 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Optimal Interventions
Feb 22, 2017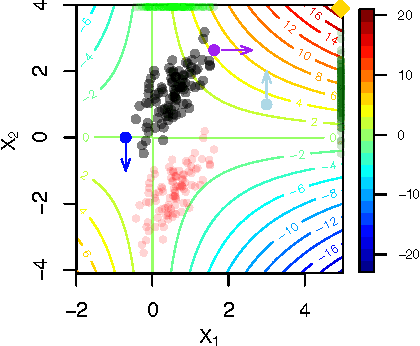
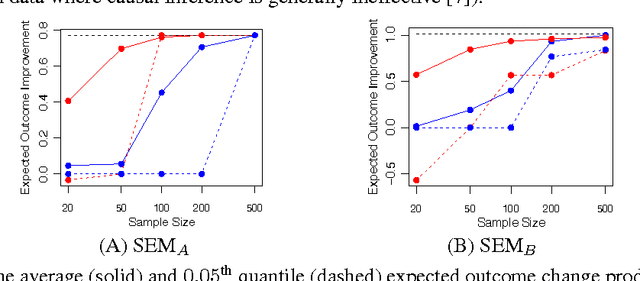
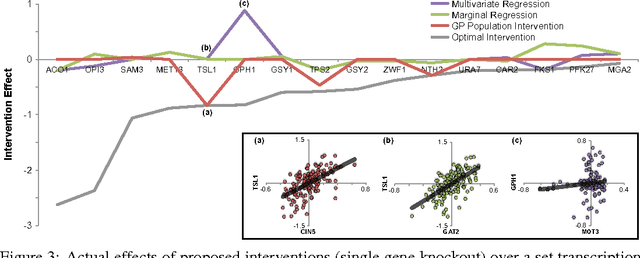
Our goal is to identify beneficial interventions from observational data. We consider interventions that are narrowly focused (impacting few covariates) and may be tailored to each individual or globally enacted over a population. For applications where harmful intervention is drastically worse than proposing no change, we propose a conservative definition of the optimal intervention. Assuming the underlying relationship remains invariant under intervention, we develop efficient algorithms to identify the optimal intervention policy from limited data and provide theoretical guarantees for our approach in a Gaussian Process setting. Although our methods assume covariates can be precisely adjusted, they remain capable of improving outcomes in misspecified settings where interventions incur unintentional downstream effects. Empirically, our approach identifies good interventions in two practical applications: gene perturbation and writing improvement.
* AISTATS 2017
Measuring dependence powerfully and equitably
Jul 06, 2016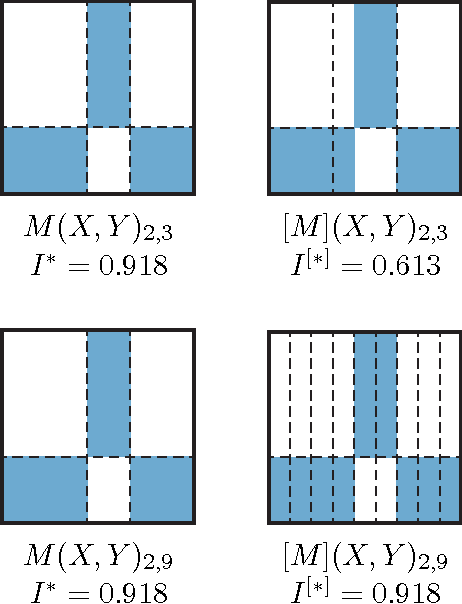

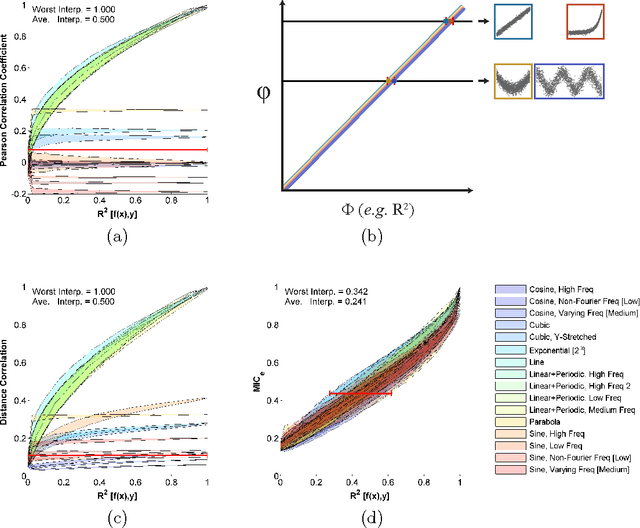
Given a high-dimensional data set we often wish to find the strongest relationships within it. A common strategy is to evaluate a measure of dependence on every variable pair and retain the highest-scoring pairs for follow-up. This strategy works well if the statistic used is equitable [Reshef et al. 2015a], i.e., if, for some measure of noise, it assigns similar scores to equally noisy relationships regardless of relationship type (e.g., linear, exponential, periodic). In this paper, we introduce and characterize a population measure of dependence called MIC*. We show three ways that MIC* can be viewed: as the population value of MIC, a highly equitable statistic from [Reshef et al. 2011], as a canonical "smoothing" of mutual information, and as the supremum of an infinite sequence defined in terms of optimal one-dimensional partitions of the marginals of the joint distribution. Based on this theory, we introduce an efficient approach for computing MIC* from the density of a pair of random variables, and we define a new consistent estimator MICe for MIC* that is efficiently computable. In contrast, there is no known polynomial-time algorithm for computing the original equitable statistic MIC. We show through simulations that MICe has better bias-variance properties than MIC. We then introduce and prove the consistency of a second statistic, TICe, that is a trivial side-product of the computation of MICe and whose goal is powerful independence testing rather than equitability. We show in simulations that MICe and TICe have good equitability and power against independence respectively. The analyses here complement a more in-depth empirical evaluation of several leading measures of dependence [Reshef et al. 2015b] that shows state-of-the-art performance for MICe and TICe.
* Yakir A. Reshef and David N. Reshef are co-first authors, Pardis C. Sabeti and Michael M. Mitzenmacher are co-last authors. This paper, together with arXiv:1505.02212, subsumes arXiv:1408.4908. v3 includes new analyses and exposition
Equitability, interval estimation, and statistical power
May 12, 2015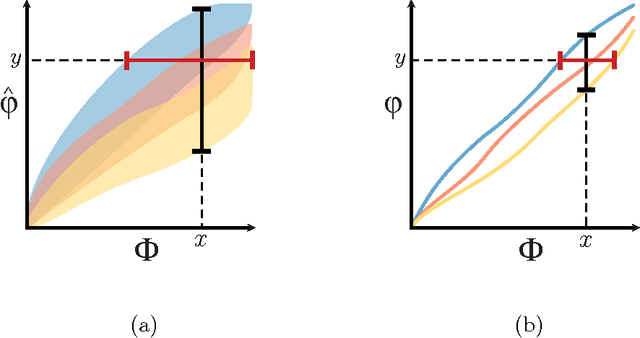
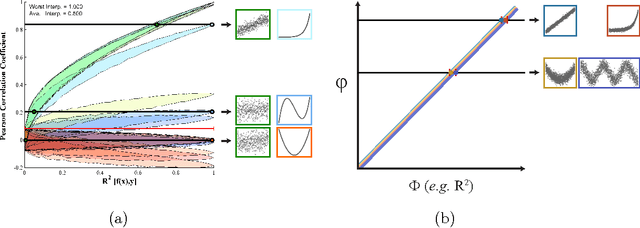
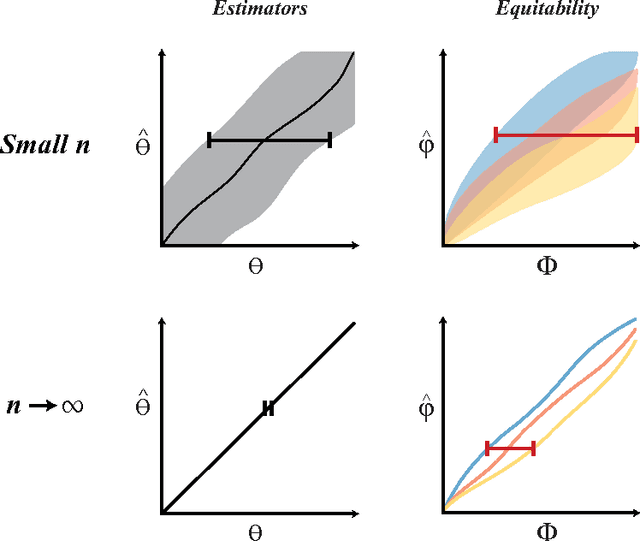
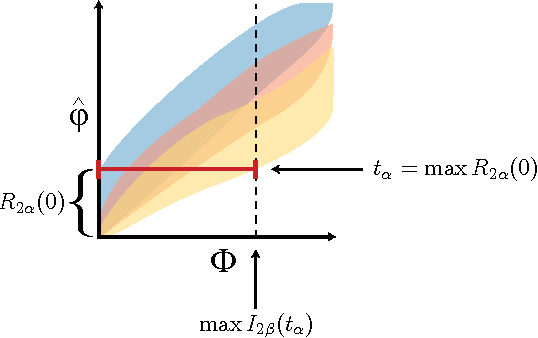
For analysis of a high-dimensional dataset, a common approach is to test a null hypothesis of statistical independence on all variable pairs using a non-parametric measure of dependence. However, because this approach attempts to identify any non-trivial relationship no matter how weak, it often identifies too many relationships to be useful. What is needed is a way of identifying a smaller set of relationships that merit detailed further analysis. Here we formally present and characterize equitability, a property of measures of dependence that aims to overcome this challenge. Notionally, an equitable statistic is a statistic that, given some measure of noise, assigns similar scores to equally noisy relationships of different types [Reshef et al. 2011]. We begin by formalizing this idea via a new object called the interpretable interval, which functions as an interval estimate of the amount of noise in a relationship of unknown type. We define an equitable statistic as one with small interpretable intervals. We then draw on the equivalence of interval estimation and hypothesis testing to show that under moderate assumptions an equitable statistic is one that yields well powered tests for distinguishing not only between trivial and non-trivial relationships of all kinds but also between non-trivial relationships of different strengths. This means that equitability allows us to specify a threshold relationship strength $x_0$ and to search for relationships of all kinds with strength greater than $x_0$. Thus, equitability can be thought of as a strengthening of power against independence that enables fruitful analysis of data sets with a small number of strong, interesting relationships and a large number of weaker ones. We conclude with a demonstration of how our two equivalent characterizations of equitability can be used to evaluate the equitability of a statistic in practice.
Theoretical Foundations of Equitability and the Maximal Information Coefficient
May 12, 2015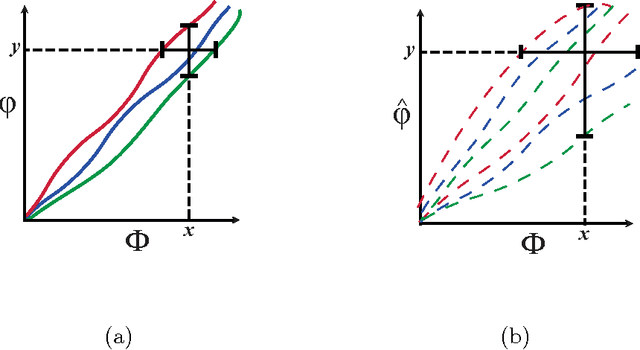
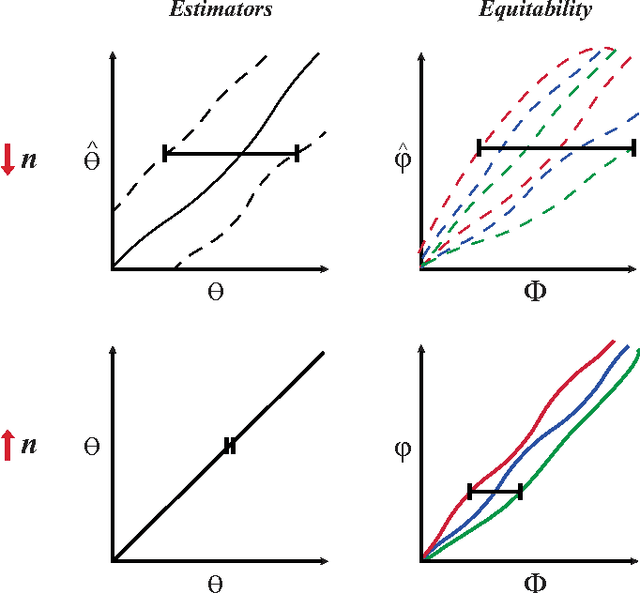

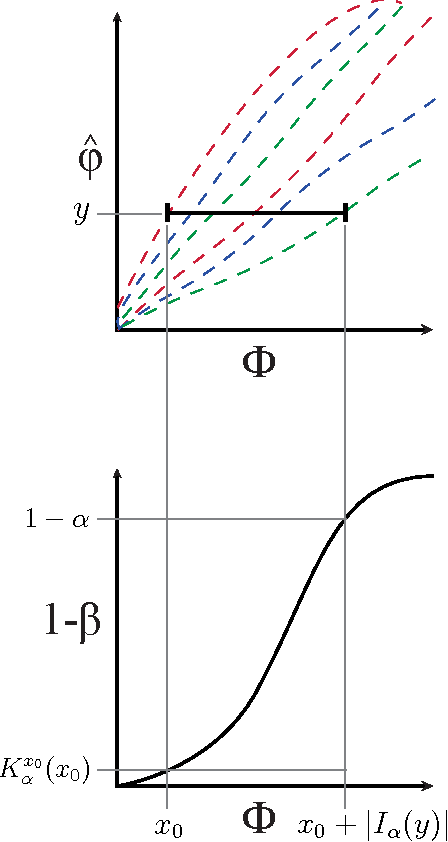
The maximal information coefficient (MIC) is a tool for finding the strongest pairwise relationships in a data set with many variables (Reshef et al., 2011). MIC is useful because it gives similar scores to equally noisy relationships of different types. This property, called {\em equitability}, is important for analyzing high-dimensional data sets. Here we formalize the theory behind both equitability and MIC in the language of estimation theory. This formalization has a number of advantages. First, it allows us to show that equitability is a generalization of power against statistical independence. Second, it allows us to compute and discuss the population value of MIC, which we call MIC_*. In doing so we generalize and strengthen the mathematical results proven in Reshef et al. (2011) and clarify the relationship between MIC and mutual information. Introducing MIC_* also enables us to reason about the properties of MIC more abstractly: for instance, we show that MIC_* is continuous and that there is a sense in which it is a canonical "smoothing" of mutual information. We also prove an alternate, equivalent characterization of MIC_* that we use to state new estimators of it as well as an algorithm for explicitly computing it when the joint probability density function of a pair of random variables is known. Our hope is that this paper provides a richer theoretical foundation for MIC and equitability going forward. This paper will be accompanied by a forthcoming companion paper that performs extensive empirical analysis and comparison to other methods and discusses the practical aspects of both equitability and the use of MIC and its related statistics.
An Empirical Study of Leading Measures of Dependence
May 12, 2015

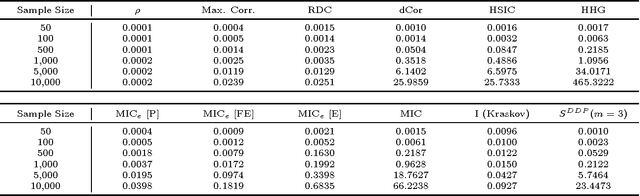
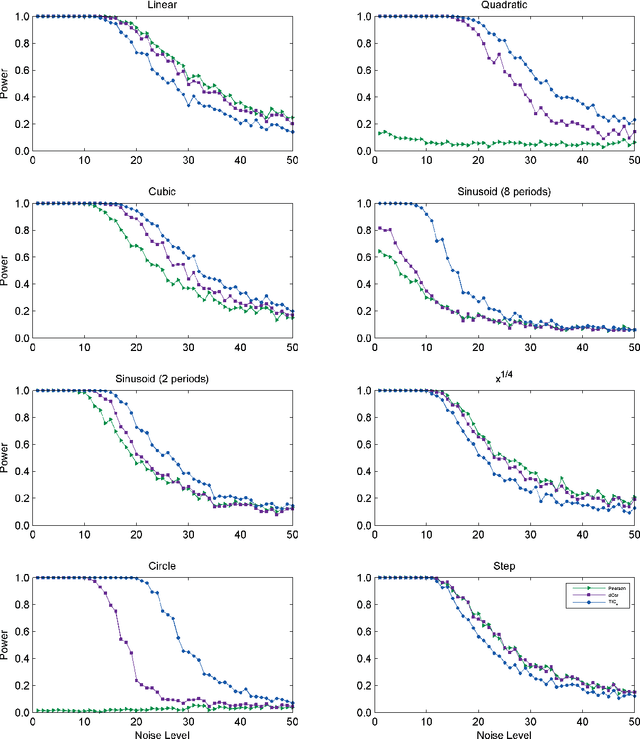
In exploratory data analysis, we are often interested in identifying promising pairwise associations for further analysis while filtering out weaker, less interesting ones. This can be accomplished by computing a measure of dependence on all variable pairs and examining the highest-scoring pairs, provided the measure of dependence used assigns similar scores to equally noisy relationships of different types. This property, called equitability, is formalized in Reshef et al. [2015b]. In addition to equitability, measures of dependence can also be assessed by the power of their corresponding independence tests as well as their runtime. Here we present extensive empirical evaluation of the equitability, power against independence, and runtime of several leading measures of dependence. These include two statistics introduced in Reshef et al. [2015a]: MICe, which has equitability as its primary goal, and TICe, which has power against independence as its goal. Regarding equitability, our analysis finds that MICe is the most equitable method on functional relationships in most of the settings we considered, although mutual information estimation proves the most equitable at large sample sizes in some specific settings. Regarding power against independence, we find that TICe, along with Heller and Gorfine's S^DDP, is the state of the art on the relationships we tested. Our analyses also show a trade-off between power against independence and equitability consistent with the theory in Reshef et al. [2015b]. In terms of runtime, MICe and TICe are significantly faster than many other measures of dependence tested, and computing either one makes computing the other trivial. This suggests that a fast and useful strategy for achieving a combination of power against independence and equitability may be to filter relationships by TICe and then to examine the MICe of only the significant ones.
* David N. Reshef and Yakir A. Reshef are co-first authors, Pardis C. Sabeti and Michael M. Mitzenmacher are co-last authors