 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven System Identification of Quadrotors Subject to Motor Delays
Apr 11, 2024



Recently non-linear control methods like Model Predictive Control (MPC) and Reinforcement Learning (RL) have attracted increased interest in the quadrotor control community. In contrast to classic control methods like cascaded PID controllers, MPC and RL heavily rely on an accurate model of the system dynamics. The process of quadrotor system identification is notoriously tedious and is often pursued with additional equipment like a thrust stand. Furthermore, low-level details like motor delays which are crucial for accurate end-to-end control are often neglected. In this work, we introduce a data-driven method to identify a quadrotor's inertia parameters, thrust curves, torque coefficients, and first-order motor delay purely based on proprioceptive data. The estimation of the motor delay is particularly challenging as usually, the RPMs can not be measured. We derive a Maximum A Posteriori (MAP)-based method to estimate the latent time constant. Our approach only requires about a minute of flying data that can be collected without any additional equipment and usually consists of three simple maneuvers. Experimental results demonstrate the ability of our method to accurately recover the parameters of multiple quadrotors. It also facilitates the deployment of RL-based, end-to-end quadrotor control of a large quadrotor under harsh, outdoor conditions.
Learning to Fly in Seconds
Nov 22, 2023Learning-based methods, particularly Reinforcement Learning (RL), hold great promise for streamlining deployment, enhancing performance, and achieving generalization in the control of autonomous multirotor aerial vehicles. Deep RL has been able to control complex systems with impressive fidelity and agility in simulation but the simulation-to-reality transfer often brings a hard-to-bridge reality gap. Moreover, RL is commonly plagued by prohibitively long training times. In this work, we propose a novel asymmetric actor-critic-based architecture coupled with a highly reliable RL-based training paradigm for end-to-end quadrotor control. We show how curriculum learning and a highly optimized simulator enhance sample complexity and lead to fast training times. To precisely discuss the challenges related to low-level/end-to-end multirotor control, we also introduce a taxonomy that classifies the existing levels of control abstractions as well as non-linearities and domain parameters. Our framework enables Simulation-to-Reality (Sim2Real) transfer for direct RPM control after only 18 seconds of training on a consumer-grade laptop as well as its deployment on microcontrollers to control a multirotor under real-time guarantees. Finally, our solution exhibits competitive performance in trajectory tracking, as demonstrated through various experimental comparisons with existing state-of-the-art control solutions using a real Crazyflie nano quadrotor. We open source the code including a very fast multirotor dynamics simulator that can simulate about 5 months of flight per second on a laptop GPU. The fast training times and deployment to a cheap, off-the-shelf quadrotor lower the barriers to entry and help democratize the research and development of these systems.
BackpropTools: A Fast, Portable Deep Reinforcement Learning Library for Continuous Control
Jun 06, 2023Deep Reinforcement Learning (RL) has been demonstrated to yield capable agents and control policies in several domains but is commonly plagued by prohibitively long training times. Additionally, in the case of continuous control problems, the applicability of learned policies on real-world embedded devices is limited due to the lack of real-time guarantees and portability of existing deep learning libraries. To address these challenges, we present BackpropTools, a dependency-free, header-only, pure C++ library for deep supervised and reinforcement learning. Leveraging the template meta-programming capabilities of recent C++ standards, we provide composable components that can be tightly integrated by the compiler. Its novel architecture allows BackpropTools to be used seamlessly on a heterogeneous set of platforms, from HPC clusters over workstations and laptops to smartphones, smartwatches, and microcontrollers. Specifically, due to the tight integration of the RL algorithms with simulation environments, BackpropTools can solve popular RL problems like the Pendulum-v1 swing-up about 7 to 15 times faster in terms of wall-clock training time compared to other popular RL frameworks when using TD3. We also provide a low-overhead and parallelized interface to the MuJoCo simulator, showing that our PPO implementation achieves state of the art returns in the Ant-v4 environment while achieving a 25 to 30 percent faster wall-clock training time. Finally, we also benchmark the policy inference on a diverse set of microcontrollers and show that in most cases our optimized inference implementation is much faster than even the manufacturer's DSP libraries. To the best of our knowledge, BackpropTools enables the first-ever demonstration of training a deep RL algorithm directly on a microcontroller, giving rise to the field of Tiny Reinforcement Learning (TinyRL). Project page: https://backprop.tools
Monitoring and mapping of crop fields with UAV swarms based on information gain
Mar 22, 2022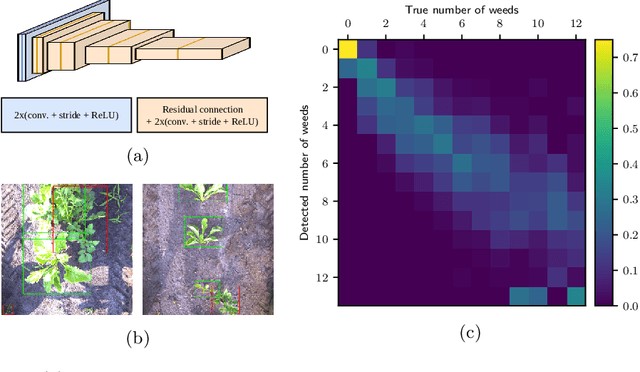
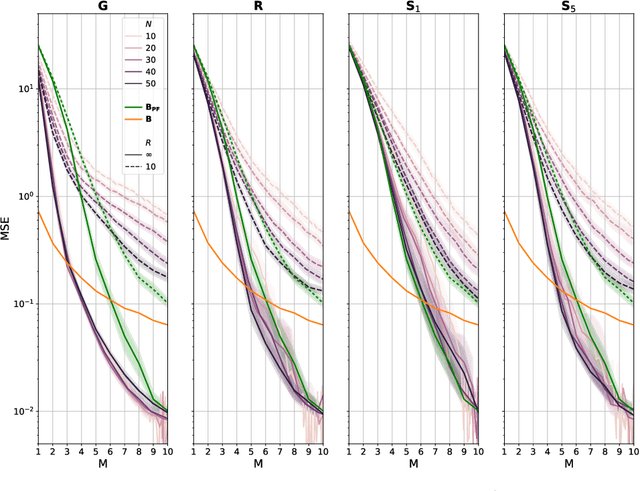
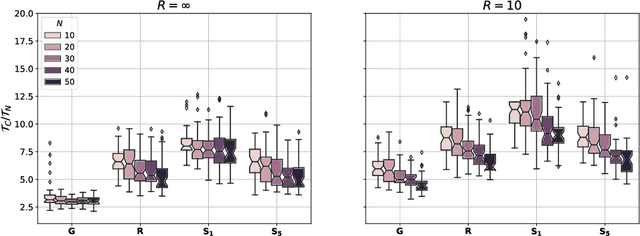
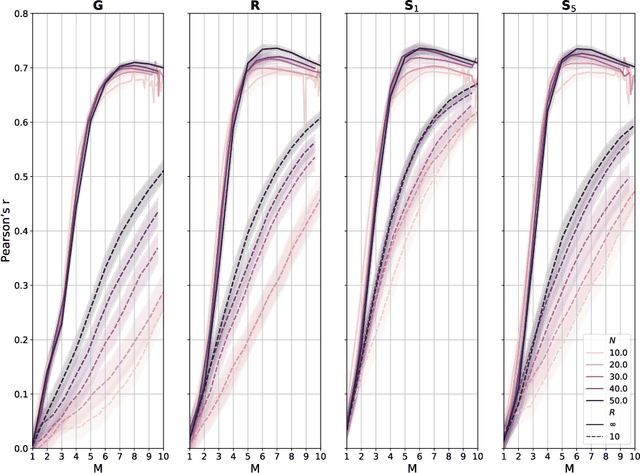
Monitoring crop fields to map features like weeds can be efficiently performed with unmanned aerial vehicles (UAVs) that can cover large areas in a short time due to their privileged perspective and motion speed. However, the need for high-resolution images for precise classification of features (e.g., detecting even the smallest weeds in the field) contrasts with the limited payload and ight time of current UAVs. Thus, it requires several flights to cover a large field uniformly. However, the assumption that the whole field must be observed with the same precision is unnecessary when features are heterogeneously distributed, like weeds appearing in patches over the field. In this case, an adaptive approach that focuses only on relevant areas can perform better, especially when multiple UAVs are employed simultaneously. Leveraging on a swarm-robotics approach, we propose a monitoring and mapping strategy that adaptively chooses the target areas based on the expected information gain, which measures the potential for uncertainty reduction due to further observations. The proposed strategy scales well with group size and leads to smaller mapping errors than optimal pre-planned monitoring approaches.