 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinating Bag-of-Words and Fisher Vector IDT terms for CNN-based Action Recognition
Paper and Code
Jun 13, 2019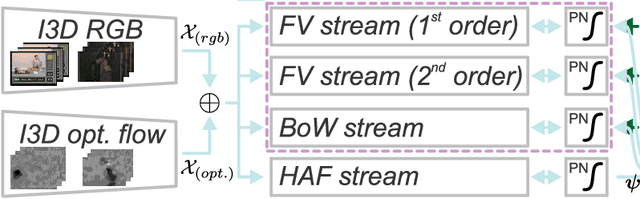
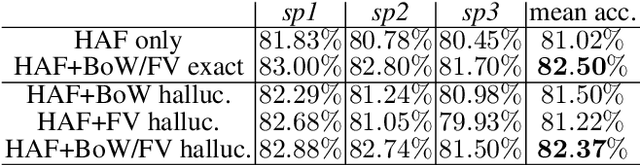
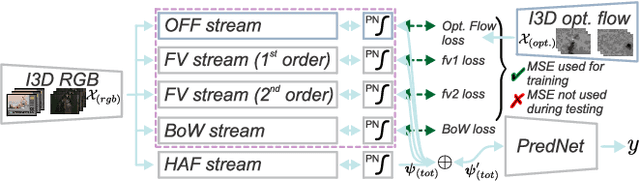
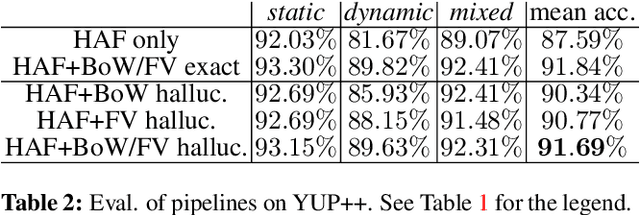
In this paper, we revive the use of old-fashioned handcrafted video representations and put new life into these techniques via a CNN-based hallucination step. Specifically, we address the problem of action classification in videos via an I3D network pre-trained on the large scale Kinetics-400 dataset. Despite of the use of RGB and optical flow frames, the I3D model (amongst others) thrives on combining its output with the Improved Dense Trajectory (IDT) and extracted with it low-level video descriptors encoded via Bag-of-Words (BoW) and Fisher Vectors (FV). Such a fusion of CNNs and hand crafted representations is time-consuming due to various pre-processing steps, descriptor extraction, encoding and fine-tuning of the model. In this paper, we propose an end-to-end trainable network with streams which learn the IDT-based BoW/FV representations at the training stage and are simple to integrate with the I3D model. Specifically, each stream takes I3D feature maps ahead of the last 1D conv. layer and learns to `translate' these maps to BoW/FV representations. Thus, our enhanced I3D model can hallucinate and use such synthesized BoW/FV representations at the testing stage. We demonstrate simplicity/usefulness of our model on three publicly available datasets and we show state-of-the-art results.