 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Gated Social Graph: Pedestrian Trajectory Prediction Based on Dynamic Social Graphs and Scene Constraints
Oct 12, 2020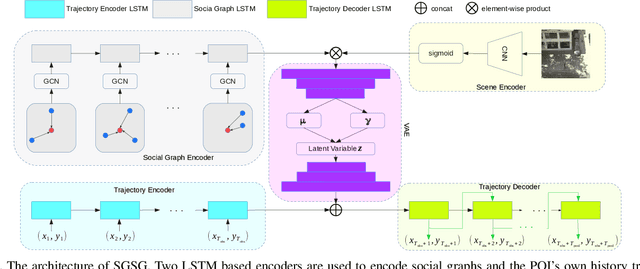
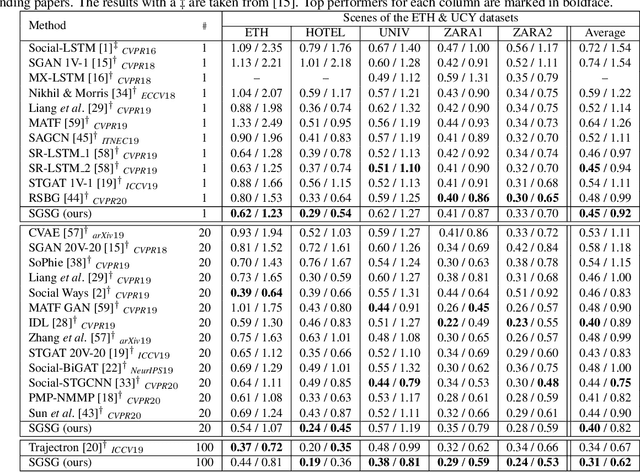
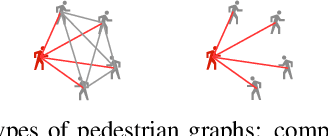
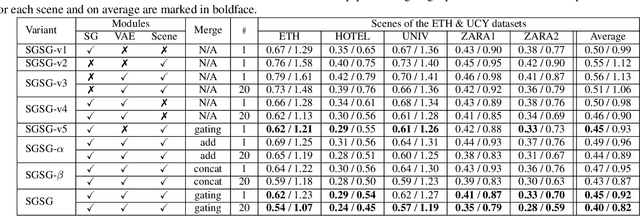
Pedestrian trajectory prediction is valuable for understanding human motion behaviors and it is challenging because of the social influence from other pedestrians, the scene constraints and the multimodal possibilities of predicted trajectories. Most existing methods only focus on two of the above three key elements. In order to jointly consider all these elements, we propose a novel trajectory prediction method named Scene Gated Social Graph (SGSG). In the proposed SGSG, dynamic graphs are used to describe the social relationship among pedestrians. The social and scene influences are taken into account through the scene gated social graph features which combine the encoded social graph features and semantic scene features. In addition, a VAE module is incorporated to learn the scene gated social feature and sample latent variables for generating multiple trajectories that are socially and environmentally acceptable. We compare our SGSG against twenty state-of-the-art pedestrian trajectory prediction methods and the results show that the proposed method achieves superior performance on two widely used trajectory prediction benchmarks.
Hit ratio: An Evaluation Metric for Hashtag Recommendation
Oct 03, 2020



Hashtag recommendation is a crucial task, especially with an increase of interest in using social media platforms such as Twitter in the last decade. Hashtag recommendation systems automatically suggest hashtags to a user while writing a tweet. Most of the research in the area of hashtag recommendation have used classical metrics such as hit rate, precision, recall, and F1-score to measure the accuracy of hashtag recommendation systems. These metrics are based on the exact match of the recommended hashtags with their corresponding ground truth. However, it is not clear how adequate these metrics to evaluate hashtag recommendation. The research question that we are interested in seeking an answer is: are these metrics adequate for evaluating hashtag recommendation systems when the numbers of ground truth hashtags in tweets are highly variable? In this paper, we propose a new metric which we call hit ratio for hashtag recommendation. Extensive evaluation through hypothetical examples and real-world application across a range of hashtag recommendation models indicate that the hit ratio is a useful metric. A comparison of hit ratio with the classical evaluation metrics reveals their limitations.
Loss Switching Fusion with Similarity Search for Video Classification
Jun 27, 2019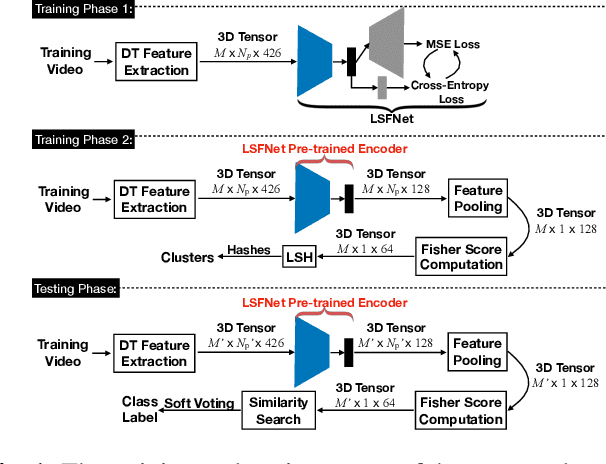

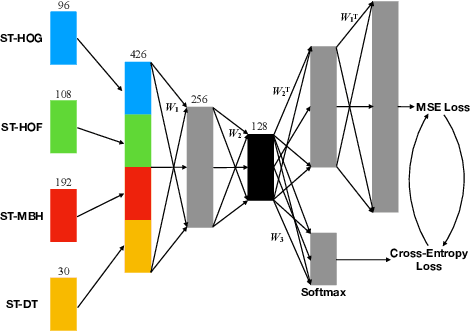
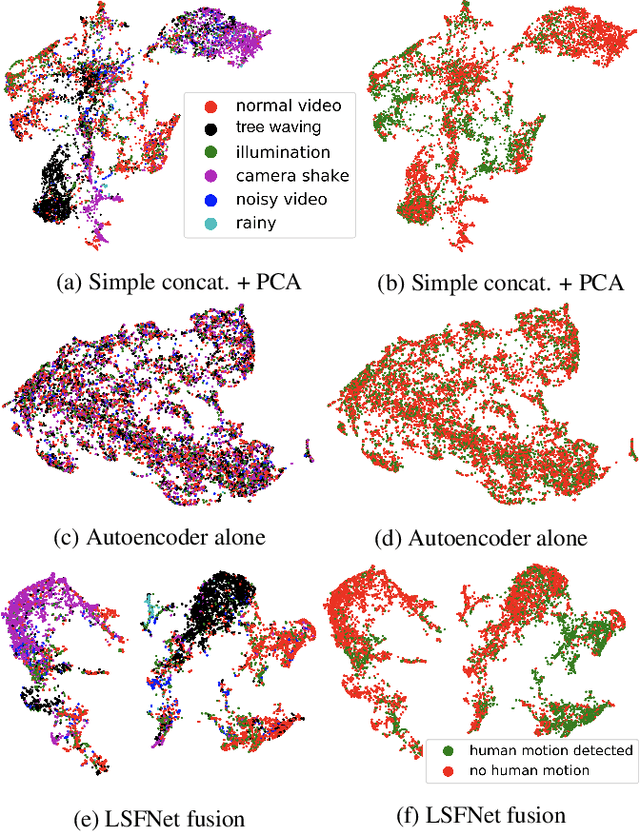
From video streaming to security and surveillance applications, video data play an important role in our daily living today. However, managing a large amount of video data and retrieving the most useful information for the user remain a challenging task. In this paper, we propose a novel video classification system that would benefit the scene understanding task. We define our classification problem as classifying background and foreground motions using the same feature representation for outdoor scenes. This means that the feature representation needs to be robust enough and adaptable to different classification tasks. We propose a lightweight Loss Switching Fusion Network (LSFNet) for the fusion of spatiotemporal descriptors and a similarity search scheme with soft voting to boost the classification performance. The proposed system has a variety of potential applications such as content-based video clustering, video filtering, etc. Evaluation results on two private industry datasets show that our system is robust in both classifying different background motions and detecting human motions from these background motions.
A Comparative Review of Recent Kinect-based Action Recognition Algorithms
Jun 24, 2019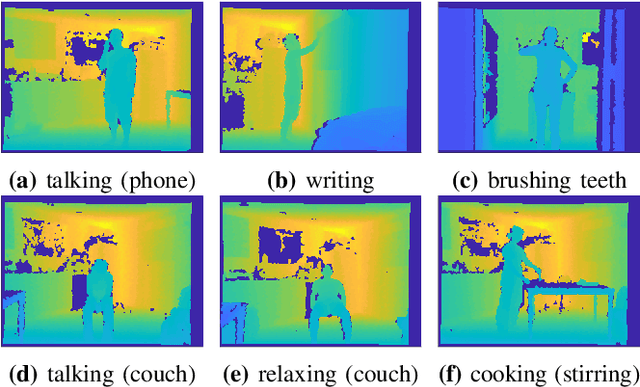
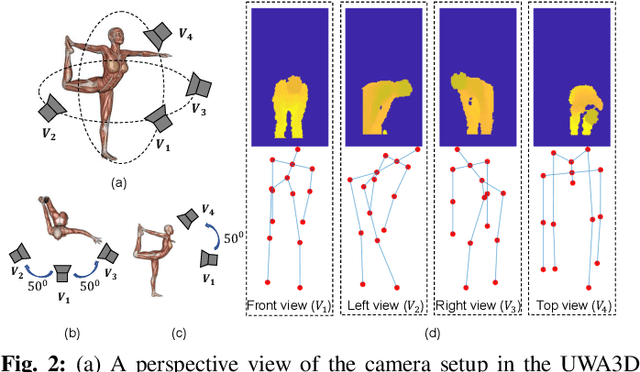
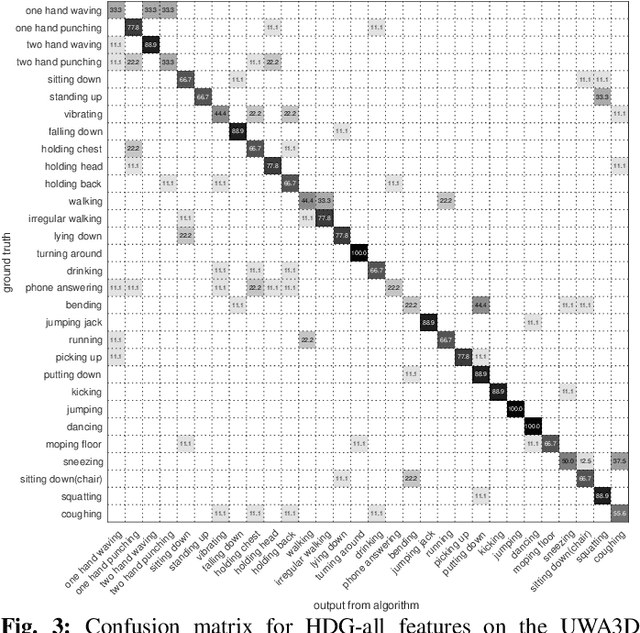
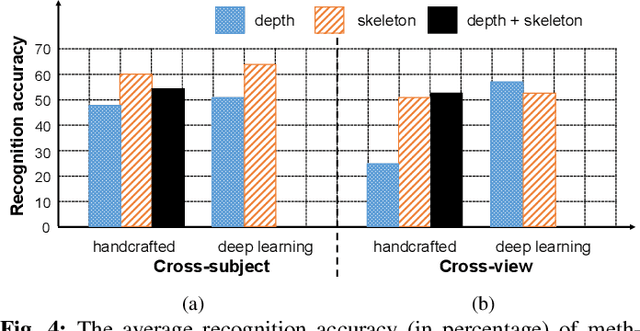
Video-based human action recognition is currently one of the most active research areas in computer vision. Various research studies indicate that the performance of action recognition is highly dependent on the type of features being extracted and how the actions are represented. Since the release of the Kinect camera, a large number of Kinect-based human action recognition techniques have been proposed in the literature. However, there still does not exist a thorough comparison of these Kinect-based techniques under the grouping of feature types, such as handcrafted versus deep learning features and depth-based versus skeleton-based features. In this paper, we analyze and compare ten recent Kinect-based algorithms for both cross-subject action recognition and cross-view action recognition using six benchmark datasets. In addition, we have implemented and improved some of these techniques and included their variants in the comparison. Our experiments show that the majority of methods perform better on cross-subject action recognition than cross-view action recognition, that skeleton-based features are more robust for cross-view recognition than depth-based features, and that deep learning features are suitable for large datasets.
Hallucinating Bag-of-Words and Fisher Vector IDT terms for CNN-based Action Recognition
Jun 13, 2019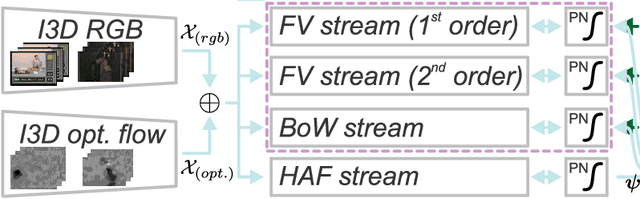
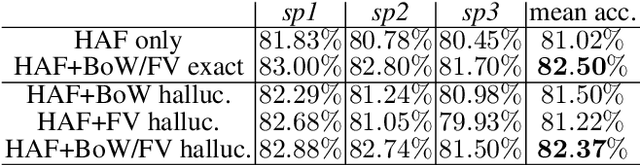
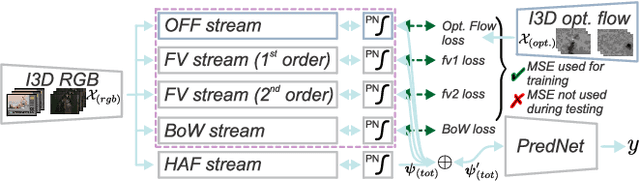
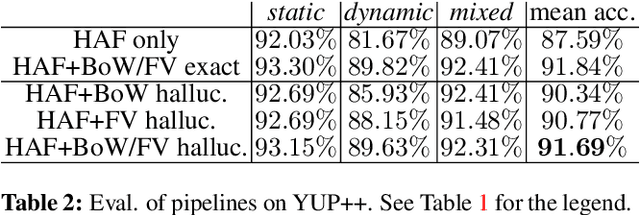
In this paper, we revive the use of old-fashioned handcrafted video representations and put new life into these techniques via a CNN-based hallucination step. Specifically, we address the problem of action classification in videos via an I3D network pre-trained on the large scale Kinetics-400 dataset. Despite of the use of RGB and optical flow frames, the I3D model (amongst others) thrives on combining its output with the Improved Dense Trajectory (IDT) and extracted with it low-level video descriptors encoded via Bag-of-Words (BoW) and Fisher Vectors (FV). Such a fusion of CNNs and hand crafted representations is time-consuming due to various pre-processing steps, descriptor extraction, encoding and fine-tuning of the model. In this paper, we propose an end-to-end trainable network with streams which learn the IDT-based BoW/FV representations at the training stage and are simple to integrate with the I3D model. Specifically, each stream takes I3D feature maps ahead of the last 1D conv. layer and learns to `translate' these maps to BoW/FV representations. Thus, our enhanced I3D model can hallucinate and use such synthesized BoW/FV representations at the testing stage. We demonstrate simplicity/usefulness of our model on three publicly available datasets and we show state-of-the-art results.
HOPC: Histogram of Oriented Principal Components of 3D Pointclouds for Action Recognition
Sep 22, 2014
Existing techniques for 3D action recognition are sensitive to viewpoint variations because they extract features from depth images which change significantly with viewpoint. In contrast, we directly process the pointclouds and propose a new technique for action recognition which is more robust to noise, action speed and viewpoint variations. Our technique consists of a novel descriptor and keypoint detection algorithm. The proposed descriptor is extracted at a point by encoding the Histogram of Oriented Principal Components (HOPC) within an adaptive spatio-temporal support volume around that point. Based on this descriptor, we present a novel method to detect Spatio-Temporal Key-Points (STKPs) in 3D pointcloud sequences. Experimental results show that the proposed descriptor and STKP detector outperform state-of-the-art algorithms on three benchmark human activity datasets. We also introduce a new multiview public dataset and show the robustness of our proposed method to viewpoint variations.