 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Binary Pattern(LBP) Optimization for Feature Extraction
Jul 26, 2024



The rapid growth of image data has led to the development of advanced image processing and computer vision techniques, which are crucial in various applications such as image classification, image segmentation, and pattern recognition. Texture is an important feature that has been widely used in many image processing tasks. Therefore, analyzing and understanding texture plays a pivotal role in image analysis and understanding.Local binary pattern (LBP) is a powerful operator that describes the local texture features of images. This paper provides a novel mathematical representation of the LBP by separating the operator into three matrices, two of which are always fixed and do not depend on the input data. These fixed matrices are analyzed in depth, and a new algorithm is proposed to optimize them for improved classification performance. The optimization process is based on the singular value decomposition (SVD) algorithm. As a result, the authors present optimal LBPs that effectively describe the texture of human face images. Several experiment results presented in this paper convincingly verify the efficiency and superiority of the optimized LBPs for face detection and facial expression recognition tasks.
Minimum Constraint Removal Problem for Line Segments is NP-hard
Jul 07, 2021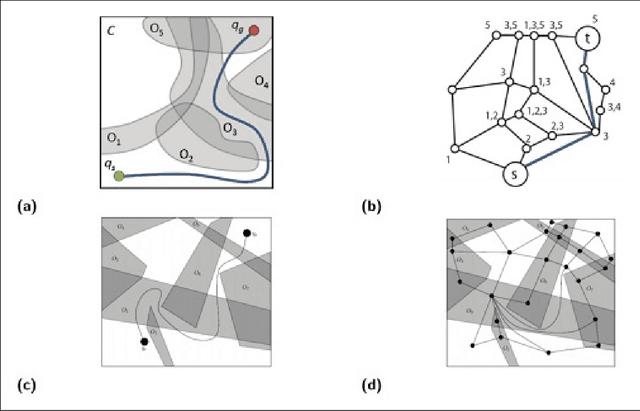
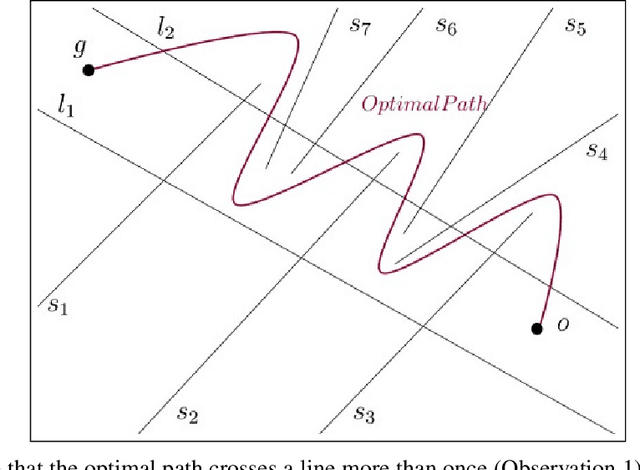
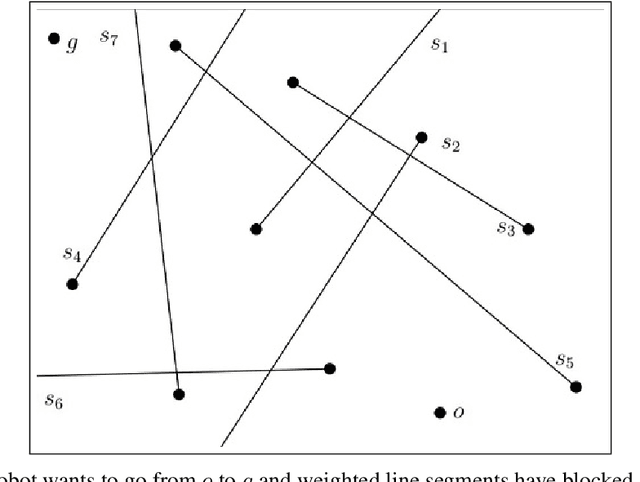
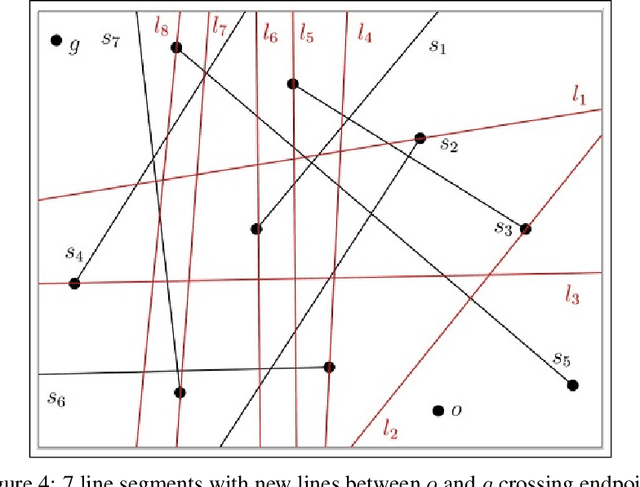
In the minimum constraint removal ($MCR$), there is no feasible path to move from the starting point towards the goal and, the minimum constraints should be removed in order to find a collision-free path. It has been proved that $MCR$ problem is $NP-hard$ when constraints have arbitrary shapes or even they are in shape of convex polygons. However, it has a simple linear solution when constraints are lines and the problem is open for other cases yet. In this paper, using a reduction from Subset Sum problem, in three steps, we show that the problem is NP-hard for both weighted and unweighted line segments.
A new metaheuristic approach for the art gallery problem
Jul 07, 2021

In the problem Localization and trilateration with minimum number of landmarks, we faced 3-guard and classic Art Gallery Problem. The goal of the art gallery problem is to find the minimum number of guards within a simple polygon to observe and protect the entire of it. It has many applications in Robotics, Telecommunication and so on and there are some approaches to handle the art gallery problem which is theoretically NP-hard. This paper offers an efficient method based on the Particle Filter algorithm which solves the most fundamental state of the problem near optimal. The experimental results on the randomly polygons generated by Bottino shows that the new method is more accurate with less or equal guards. Furthermore, we discuss the resampling and particle numbers to minimize the running time.
Creating A New Color Space utilizing PSO and FCM to Perform Skin Detection by using Neural Network and ANFIS
Jun 22, 2021
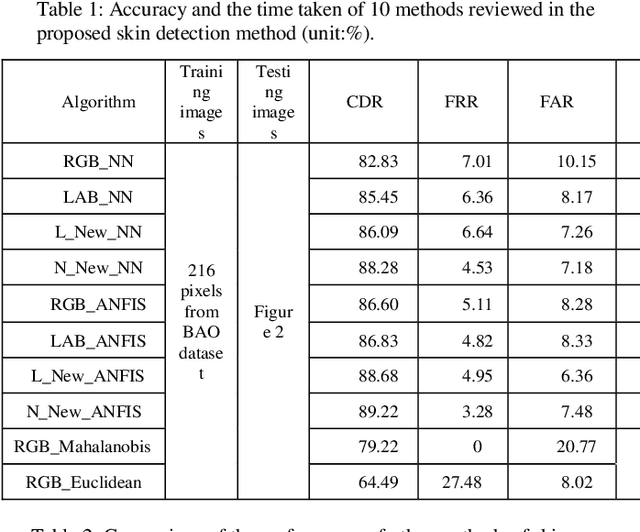
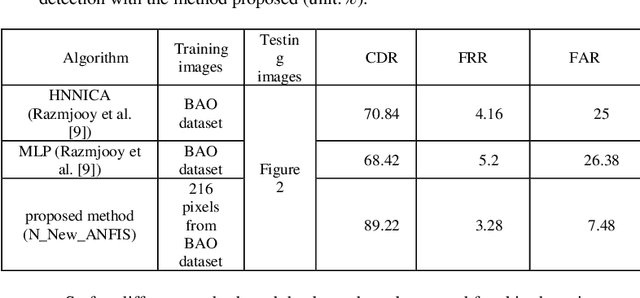

Skin color detection is an essential required step in various applications related to computer vision. These applications will include face detection, finding pornographic images in movies and photos, finding ethnicity, age, diagnosis, and so on. Therefore, proposing a proper skin detection method can provide solution to several problems. In this study, first a new color space is created using FCM and PSO algorithms. Then, skin classification has been performed in the new color space utilizing linear and nonlinear modes. Additionally, it has been done in RGB and LAB color spaces by using ANFIS and neural network. Skin detection in RBG color space has been performed using Mahalanobis distance and Euclidean distance algorithms. In comparison, this method has 18.38% higher accuracy than the most accurate method on the same database. Additionally, this method has achieved 90.05% in equal error rate (1-EER) in testing COMPAQ dataset and 92.93% accuracy in testing Pratheepan dataset, which compared to the previous method on COMPAQ database, 1-EER has increased by %0.87.
Extracting an English-Persian Parallel Corpus from Comparable Corpora
Jul 31, 2018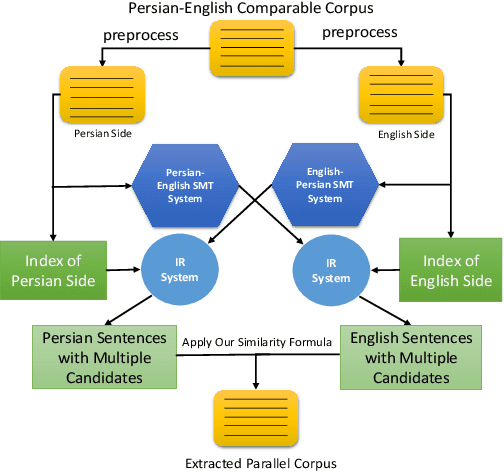
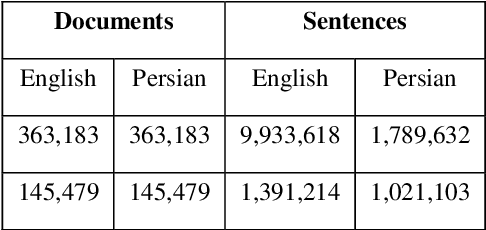
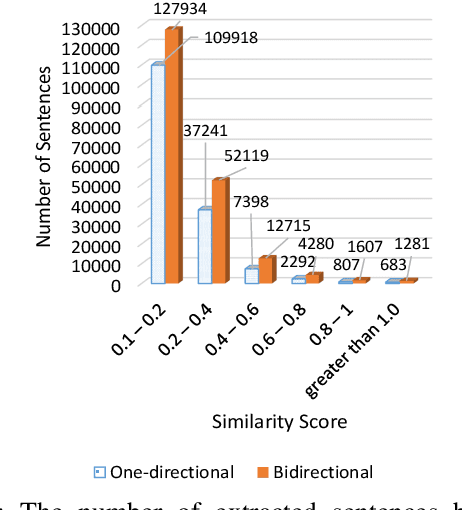
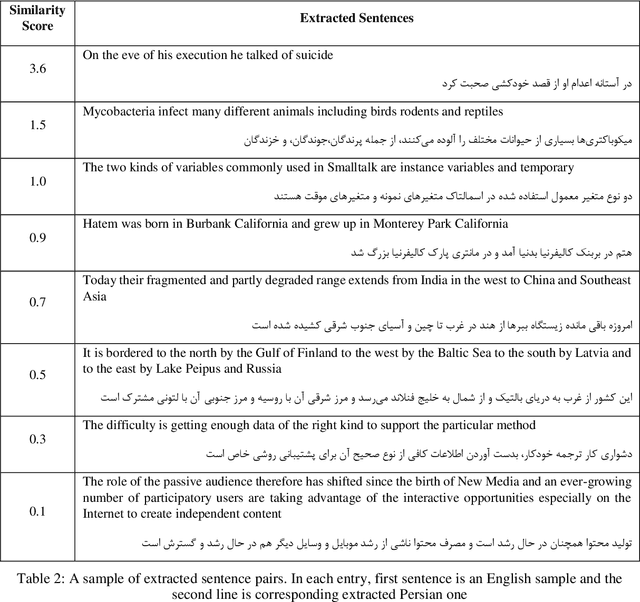
Parallel data are an important part of a reliable Statistical Machine Translation (SMT) system. The more of these data are available, the better the quality of the SMT system. However, for some language pairs such as Persian-English, parallel sources of this kind are scarce. In this paper, a bidirectional method is proposed to extract parallel sentences from English and Persian document aligned Wikipedia. Two machine translation systems are employed to translate from Persian to English and the reverse after which an IR system is used to measure the similarity of the translated sentences. Adding the extracted sentences to the training data of the existing SMT systems is shown to improve the quality of the translation. Furthermore, the proposed method slightly outperforms the one-directional approach. The extracted corpus consists of about 200,000 sentences which have been sorted by their degree of similarity calculated by the IR system and is freely available for public access on the Web.