 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Integrated Platform for Big Data Analysis
Apr 27, 2020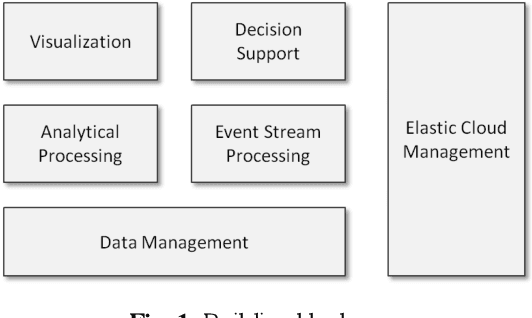
The amount of data in the world is expanding rapidly. Every day, huge amounts of data are created by scientific experiments, companies, and end users' activities. These large data sets have been labeled as "Big Data", and their storage, processing and analysis presents a plethora of new challenges to computer science researchers and IT professionals. In addition to efficient data management, additional complexity arises from dealing with semi-structured or unstructured data, and from time critical processing requirements. In order to understand these massive amounts of data, advanced visualization and data exploration techniques are required. Innovative approaches to these challenges have been developed during recent years, and continue to be a hot topic for re-search and industry in the future. An investigation of current approaches reveals that usually only one or two aspects are ad-dressed, either in the data management, processing, analysis or visualization. This paper presents the vision of an integrated plat-form for big data analysis that combines all these aspects. Main benefits of this approach are an enhanced scalability of the whole platform, a better parameterization of algorithms, a more efficient usage of system resources, and an improved usability during the end-to-end data analysis process.
LSCP: Enhanced Large Scale Colloquial Persian Language Understanding
Mar 13, 2020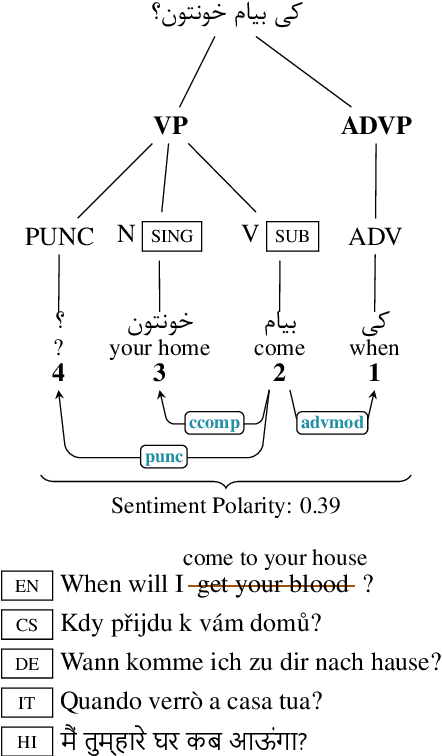

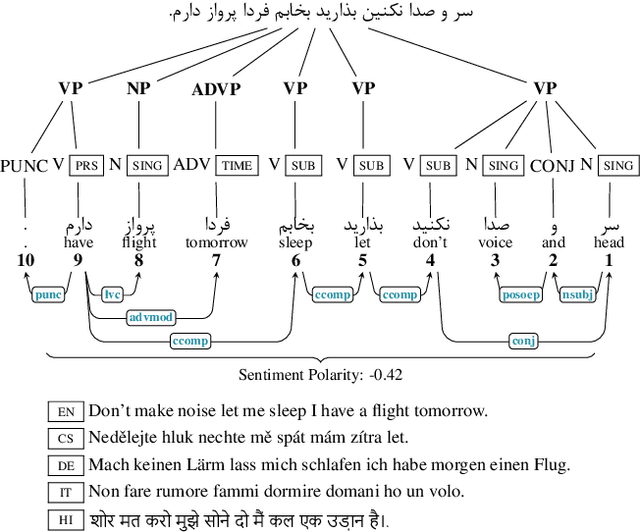
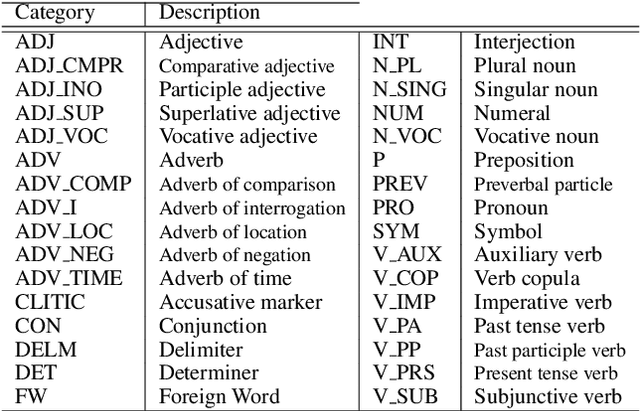
Language recognition has been significantly advanced in recent years by means of modern machine learning methods such as deep learning and benchmarks with rich annotations. However, research is still limited in low-resource formal languages. This consists of a significant gap in describing the colloquial language especially for low-resourced ones such as Persian. In order to target this gap for low resource languages, we propose a "Large Scale Colloquial Persian Dataset" (LSCP). LSCP is hierarchically organized in a semantic taxonomy that focuses on multi-task informal Persian language understanding as a comprehensive problem. This encompasses the recognition of multiple semantic aspects in the human-level sentences, which naturally captures from the real-world sentences. We believe that further investigations and processing, as well as the application of novel algorithms and methods, can strengthen enriching computerized understanding and processing of low resource languages. The proposed corpus consists of 120M sentences resulted from 27M tweets annotated with parsing tree, part-of-speech tags, sentiment polarity and translation in five different languages.
Detection of Thin Boundaries between Different Types of Anomalies in Outlier Detection using Enhanced Neural Networks
Jan 24, 2020



Outlier detection has received special attention in various fields, mainly for those dealing with machine learning and artificial intelligence. As strong outliers, anomalies are divided into the point, contextual and collective outliers. The most important challenges in outlier detection include the thin boundary between the remote points and natural area, the tendency of new data and noise to mimic the real data, unlabelled datasets and different definitions for outliers in different applications. Considering the stated challenges, we defined new types of anomalies called Collective Normal Anomaly and Collective Point Anomaly in order to improve a much better detection of the thin boundary between different types of anomalies. Basic domain-independent methods are introduced to detect these defined anomalies in both unsupervised and supervised datasets. The Multi-Layer Perceptron Neural Network is enhanced using the Genetic Algorithm to detect newly defined anomalies with higher precision so as to ensure a test error less than that calculated for the conventional Multi-Layer Perceptron Neural Network. Experimental results on benchmark datasets indicated reduced error of anomaly detection process in comparison to baselines.
Competence Assessment as an Expert System for Human Resource Management: A Mathematical Approach
Jan 16, 2020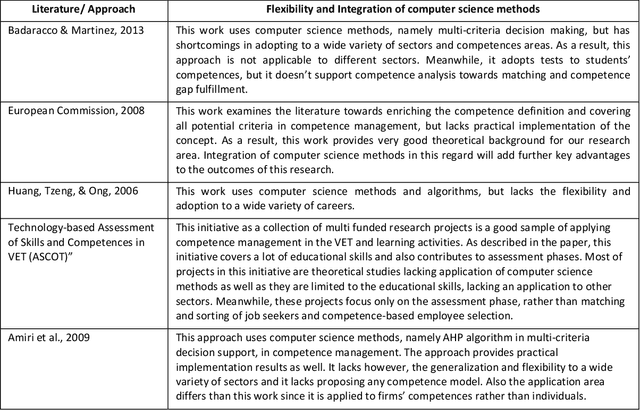
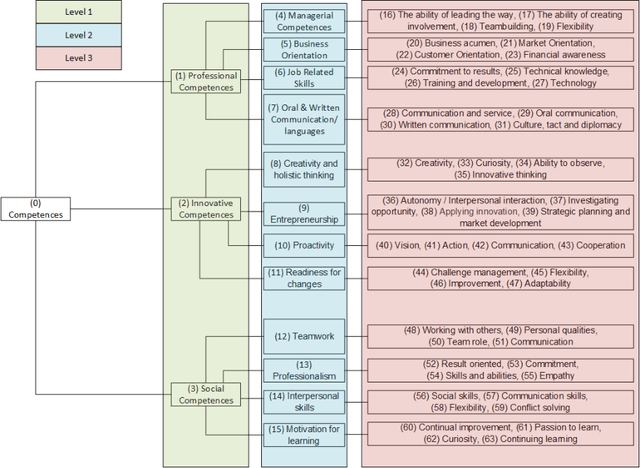
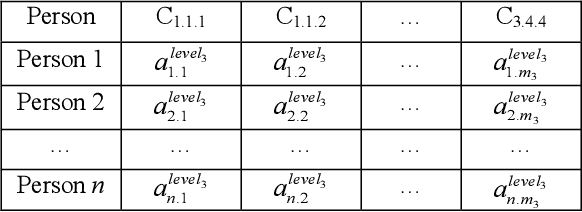
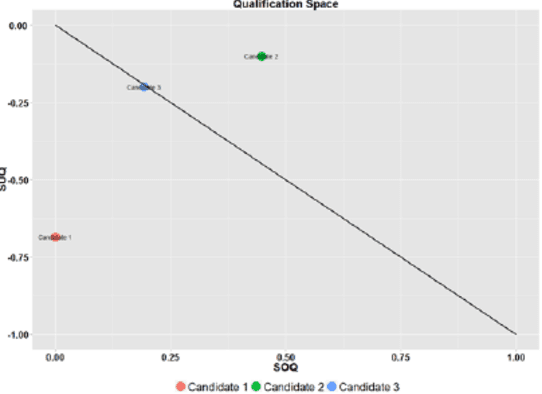
Efficient human resource management needs accurate assessment and representation of available competences as well as effective mapping of required competences for specific jobs and positions. In this regard, appropriate definition and identification of competence gaps express differences between acquired and required competences. Using a detailed quantification scheme together with a mathematical approach is a way to support accurate competence analytics, which can be applied in a wide variety of sectors and fields. This article describes the combined use of software technologies and mathematical and statistical methods for assessing and analyzing competences in human resource information systems. Based on a standard competence model, which is called a Professional, Innovative and Social competence tree, the proposed framework offers flexible tools to experts in real enterprise environments, either for evaluation of employees towards an optimal job assignment and vocational training or for recruitment processes. The system has been tested with real human resource data sets in the frame of the European project called ComProFITS.
Knowledge Discovery from Social Media using Big Data provided Sentiment Analysis (SoMABiT)
Jan 16, 2020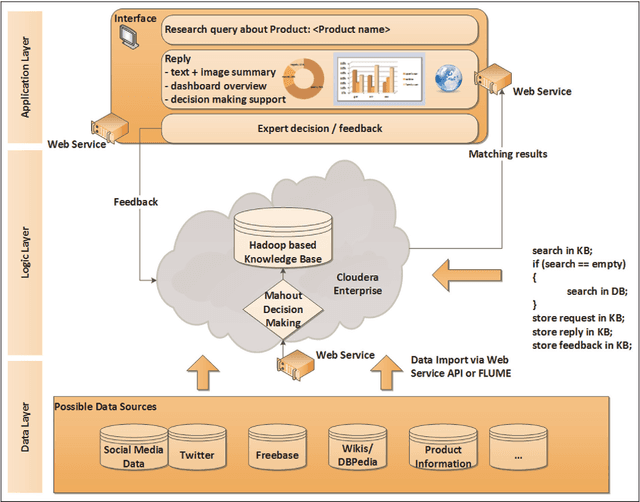

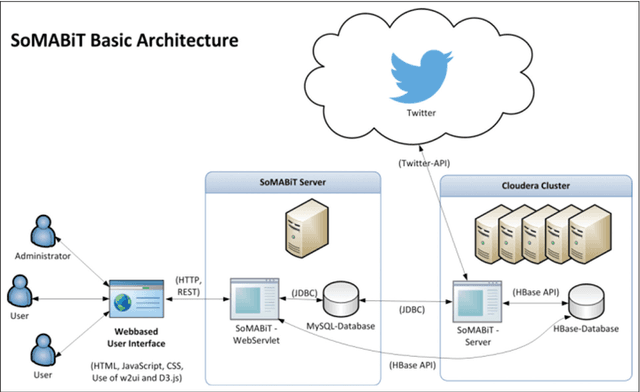
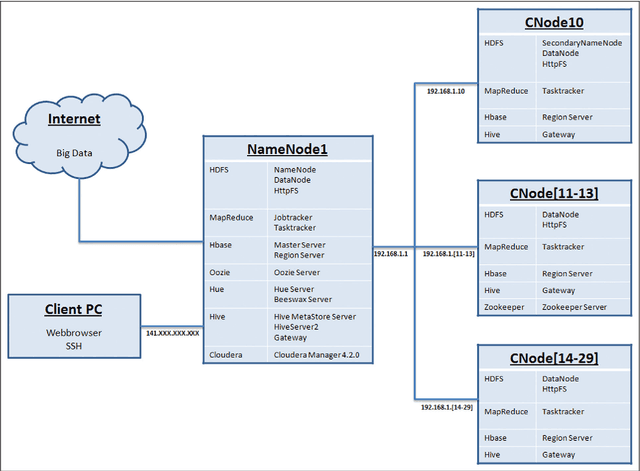
In todays competitive business world, being aware of customer needs and market-oriented production is a key success factor for industries. To this aim, the use of efficient analytic algorithms ensures a better understanding of customer feedback and improves the next generation of products. Accordingly, the dramatic increase in using social media in daily life provides beneficial sources for market analytics. But how traditional analytic algorithms and methods can scale up for such disparate and multi-structured data sources is the main challenge in this regard. This paper presents and discusses the technological and scientific focus of the SoMABiT as a social media analysis platform using big data technology. Sentiment analysis has been employed in order to discover knowledge from social media. The use of MapReduce and developing a distributed algorithm towards an integrated platform that can scale for any data volume and provide a social media-driven knowledge is the main novelty of the proposed concept in comparison to the state-of-the-art technologies.
Knowledge Integration of Collaborative Product Design Using Cloud Computing Infrastructure
Jan 16, 2020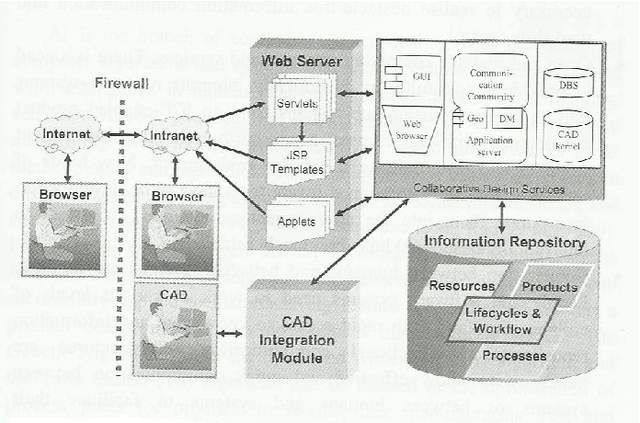
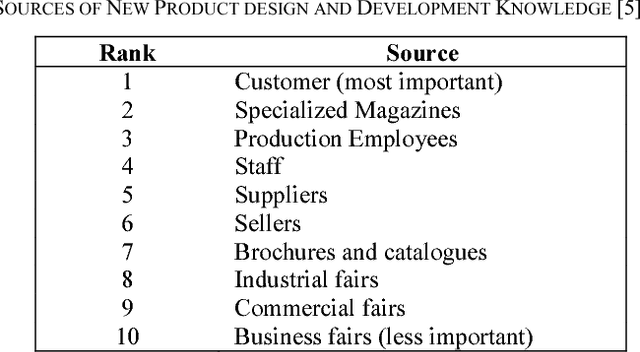
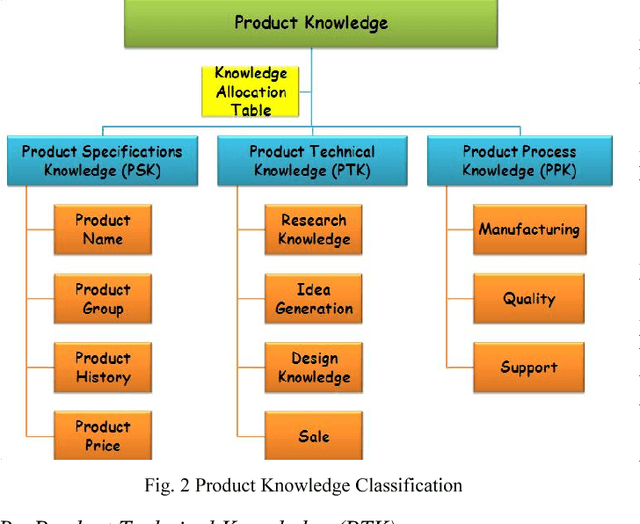
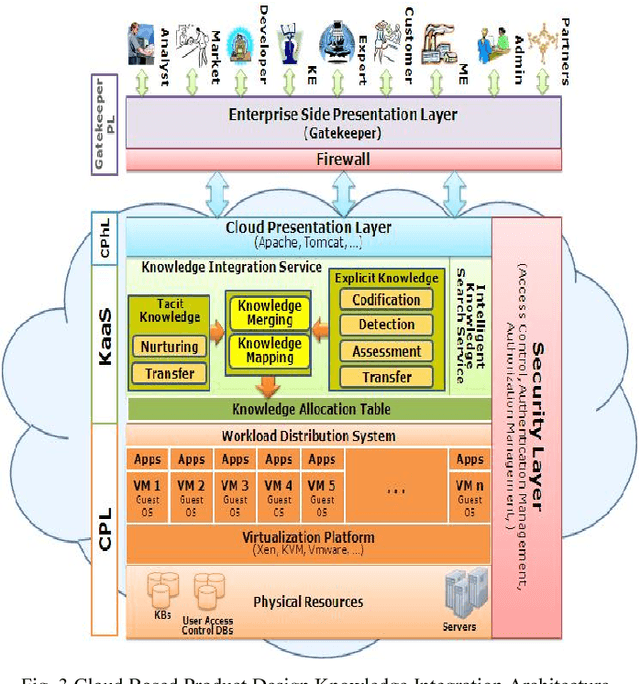
The pivotal key to the success of manufacturing enterprises is a sustainable and innovative product design and development. In collaborative design, stakeholders are heterogeneously distributed chain-like. Due to the growing volume of data and knowledge, effective management of the knowledge acquired in the product design and development is one of the key challenges facing most manufacturing enterprises. Opportunities for improving efficiency and performance of IT-based product design applications through centralization of resources such as knowledge and computation have increased in the last few years with the maturation of technologies such as SOA, virtualization, grid computing, and/or cloud computing. The main focus of this paper is the concept of ongoing research in providing the knowledge integration service for collaborative product design and development using cloud computing infrastructure. Potentials of the cloud computing to support the Knowledge integration functionalities as a Service by providing functionalities such as knowledge mapping, merging, searching, and transferring in product design procedure are described in this paper. Proposed knowledge integration services support users by giving real-time access to knowledge resources. The framework has the advantage of availability, efficiency, cost reduction, less time to result, and scalability.
Practical Approach of Knowledge Management in Medical Science
Jan 16, 2020
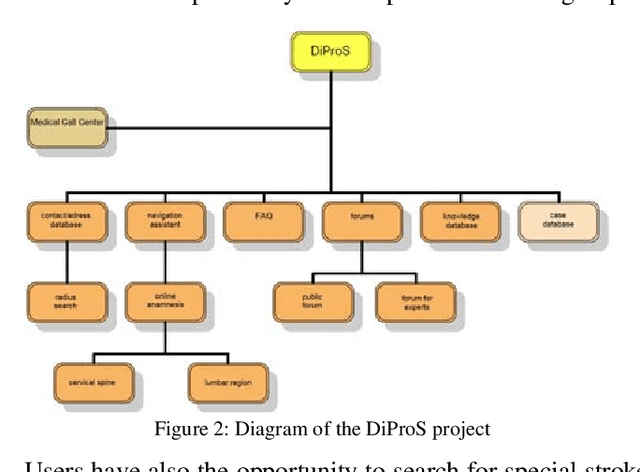
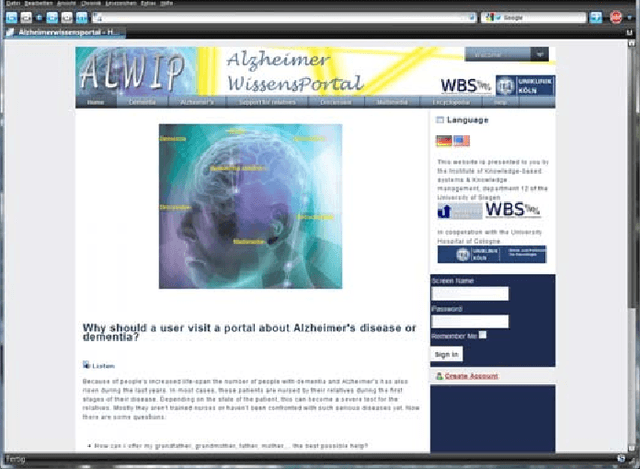
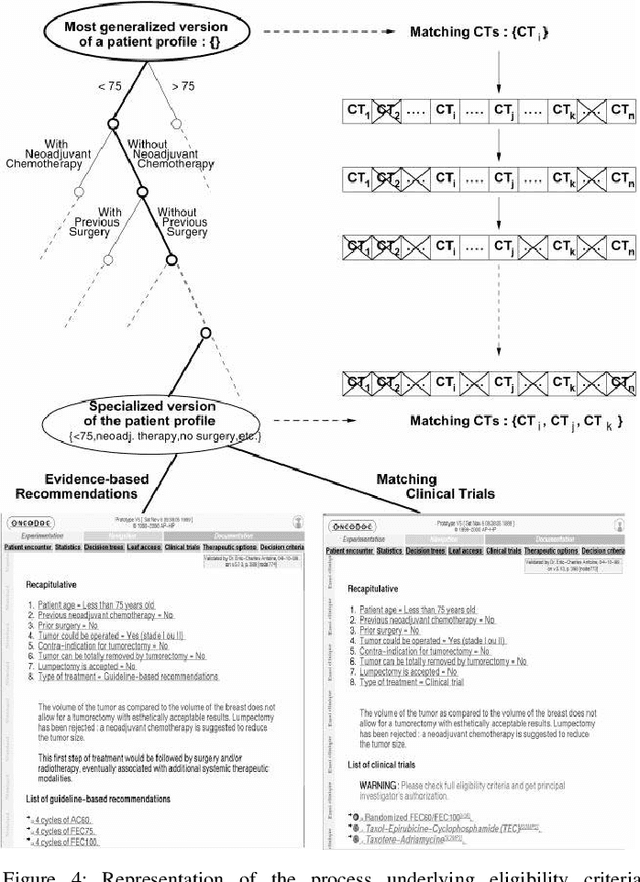
Knowledge organization, infrastructure, and knowledge-based activities are all subjects that help in the creation of business strategies for the new enterprise. In this paper, the first basics of knowledge-based systems are studied. Practical issues and challenges of Knowledge Management (KM) implementations are then illustrated. Finally, a comparison of different knowledge-based projects is presented along with abstracted information on their implementation, techniques, and results. Most of these projects are in the field of medical science. Based on our study and evaluation of different KM projects, we conclude that KM is being used in every science, industry, and business. But its importance in medical science and assisted living projects are highlighted nowadays with the most of research institutes. Most medical centers are interested in using knowledge-based services like portals and learning techniques of knowledge for their future innovations and supports.