 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
OmniDiT: Extending Diffusion Transformer to Omni-VTON Framework
Mar 20, 2026Despite the rapid advancement of Virtual Try-On (VTON) and Try-Off (VTOFF) technologies, existing VTON methods face challenges with fine-grained detail preservation, generalization to complex scenes, complicated pipeline, and efficient inference. To tackle these problems, we propose OmniDiT, an omni Virtual Try-On framework based on the Diffusion Transformer, which combines try-on and try-off tasks into one unified model. Specifically, we first establish a self-evolving data curation pipeline to continuously produce data, and construct a large VTON dataset Omni-TryOn, which contains over 380k diverse and high-quality garment-model-tryon image pairs and detailed text prompts. Then, we employ the token concatenation and design an adaptive position encoding to effectively incorporate multiple reference conditions. To relieve the bottleneck of long sequence computation, we are the first to introduce Shifted Window Attention into the diffusion model, thus achieving a linear complexity. To remedy the performance degradation caused by local window attention, we utilize multiple timestep prediction and an alignment loss to improve generation fidelity. Experiments reveal that, under various complex scenes, our method achieves the best performance in both the model-free VTON and VTOFF tasks and a performance comparable to current SOTA methods in the model-based VTON task.
EVLM: An Efficient Vision-Language Model for Visual Understanding
Jul 19, 2024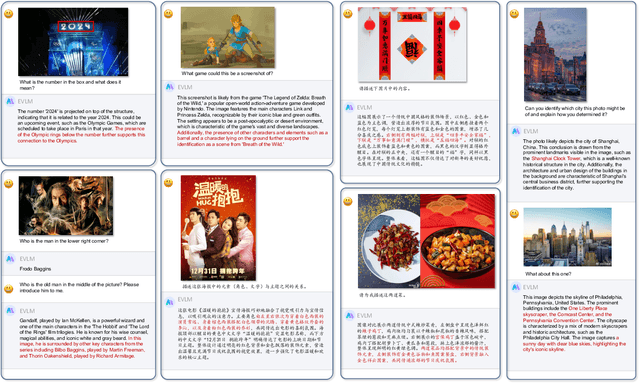
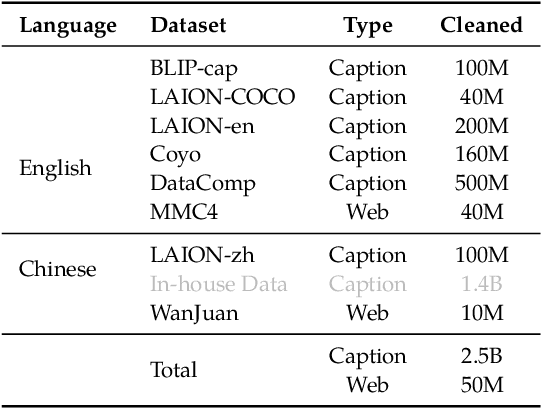
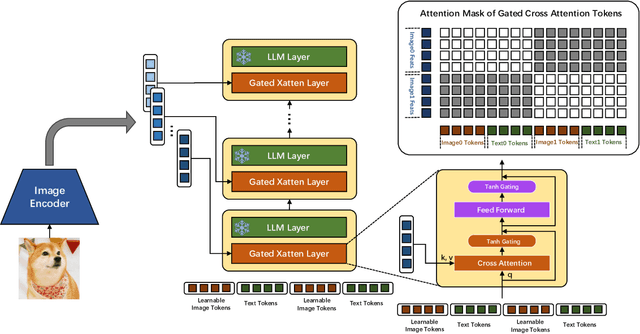

In the field of multi-modal language models, the majority of methods are built on an architecture similar to LLaVA. These models use a single-layer ViT feature as a visual prompt, directly feeding it into the language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features makes it challenging for large language models to perceive visual signals fully. This paper proposes an efficient multi-modal language model to minimize computational costs while enabling the model to perceive visual signals as comprehensively as possible. Our method primarily includes: (1) employing cross-attention to image-text interaction similar to Flamingo. (2) utilize hierarchical ViT features. (3) introduce the Mixture of Experts (MoE) mechanism to enhance model effectiveness. Our model achieves competitive scores on public multi-modal benchmarks and performs well in tasks such as image captioning and video captioning.
Improving Crowded Object Detection via Copy-Paste
Nov 22, 2022



Crowdedness caused by overlapping among similar objects is a ubiquitous challenge in the field of 2D visual object detection. In this paper, we first underline two main effects of the crowdedness issue: 1) IoU-confidence correlation disturbances (ICD) and 2) confused de-duplication (CDD). Then we explore a pathway of cracking these nuts from the perspective of data augmentation. Primarily, a particular copy-paste scheme is proposed towards making crowded scenes. Based on this operation, we first design a "consensus learning" method to further resist the ICD problem and then find out the pasting process naturally reveals a pseudo "depth" of object in the scene, which can be potentially used for alleviating CDD dilemma. Both methods are derived from magical using of the copy-pasting without extra cost for hand-labeling. Experiments show that our approach can easily improve the state-of-the-art detector in typical crowded detection task by more than 2% without any bells and whistles. Moreover, this work can outperform existing data augmentation strategies in crowded scenario.