 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Integrated Platform for Big Data Analysis
Apr 27, 2020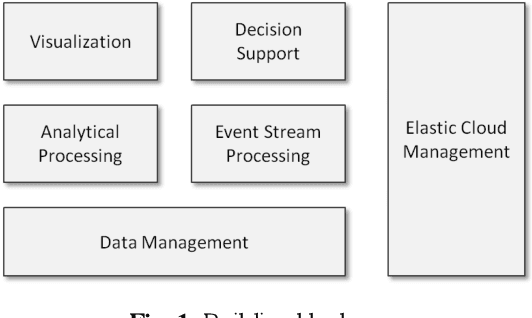
The amount of data in the world is expanding rapidly. Every day, huge amounts of data are created by scientific experiments, companies, and end users' activities. These large data sets have been labeled as "Big Data", and their storage, processing and analysis presents a plethora of new challenges to computer science researchers and IT professionals. In addition to efficient data management, additional complexity arises from dealing with semi-structured or unstructured data, and from time critical processing requirements. In order to understand these massive amounts of data, advanced visualization and data exploration techniques are required. Innovative approaches to these challenges have been developed during recent years, and continue to be a hot topic for re-search and industry in the future. An investigation of current approaches reveals that usually only one or two aspects are ad-dressed, either in the data management, processing, analysis or visualization. This paper presents the vision of an integrated plat-form for big data analysis that combines all these aspects. Main benefits of this approach are an enhanced scalability of the whole platform, a better parameterization of algorithms, a more efficient usage of system resources, and an improved usability during the end-to-end data analysis process.
Competence Assessment as an Expert System for Human Resource Management: A Mathematical Approach
Jan 16, 2020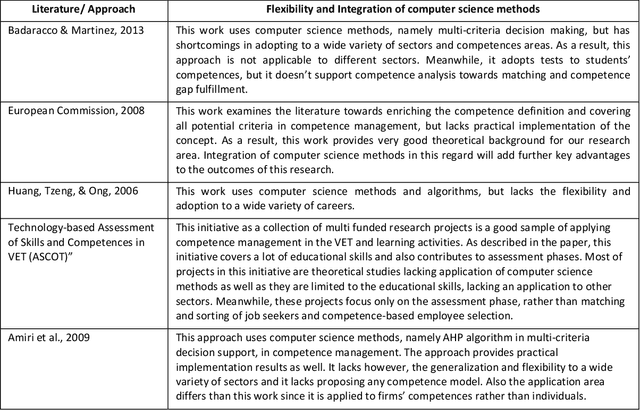
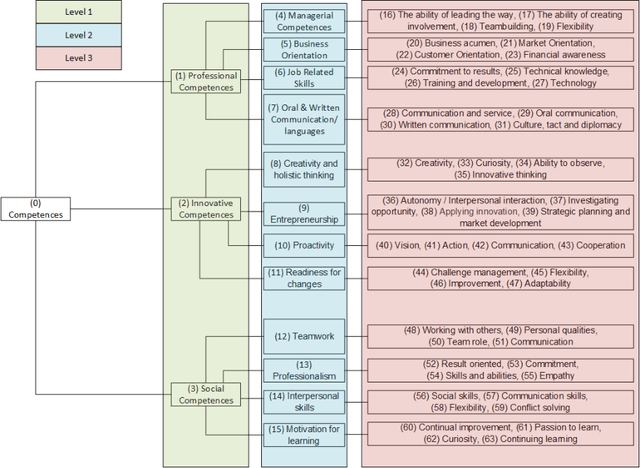
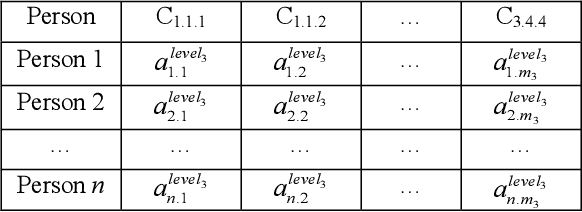
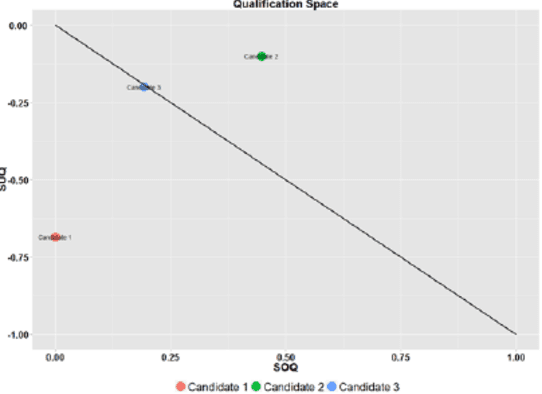
Efficient human resource management needs accurate assessment and representation of available competences as well as effective mapping of required competences for specific jobs and positions. In this regard, appropriate definition and identification of competence gaps express differences between acquired and required competences. Using a detailed quantification scheme together with a mathematical approach is a way to support accurate competence analytics, which can be applied in a wide variety of sectors and fields. This article describes the combined use of software technologies and mathematical and statistical methods for assessing and analyzing competences in human resource information systems. Based on a standard competence model, which is called a Professional, Innovative and Social competence tree, the proposed framework offers flexible tools to experts in real enterprise environments, either for evaluation of employees towards an optimal job assignment and vocational training or for recruitment processes. The system has been tested with real human resource data sets in the frame of the European project called ComProFITS.
Discovering patterns of correlation and similarities in software project data with the Circos visualization tool
Oct 06, 2011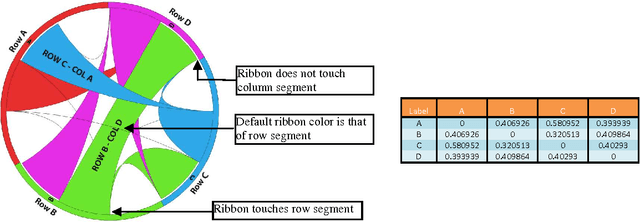
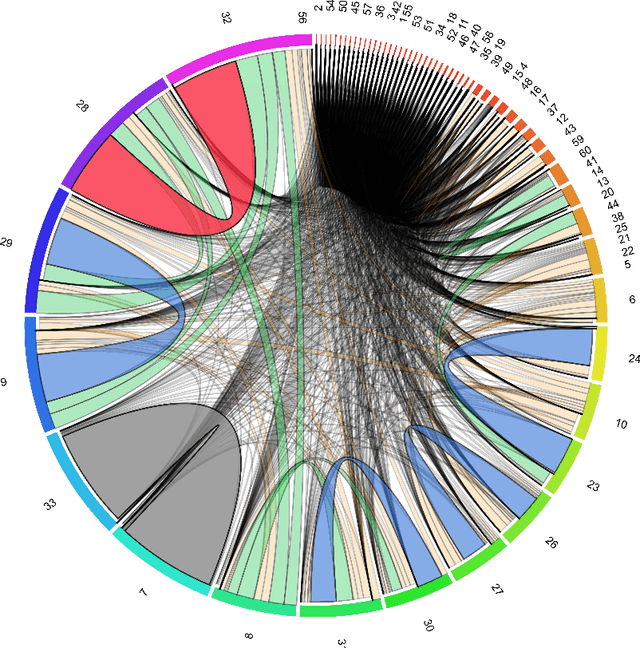
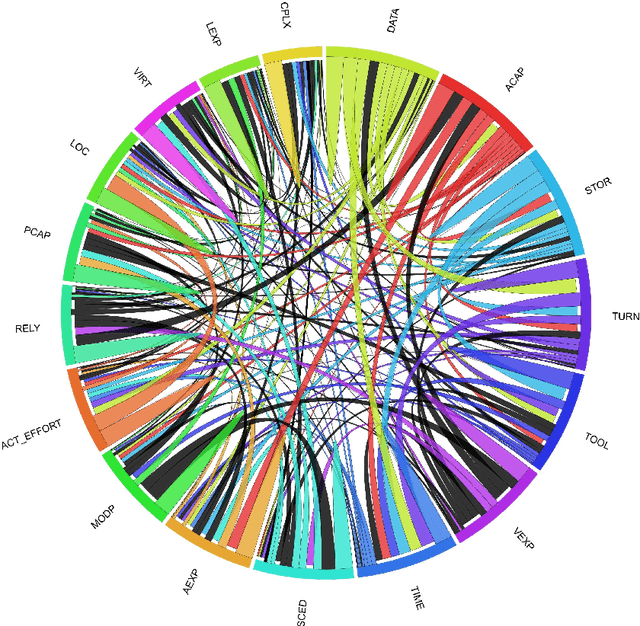
Software cost estimation based on multivariate data from completed projects requires the building of efficient models. These models essentially describe relations in the data, either on the basis of correlations between variables or of similarities between the projects. The continuous growth of the amount of data gathered and the need to perform preliminary analysis in order to discover patterns able to drive the building of reasonable models, leads the researchers towards intelligent and time-saving tools which can effectively describe data and their relationships. The goal of this paper is to suggest an innovative visualization tool, widely used in bioinformatics, which represents relations in data in an aesthetic and intelligent way. In order to illustrate the capabilities of the tool, we use a well known dataset from software engineering projects.
DD-EbA: An algorithm for determining the number of neighbors in cost estimation by analogy using distance distributions
Dec 28, 2010
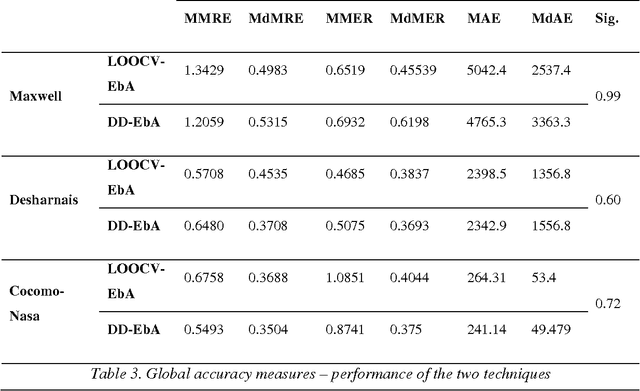
Case Based Reasoning and particularly Estimation by Analogy, has been used in a number of problem-solving areas, such as cost estimation. Conventional methods, despite the lack of a sound criterion for choosing nearest projects, were based on estimation using a fixed and predetermined number of neighbors from the entire set of historical instances. This approach puts boundaries to the estimation ability of such algorithms, for they do not take into consideration that every project under estimation is unique and requires different handling. The notion of distributions of distances together with a distance metric for distributions help us to adapt the proposed method (we call it DD-EbA) each time to a specific case that is to be estimated without loosing in prediction power or computational cost. The results of this paper show that the proposed technique achieves the above idea in a very efficient way.