 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Quality-Diversity Trade-offs for Large-Scale Batch Recommendation
Feb 02, 2026A core research question in recommender systems is to propose batches of highly relevant and diverse items, that is, items personalized to the user's preferences, but which also might get the user out of their comfort zone. This diversity might induce properties of serendipidity and novelty which might increase user engagement or revenue. However, many real-life problems arise in that case: e.g., avoiding to recommend distinct but too similar items to reduce the churn risk, and computational cost for large item libraries, up to millions of items. First, we consider the case when the user feedback model is perfectly observed and known in advance, and introduce an efficient algorithm called B-DivRec combining determinantal point processes and a fuzzy denuding procedure to adjust the degree of item diversity. This helps enforcing a quality-diversity trade-off throughout the user history. Second, we propose an approach to adaptively tailor the quality-diversity trade-off to the user, so that diversity in recommendations can be enhanced if it leads to positive feedback, and vice-versa. Finally, we illustrate the performance and versatility of B-DivRec in the two settings on synthetic and real-life data sets on movie recommendation and drug repurposing.
Embedding Learning on Multiplex Networks for Link Prediction
Feb 02, 2026Over the past years, embedding learning on networks has shown tremendous results in link prediction tasks for complex systems, with a wide range of real-life applications. Learning a representation for each node in a knowledge graph allows us to capture topological and semantic information, which can be processed in downstream analyses later. In the link prediction task, high-dimensional network information is encoded into low-dimensional vectors, which are then fed to a predictor to infer new connections between nodes in the network. As the network complexity (that is, the numbers of connections and types of interactions) grows, embedding learning turns out increasingly challenging. This review covers published models on embedding learning on multiplex networks for link prediction. First, we propose refined taxonomies to classify and compare models, depending on the type of embeddings and embedding techniques. Second, we review and address the problem of reproducible and fair evaluation of embedding learning on multiplex networks for the link prediction task. Finally, we tackle evaluation on directed multiplex networks by proposing a novel and fair testing procedure. This review constitutes a crucial step towards the development of more performant and tractable embedding learning approaches for multiplex networks and their fair evaluation for the link prediction task. We also suggest guidelines on the evaluation of models, and provide an informed perspective on the challenges and tools currently available to address downstream analyses applied to multiplex networks.
Fast Iterative and Task-Specific Imputation with Online Learning
Jan 23, 2025



Missing feature values are a significant hurdle for downstream machine-learning tasks such as classification and regression. However, they are pervasive in multiple real-life use cases, for instance, in drug discovery research. Moreover, imputation methods might be time-consuming and offer few guarantees on the imputation quality, especially for not-missing-at-random mechanisms. We propose an imputation approach named F3I based on the iterative improvement of a K-nearest neighbor imputation that learns the weights for each neighbor of a data point, optimizing for the most likely distribution of points over data points. This algorithm can also be jointly trained with a downstream task on the imputed values. We provide a theoretical analysis of the imputation quality by F3I for several types of missing mechanisms. We also demonstrate the performance of F3I on both synthetic data sets and real-life drug repurposing and handwritten-digit recognition data.
Multivariate Functional Linear Discriminant Analysis for the Classification of Short Time Series with Missing Data
Feb 20, 2024Functional linear discriminant analysis (FLDA) is a powerful tool that extends LDA-mediated multiclass classification and dimension reduction to univariate time-series functions. However, in the age of large multivariate and incomplete data, statistical dependencies between features must be estimated in a computationally tractable way, while also dealing with missing data. There is a need for a computationally tractable approach that considers the statistical dependencies between features and can handle missing values. We here develop a multivariate version of FLDA (MUDRA) to tackle this issue and describe an efficient expectation/conditional-maximization (ECM) algorithm to infer its parameters. We assess its predictive power on the "Articulary Word Recognition" data set and show its improvement over the state-of-the-art, especially in the case of missing data. MUDRA allows interpretable classification of data sets with large proportions of missing data, which will be particularly useful for medical or psychological data sets.
An Anytime Algorithm for Good Arm Identification
Oct 16, 2023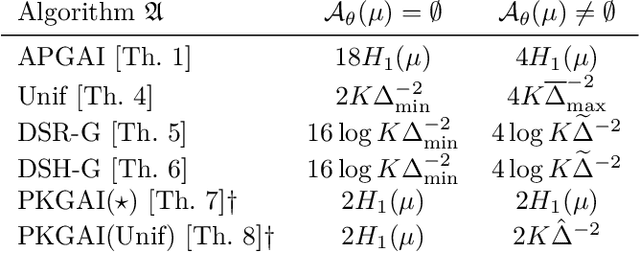
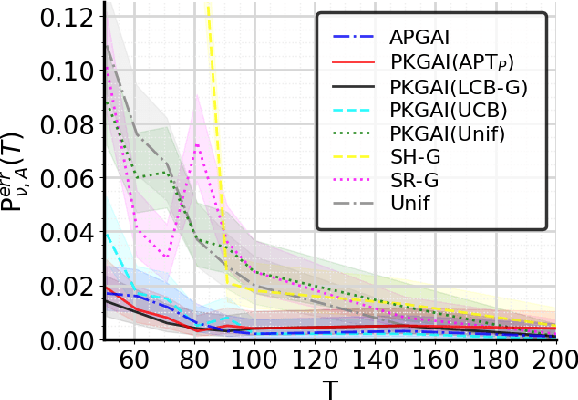

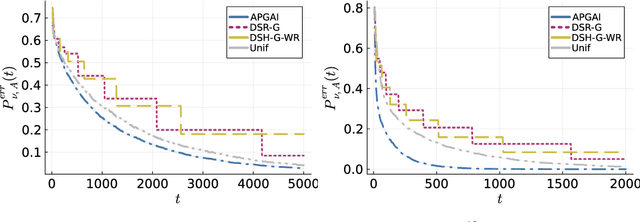
In good arm identification (GAI), the goal is to identify one arm whose average performance exceeds a given threshold, referred to as good arm, if it exists. Few works have studied GAI in the fixed-budget setting, when the sampling budget is fixed beforehand, or the anytime setting, when a recommendation can be asked at any time. We propose APGAI, an anytime and parameter-free sampling rule for GAI in stochastic bandits. APGAI can be straightforwardly used in fixed-confidence and fixed-budget settings. First, we derive upper bounds on its probability of error at any time. They show that adaptive strategies are more efficient in detecting the absence of good arms than uniform sampling. Second, when APGAI is combined with a stopping rule, we prove upper bounds on the expected sampling complexity, holding at any confidence level. Finally, we show good empirical performance of APGAI on synthetic and real-world data. Our work offers an extensive overview of the GAI problem in all settings.
Near-Optimal Collaborative Learning in Bandits
May 31, 2022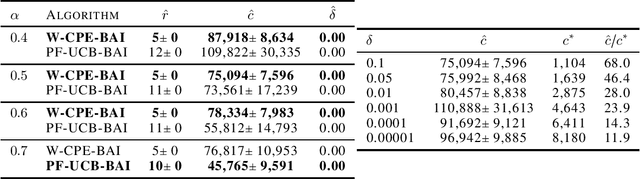
This paper introduces a general multi-agent bandit model in which each agent is facing a finite set of arms and may communicate with other agents through a central controller in order to identify, in pure exploration, or play, in regret minimization, its optimal arm. The twist is that the optimal arm for each agent is the arm with largest expected mixed reward, where the mixed reward of an arm is a weighted sum of the rewards of this arm for all agents. This makes communication between agents often necessary. This general setting allows to recover and extend several recent models for collaborative bandit learning, including the recently proposed federated learning with personalization (Shi et al., 2021). In this paper, we provide new lower bounds on the sample complexity of pure exploration and on the regret. We then propose a near-optimal algorithm for pure exploration. This algorithm is based on phased elimination with two novel ingredients: a data-dependent sampling scheme within each phase, aimed at matching a relaxation of the lower bound.
Dealing With Misspecification In Fixed-Confidence Linear Top-m Identification
Nov 02, 2021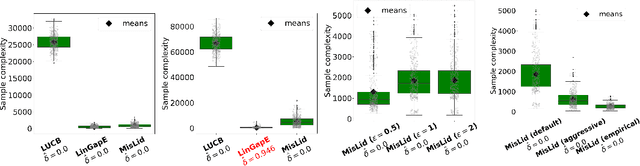


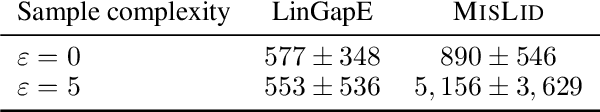
We study the problem of the identification of m arms with largest means under a fixed error rate $\delta$ (fixed-confidence Top-m identification), for misspecified linear bandit models. This problem is motivated by practical applications, especially in medicine and recommendation systems, where linear models are popular due to their simplicity and the existence of efficient algorithms, but in which data inevitably deviates from linearity. In this work, we first derive a tractable lower bound on the sample complexity of any $\delta$-correct algorithm for the general Top-m identification problem. We show that knowing the scale of the deviation from linearity is necessary to exploit the structure of the problem. We then describe the first algorithm for this setting, which is both practical and adapts to the amount of misspecification. We derive an upper bound to its sample complexity which confirms this adaptivity and that matches the lower bound when $\delta$ $\rightarrow$ 0. Finally, we evaluate our algorithm on both synthetic and real-world data, showing competitive performance with respect to existing baselines.
Top-m identification for linear bandits
Mar 18, 2021

Motivated by an application to drug repurposing, we propose the first algorithms to tackle the identification of the m $\ge$ 1 arms with largest means in a linear bandit model, in the fixed-confidence setting. These algorithms belong to the generic family of Gap-Index Focused Algorithms (GIFA) that we introduce for Top-m identification in linear bandits. We propose a unified analysis of these algorithms, which shows how the use of features might decrease the sample complexity. We further validate these algorithms empirically on simulated data and on a simple drug repurposing task.