 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing English as Pivot to Extract Persian-Italian Parallel Sentences from Non-Parallel Corpora
Paper and Code
Jan 29, 2017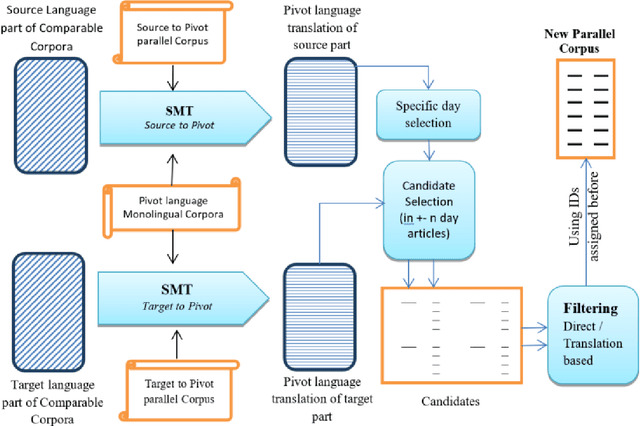


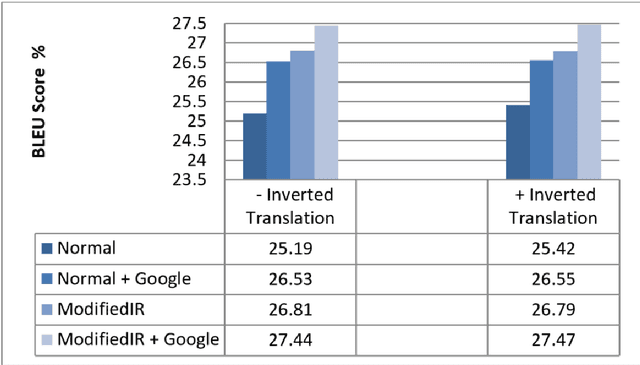
The effectiveness of a statistical machine translation system (SMT) is very dependent upon the amount of parallel corpus used in the training phase. For low-resource language pairs there are not enough parallel corpora to build an accurate SMT. In this paper, a novel approach is presented to extract bilingual Persian-Italian parallel sentences from a non-parallel (comparable) corpus. In this study, English is used as the pivot language to compute the matching scores between source and target sentences and candidate selection phase. Additionally, a new monolingual sentence similarity metric, Normalized Google Distance (NGD) is proposed to improve the matching process. Moreover, some extensions of the baseline system are applied to improve the quality of extracted sentences measured with BLEU. Experimental results show that using the new pivot based extraction can increase the quality of bilingual corpus significantly and consequently improves the performance of the Persian-Italian SMT system.