 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Taught Support Vector Machine
Paper and Code
Oct 12, 2017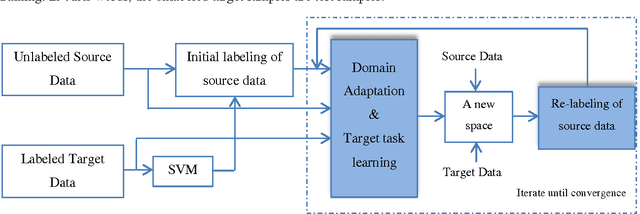
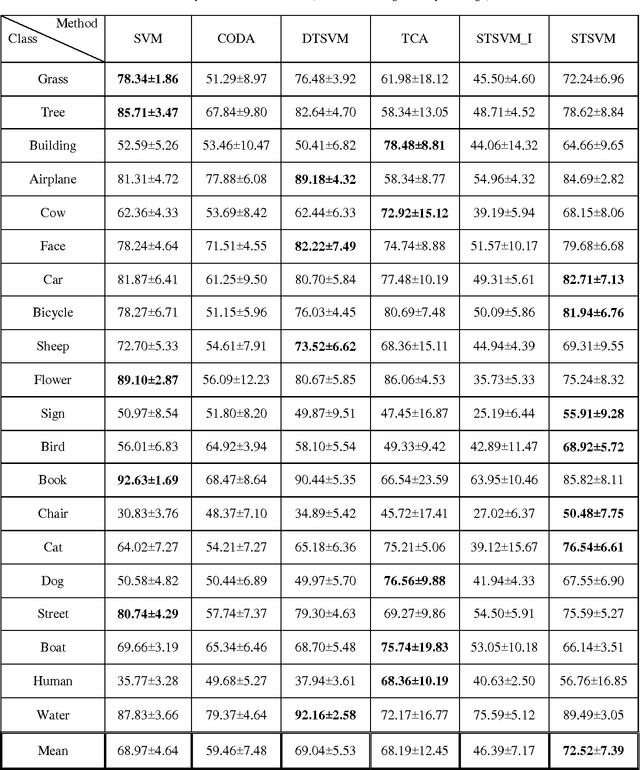
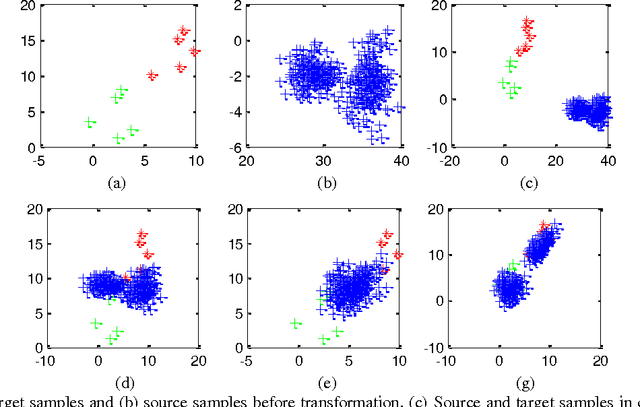
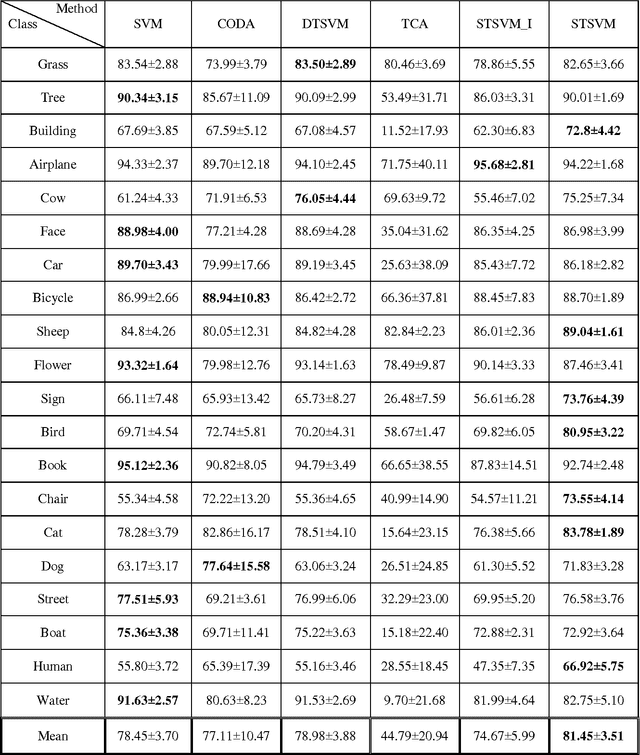
In this paper, a new approach for classification of target task using limited labeled target data as well as enormous unlabeled source data is proposed which is called self-taught learning. The target and source data can be drawn from different distributions. In the previous approaches, covariate shift assumption is considered where the marginal distributions p(x) change over domains and the conditional distributions p(y|x) remain the same. In our approach, we propose a new objective function which simultaneously learns a common space T(.) where the conditional distributions over domains p(T(x)|y) remain the same and learns robust SVM classifiers for target task using both source and target data in the new representation. Hence, in the proposed objective function, the hidden label of the source data is also incorporated. We applied the proposed approach on Caltech-256, MSRC+LMO datasets and compared the performance of our algorithm to the available competing methods. Our method has a superior performance to the successful existing algorithms.