 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Patch-based Synthesis: GPU Implementation and Optimization
May 11, 2020This thesis surveys the research in patch-based synthesis and algorithms for finding correspondences between small local regions of images. We additionally explore a large kind of applications of this new fast randomized matching technique. One of the algorithms we have studied in particular is PatchMatch, can find similar regions or "patches" of an image one to two orders of magnitude faster than previous techniques. The algorithmic program is driven by applying mathematical properties of nearest neighbors in natural images. It is observed that neighboring correspondences tend to be similar or "coherent" and use this observation in algorithm in order to quickly converge to an approximate solution. The algorithm is the most general form can find k-nearest neighbor matching, using patches that translate, rotate, or scale, using arbitrary descriptors, and between two or more images. Speed-ups are obtained over various techniques in an exceeding range of those areas. We have explored many applications of PatchMatch matching algorithm. In computer graphics, we have explored removing unwanted objects from images, seamlessly moving objects in images, changing image aspect ratios, and video summarization. In computer vision we have explored denoising images, object detection, detecting image forgeries, and detecting symmetries. We conclude by discussing the restrictions of our algorithmic program, GPU implementation and areas for future analysis.
LSCP: Enhanced Large Scale Colloquial Persian Language Understanding
Mar 13, 2020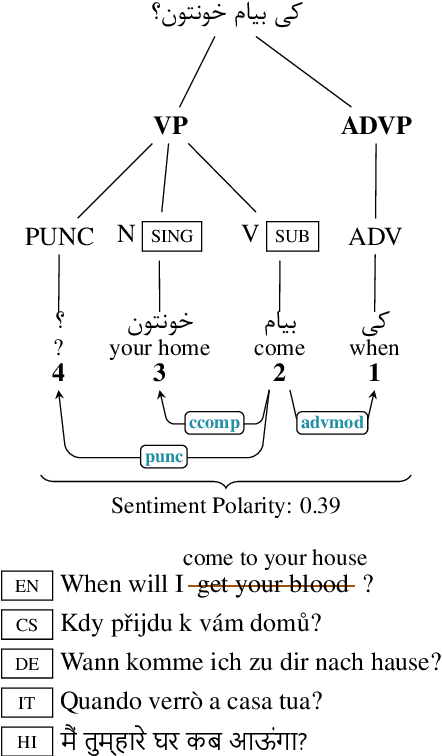

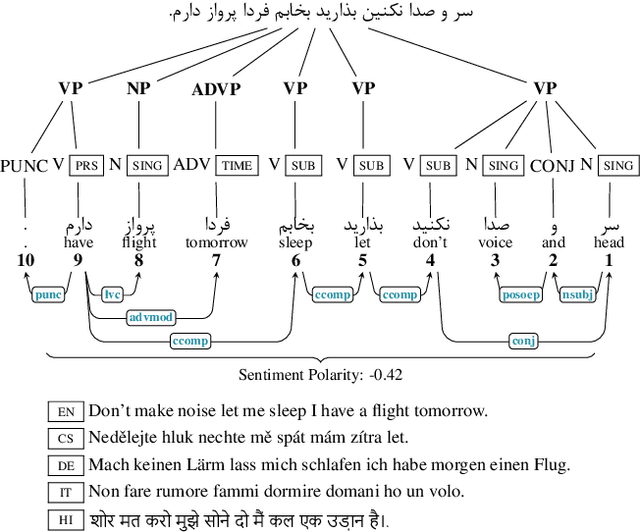
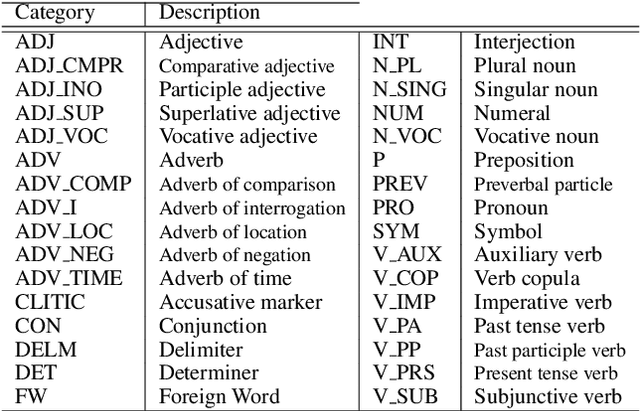
Language recognition has been significantly advanced in recent years by means of modern machine learning methods such as deep learning and benchmarks with rich annotations. However, research is still limited in low-resource formal languages. This consists of a significant gap in describing the colloquial language especially for low-resourced ones such as Persian. In order to target this gap for low resource languages, we propose a "Large Scale Colloquial Persian Dataset" (LSCP). LSCP is hierarchically organized in a semantic taxonomy that focuses on multi-task informal Persian language understanding as a comprehensive problem. This encompasses the recognition of multiple semantic aspects in the human-level sentences, which naturally captures from the real-world sentences. We believe that further investigations and processing, as well as the application of novel algorithms and methods, can strengthen enriching computerized understanding and processing of low resource languages. The proposed corpus consists of 120M sentences resulted from 27M tweets annotated with parsing tree, part-of-speech tags, sentiment polarity and translation in five different languages.
Deep Multimodal Image-Text Embeddings for Automatic Cross-Media Retrieval
Feb 23, 2020
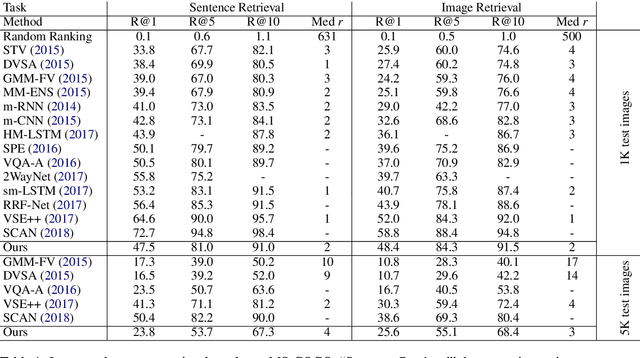
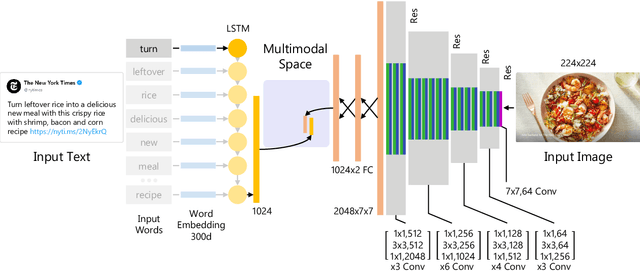
This paper considers the task of matching images and sentences by learning a visual-textual embedding space for cross-modal retrieval. Finding such a space is a challenging task since the features and representations of text and image are not comparable. In this work, we introduce an end-to-end deep multimodal convolutional-recurrent network for learning both vision and language representations simultaneously to infer image-text similarity. The model learns which pairs are a match (positive) and which ones are a mismatch (negative) using a hinge-based triplet ranking. To learn about the joint representations, we leverage our newly extracted collection of tweets from Twitter. The main characteristic of our dataset is that the images and tweets are not standardized the same as the benchmarks. Furthermore, there can be a higher semantic correlation between the pictures and tweets contrary to benchmarks in which the descriptions are well-organized. Experimental results on MS-COCO benchmark dataset show that our model outperforms certain methods presented previously and has competitive performance compared to the state-of-the-art. The code and dataset have been made available publicly.
An Intelligent Safety System for Human-Centered Semi-Autonomous Vehicles
Feb 20, 2019

Nowadays, automobile manufacturers make efforts to develop ways to make cars fully safe. Monitoring driver's actions by computer vision techniques to detect driving mistakes in real-time and then planning for autonomous driving to avoid vehicle collisions is one of the most important issues that has been investigated in the machine vision and Intelligent Transportation Systems (ITS). The main goal of this study is to prevent accidents caused by fatigue, drowsiness, and driver distraction. To avoid these incidents, this paper proposes an integrated safety system that continuously monitors the driver's attention and vehicle surroundings, and finally decides whether the actual steering control status is safe or not. For this purpose, we equipped an ordinary car called FARAZ with a vision system consisting of four mounted cameras along with a universal car tool for communicating with surrounding factory-installed sensors and other car systems, and sending commands to actuators. The proposed system leverages a scene understanding pipeline using deep convolutional encoder-decoder networks and a driver state detection pipeline. We have been identifying and assessing domestic capabilities for the development of technologies specifically of the ordinary vehicles in order to manufacture smart cars and eke providing an intelligent system to increase safety and to assist the driver in various conditions/situations.