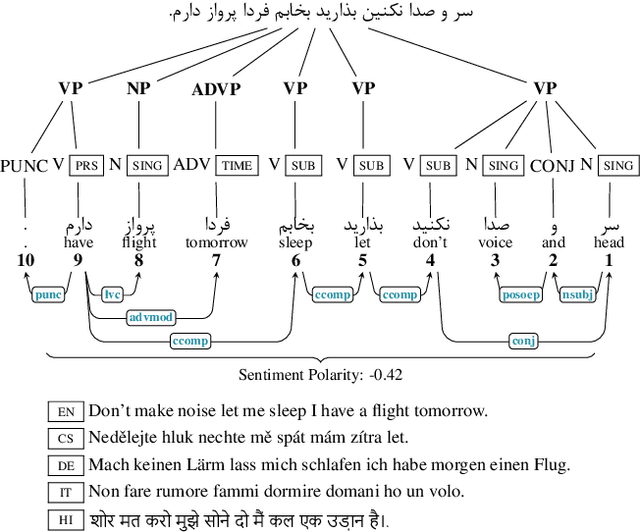
Language recognition has been significantly advanced in recent years by means of modern machine learning methods such as deep learning and benchmarks with rich annotations. However, research is still limited in low-resource formal languages. This consists of a significant gap in describing the colloquial language especially for low-resourced ones such as Persian. In order to target this gap for low resource languages, we propose a "Large Scale Colloquial Persian Dataset" (LSCP). LSCP is hierarchically organized in a semantic taxonomy that focuses on multi-task informal Persian language understanding as a comprehensive problem. This encompasses the recognition of multiple semantic aspects in the human-level sentences, which naturally captures from the real-world sentences. We believe that further investigations and processing, as well as the application of novel algorithms and methods, can strengthen enriching computerized understanding and processing of low resource languages. The proposed corpus consists of 120M sentences resulted from 27M tweets annotated with parsing tree, part-of-speech tags, sentiment polarity and translation in five different languages.
Deep Multimodal Image-Text Embeddings for Automatic Cross-Media Retrieval
Feb 23, 2020
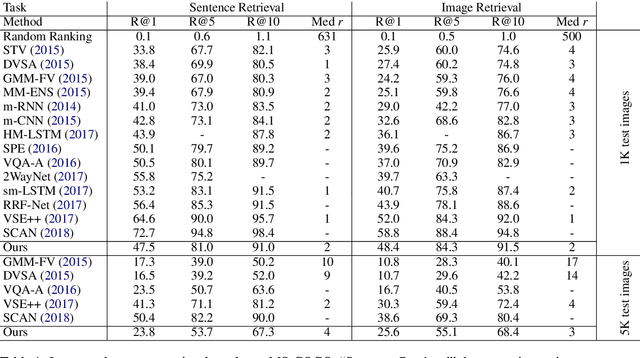
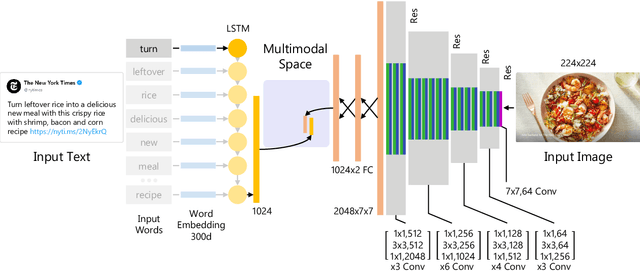
This paper considers the task of matching images and sentences by learning a visual-textual embedding space for cross-modal retrieval. Finding such a space is a challenging task since the features and representations of text and image are not comparable. In this work, we introduce an end-to-end deep multimodal convolutional-recurrent network for learning both vision and language representations simultaneously to infer image-text similarity. The model learns which pairs are a match (positive) and which ones are a mismatch (negative) using a hinge-based triplet ranking. To learn about the joint representations, we leverage our newly extracted collection of tweets from Twitter. The main characteristic of our dataset is that the images and tweets are not standardized the same as the benchmarks. Furthermore, there can be a higher semantic correlation between the pictures and tweets contrary to benchmarks in which the descriptions are well-organized. Experimental results on MS-COCO benchmark dataset show that our model outperforms certain methods presented previously and has competitive performance compared to the state-of-the-art. The code and dataset have been made available publicly.
An Intelligent Safety System for Human-Centered Semi-Autonomous Vehicles
Feb 20, 2019

Nowadays, automobile manufacturers make efforts to develop ways to make cars fully safe. Monitoring driver's actions by computer vision techniques to detect driving mistakes in real-time and then planning for autonomous driving to avoid vehicle collisions is one of the most important issues that has been investigated in the machine vision and Intelligent Transportation Systems (ITS). The main goal of this study is to prevent accidents caused by fatigue, drowsiness, and driver distraction. To avoid these incidents, this paper proposes an integrated safety system that continuously monitors the driver's attention and vehicle surroundings, and finally decides whether the actual steering control status is safe or not. For this purpose, we equipped an ordinary car called FARAZ with a vision system consisting of four mounted cameras along with a universal car tool for communicating with surrounding factory-installed sensors and other car systems, and sending commands to actuators. The proposed system leverages a scene understanding pipeline using deep convolutional encoder-decoder networks and a driver state detection pipeline. We have been identifying and assessing domestic capabilities for the development of technologies specifically of the ordinary vehicles in order to manufacture smart cars and eke providing an intelligent system to increase safety and to assist the driver in various conditions/situations.
Extracting an English-Persian Parallel Corpus from Comparable Corpora
Jul 31, 2018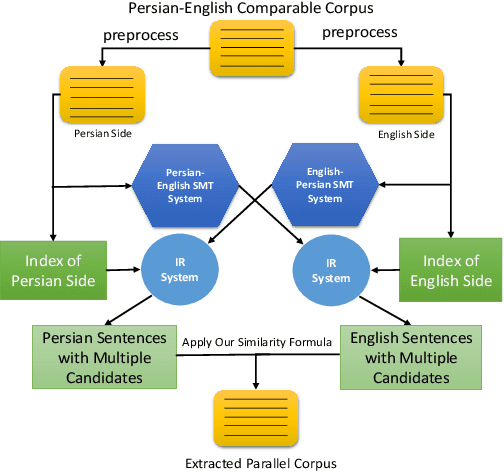
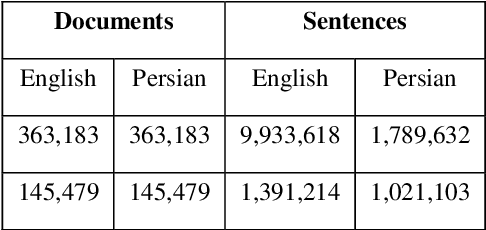
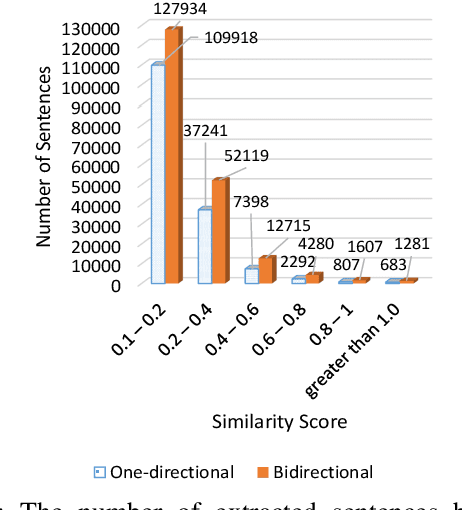
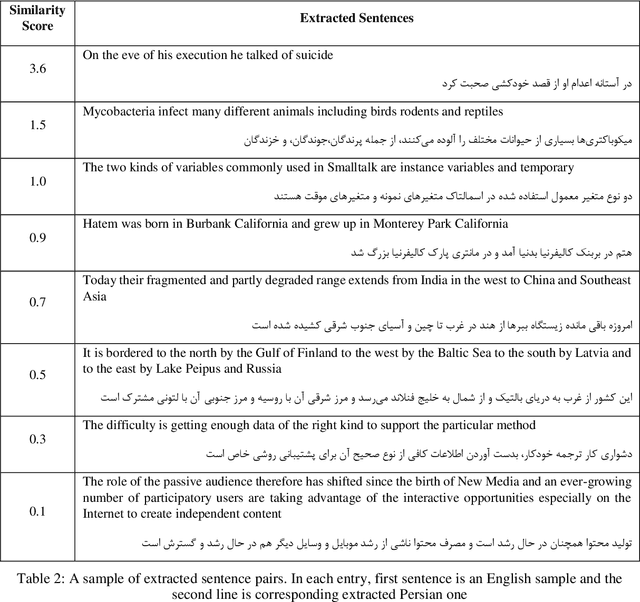
Parallel data are an important part of a reliable Statistical Machine Translation (SMT) system. The more of these data are available, the better the quality of the SMT system. However, for some language pairs such as Persian-English, parallel sources of this kind are scarce. In this paper, a bidirectional method is proposed to extract parallel sentences from English and Persian document aligned Wikipedia. Two machine translation systems are employed to translate from Persian to English and the reverse after which an IR system is used to measure the similarity of the translated sentences. Adding the extracted sentences to the training data of the existing SMT systems is shown to improve the quality of the translation. Furthermore, the proposed method slightly outperforms the one-directional approach. The extracted corpus consists of about 200,000 sentences which have been sorted by their degree of similarity calculated by the IR system and is freely available for public access on the Web.
Extracting Bilingual Persian Italian Lexicon from Comparable Corpora Using Different Types of Seed Dictionaries
Jan 29, 2017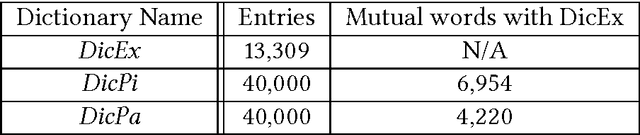
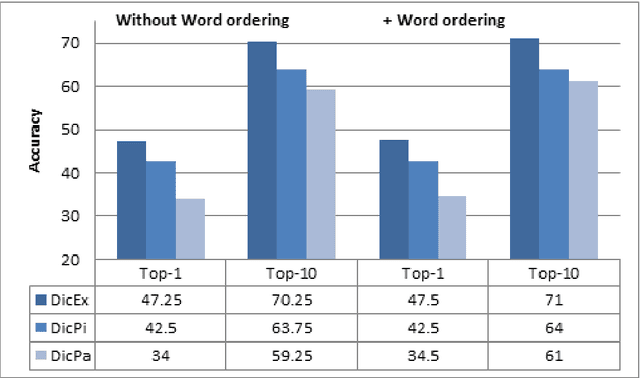
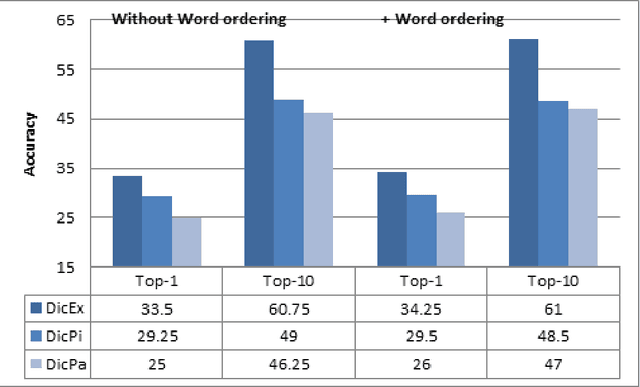
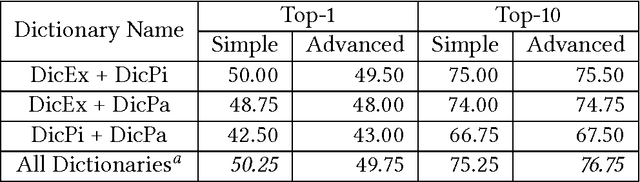
Bilingual dictionaries are very important in various fields of natural language processing. In recent years, research on extracting new bilingual lexicons from non-parallel (comparable) corpora have been proposed. Almost all use a small existing dictionary or other resource to make an initial list called the "seed dictionary". In this paper we discuss the use of different types of dictionaries as the initial starting list for creating a bilingual Persian-Italian lexicon from a comparable corpus. Our experiments apply state-of-the-art techniques on three different seed dictionaries; an existing dictionary, a dictionary created with pivot-based schema, and a dictionary extracted from a small Persian-Italian parallel text. The interesting challenge of our approach is to find a way to combine different dictionaries together in order to produce a better and more accurate lexicon. In order to combine seed dictionaries, we propose two different combination models and examine the effect of our novel combination models on various comparable corpora that have differing degrees of comparability. We conclude with a proposal for a new weighting system to improve the extracted lexicon. The experimental results produced by our implementation show the efficiency of our proposed models.
Using English as Pivot to Extract Persian-Italian Parallel Sentences from Non-Parallel Corpora
Jan 29, 2017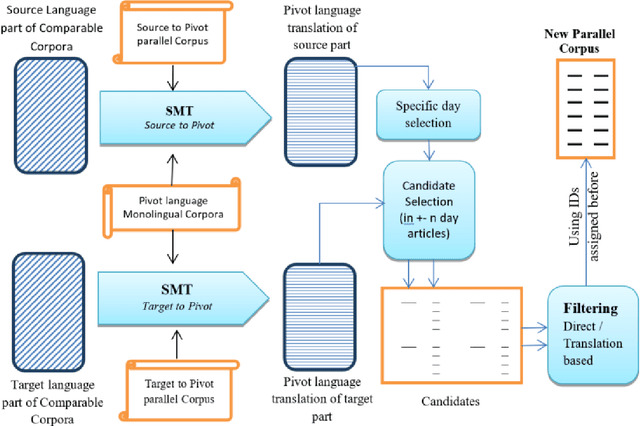


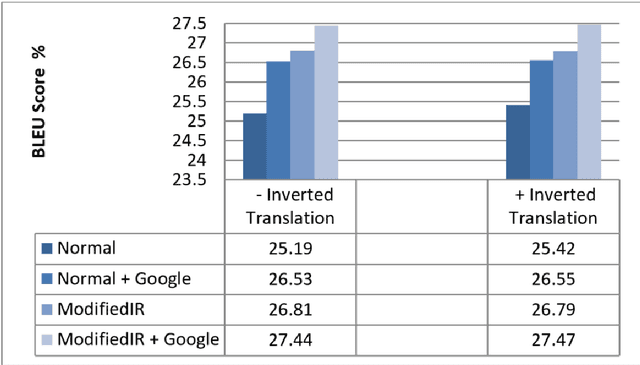
The effectiveness of a statistical machine translation system (SMT) is very dependent upon the amount of parallel corpus used in the training phase. For low-resource language pairs there are not enough parallel corpora to build an accurate SMT. In this paper, a novel approach is presented to extract bilingual Persian-Italian parallel sentences from a non-parallel (comparable) corpus. In this study, English is used as the pivot language to compute the matching scores between source and target sentences and candidate selection phase. Additionally, a new monolingual sentence similarity metric, Normalized Google Distance (NGD) is proposed to improve the matching process. Moreover, some extensions of the baseline system are applied to improve the quality of extracted sentences measured with BLEU. Experimental results show that using the new pivot based extraction can increase the quality of bilingual corpus significantly and consequently improves the performance of the Persian-Italian SMT system.