 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLA-SGCN: Protein-Ligand Binding Affinity Prediction by Integrating Similar Pairs and Semi-supervised Graph Convolutional Network
May 13, 2024The protein-ligand binding affinity (PLA) prediction goal is to predict whether or not the ligand could bind to a protein sequence. Recently, in PLA prediction, deep learning has received much attention. Two steps are involved in deep learning-based approaches: feature extraction and task prediction step. Many deep learning-based approaches concentrate on introducing new feature extraction networks or integrating auxiliary knowledge like protein-protein interaction networks or gene ontology knowledge. Then, a task prediction network is designed simply using some fully connected layers. This paper aims to integrate retrieved similar hard protein-ligand pairs in PLA prediction (i.e., task prediction step) using a semi-supervised graph convolutional network (GCN). Hard protein-ligand pairs are retrieved for each input query sample based on the manifold smoothness constraint. Then, a graph is learned automatically in which each node is a protein-ligand pair, and each edge represents the similarity between pairs. In other words, an end-to-end framework is proposed that simultaneously retrieves hard similar samples, learns protein-ligand descriptor, learns the graph topology of the input sample with retrieved similar hard samples (learn adjacency matrix), and learns a semi-supervised GCN to predict the binding affinity (as task predictor). The training step adjusts the parameter values, and in the inference step, the learned model is fine-tuned for each input sample. To evaluate the proposed approach, it is applied to the four well-known PDBbind, Davis, KIBA, and BindingDB datasets. The results show that the proposed method significantly performs better than the comparable approaches.
Connective Reconstruction-based Novelty Detection
Oct 25, 2022



Detection of out-of-distribution samples is one of the critical tasks for real-world applications of computer vision. The advancement of deep learning has enabled us to analyze real-world data which contain unexplained samples, accentuating the need to detect out-of-distribution instances more than before. GAN-based approaches have been widely used to address this problem due to their ability to perform distribution fitting; however, they are accompanied by training instability and mode collapse. We propose a simple yet efficient reconstruction-based method that avoids adding complexities to compensate for the limitations of GAN models while outperforming them. Unlike previous reconstruction-based works that only utilize reconstruction error or generated samples, our proposed method simultaneously incorporates both of them in the detection task. Our model, which we call "Connective Novelty Detection" has two subnetworks, an autoencoder, and a binary classifier. The autoencoder learns the representation of the positive class by reconstructing them. Then, the model creates negative and connected positive examples using real and generated samples. Negative instances are generated via manipulating the real data, so their distribution is close to the positive class to achieve a more accurate boundary for the classifier. To boost the robustness of the detection to reconstruction error, connected positive samples are created by combining the real and generated samples. Finally, the binary classifier is trained using connected positive and negative examples. We demonstrate a considerable improvement in novelty detection over state-of-the-art methods on MNIST and Caltech-256 datasets.
Deep Multimodal Image-Text Embeddings for Automatic Cross-Media Retrieval
Feb 23, 2020
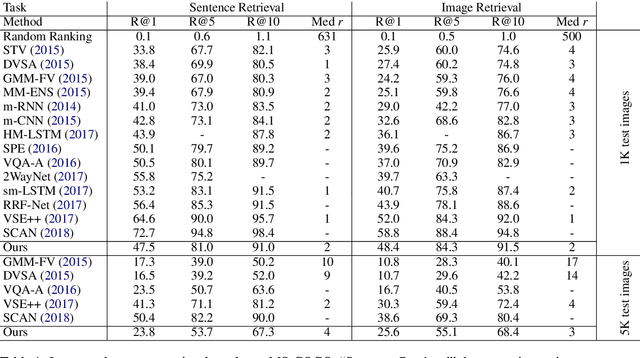
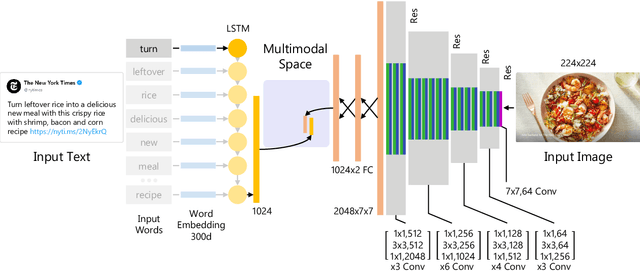
This paper considers the task of matching images and sentences by learning a visual-textual embedding space for cross-modal retrieval. Finding such a space is a challenging task since the features and representations of text and image are not comparable. In this work, we introduce an end-to-end deep multimodal convolutional-recurrent network for learning both vision and language representations simultaneously to infer image-text similarity. The model learns which pairs are a match (positive) and which ones are a mismatch (negative) using a hinge-based triplet ranking. To learn about the joint representations, we leverage our newly extracted collection of tweets from Twitter. The main characteristic of our dataset is that the images and tweets are not standardized the same as the benchmarks. Furthermore, there can be a higher semantic correlation between the pictures and tweets contrary to benchmarks in which the descriptions are well-organized. Experimental results on MS-COCO benchmark dataset show that our model outperforms certain methods presented previously and has competitive performance compared to the state-of-the-art. The code and dataset have been made available publicly.
An Intelligent Safety System for Human-Centered Semi-Autonomous Vehicles
Feb 20, 2019

Nowadays, automobile manufacturers make efforts to develop ways to make cars fully safe. Monitoring driver's actions by computer vision techniques to detect driving mistakes in real-time and then planning for autonomous driving to avoid vehicle collisions is one of the most important issues that has been investigated in the machine vision and Intelligent Transportation Systems (ITS). The main goal of this study is to prevent accidents caused by fatigue, drowsiness, and driver distraction. To avoid these incidents, this paper proposes an integrated safety system that continuously monitors the driver's attention and vehicle surroundings, and finally decides whether the actual steering control status is safe or not. For this purpose, we equipped an ordinary car called FARAZ with a vision system consisting of four mounted cameras along with a universal car tool for communicating with surrounding factory-installed sensors and other car systems, and sending commands to actuators. The proposed system leverages a scene understanding pipeline using deep convolutional encoder-decoder networks and a driver state detection pipeline. We have been identifying and assessing domestic capabilities for the development of technologies specifically of the ordinary vehicles in order to manufacture smart cars and eke providing an intelligent system to increase safety and to assist the driver in various conditions/situations.
Self-Taught Support Vector Machine
Oct 12, 2017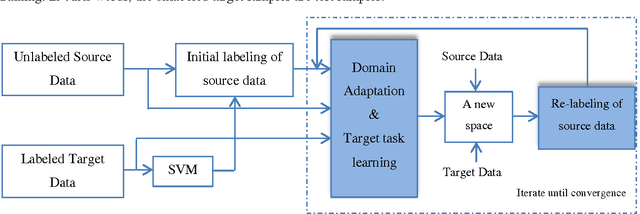
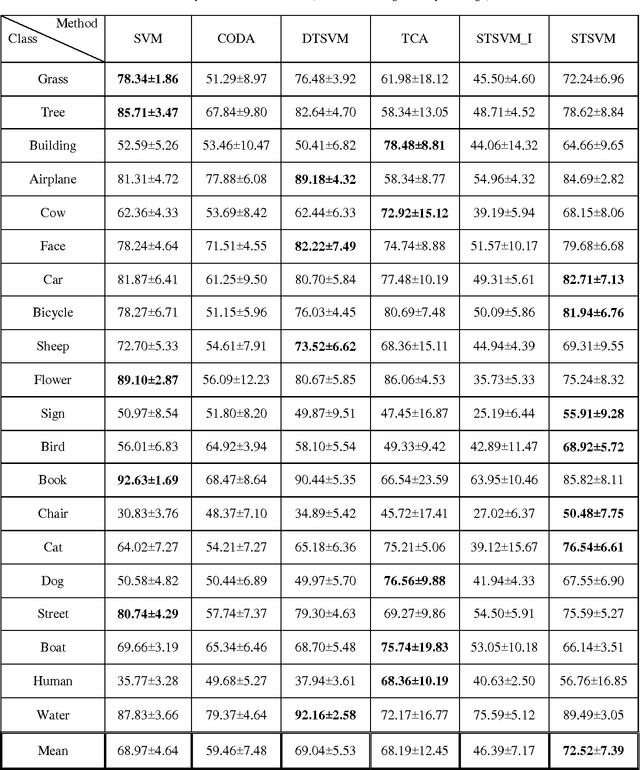
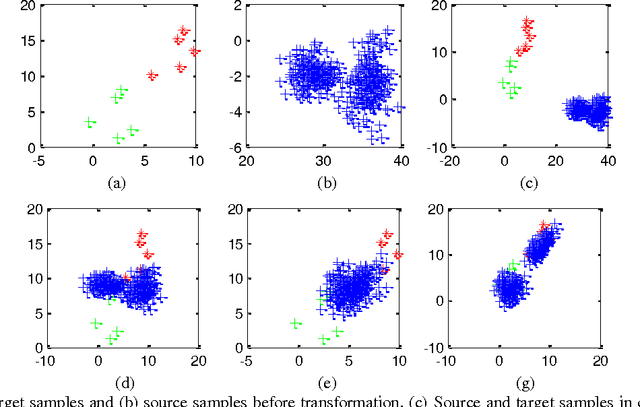
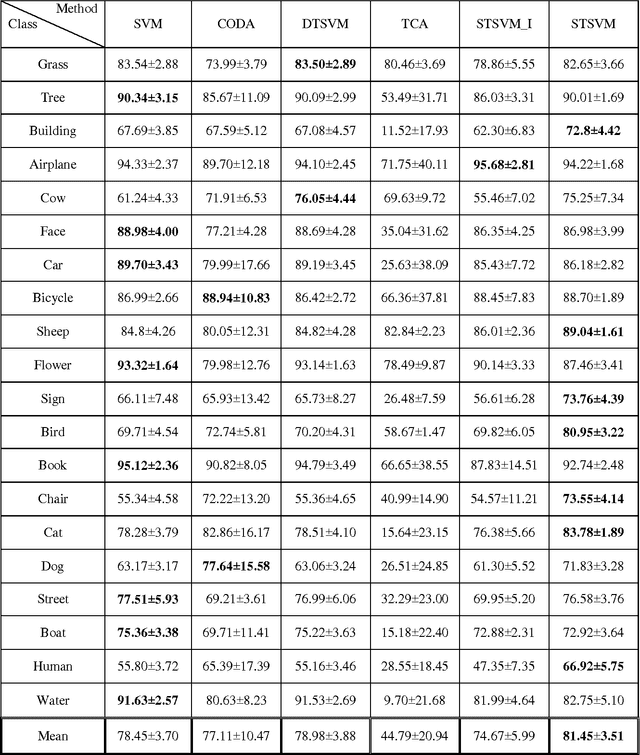
In this paper, a new approach for classification of target task using limited labeled target data as well as enormous unlabeled source data is proposed which is called self-taught learning. The target and source data can be drawn from different distributions. In the previous approaches, covariate shift assumption is considered where the marginal distributions p(x) change over domains and the conditional distributions p(y|x) remain the same. In our approach, we propose a new objective function which simultaneously learns a common space T(.) where the conditional distributions over domains p(T(x)|y) remain the same and learns robust SVM classifiers for target task using both source and target data in the new representation. Hence, in the proposed objective function, the hidden label of the source data is also incorporated. We applied the proposed approach on Caltech-256, MSRC+LMO datasets and compared the performance of our algorithm to the available competing methods. Our method has a superior performance to the successful existing algorithms.