 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection via Mean Shift Density Enhancement
Feb 03, 2026Unsupervised anomaly detection stands as an important problem in machine learning, with applications in financial fraud prevention, network security and medical diagnostics. Existing unsupervised anomaly detection algorithms rarely perform well across different anomaly types, often excelling only under specific structural assumptions. This lack of robustness also becomes particularly evident under noisy settings. We propose Mean Shift Density Enhancement (MSDE), a fully unsupervised framework that detects anomalies through their geometric response to density-driven manifold evolution. MSDE is based on the principle that normal samples, being well supported by local density, remain stable under iterative density enhancement, whereas anomalous samples undergo large cumulative displacements as they are attracted toward nearby density modes. To operationalize this idea, MSDE employs a weighted mean-shift procedure with adaptive, sample-specific density weights derived from a UMAP-based fuzzy neighborhood graph. Anomaly scores are defined by the total displacement accumulated across a small number of mean-shift iterations. We evaluate MSDE on the ADBench benchmark, comprising forty six real-world tabular datasets, four realistic anomaly generation mechanisms, and six noise levels. Compared to 13 established unsupervised baselines, MSDE achieves consistently strong, balanced and robust performance for AUC-ROC, AUC-PR, and Precision@n, at several noise levels and on average over several types of anomalies. These results demonstrate that displacement-based scoring provides a robust alternative to the existing state-of-the-art for unsupervised anomaly detection.
Embedding Learning on Multiplex Networks for Link Prediction
Feb 02, 2026Over the past years, embedding learning on networks has shown tremendous results in link prediction tasks for complex systems, with a wide range of real-life applications. Learning a representation for each node in a knowledge graph allows us to capture topological and semantic information, which can be processed in downstream analyses later. In the link prediction task, high-dimensional network information is encoded into low-dimensional vectors, which are then fed to a predictor to infer new connections between nodes in the network. As the network complexity (that is, the numbers of connections and types of interactions) grows, embedding learning turns out increasingly challenging. This review covers published models on embedding learning on multiplex networks for link prediction. First, we propose refined taxonomies to classify and compare models, depending on the type of embeddings and embedding techniques. Second, we review and address the problem of reproducible and fair evaluation of embedding learning on multiplex networks for the link prediction task. Finally, we tackle evaluation on directed multiplex networks by proposing a novel and fair testing procedure. This review constitutes a crucial step towards the development of more performant and tractable embedding learning approaches for multiplex networks and their fair evaluation for the link prediction task. We also suggest guidelines on the evaluation of models, and provide an informed perspective on the challenges and tools currently available to address downstream analyses applied to multiplex networks.
Preserving logical and functional dependencies in synthetic tabular data
Sep 26, 2024



Dependencies among attributes are a common aspect of tabular data. However, whether existing tabular data generation algorithms preserve these dependencies while generating synthetic data is yet to be explored. In addition to the existing notion of functional dependencies, we introduce the notion of logical dependencies among the attributes in this article. Moreover, we provide a measure to quantify logical dependencies among attributes in tabular data. Utilizing this measure, we compare several state-of-the-art synthetic data generation algorithms and test their capability to preserve logical and functional dependencies on several publicly available datasets. We demonstrate that currently available synthetic tabular data generation algorithms do not fully preserve functional dependencies when they generate synthetic datasets. In addition, we also showed that some tabular synthetic data generation models can preserve inter-attribute logical dependencies. Our review and comparison of the state-of-the-art reveal research needs and opportunities to develop task-specific synthetic tabular data generation models.
Convex space learning for tabular synthetic data generation
Jul 13, 2024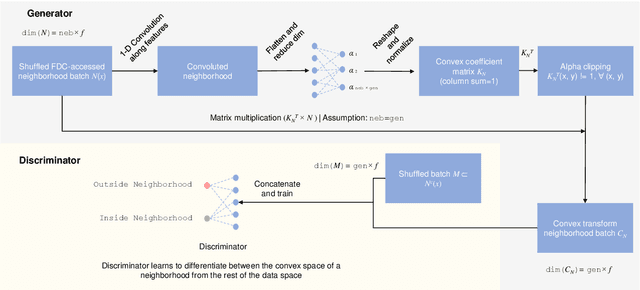
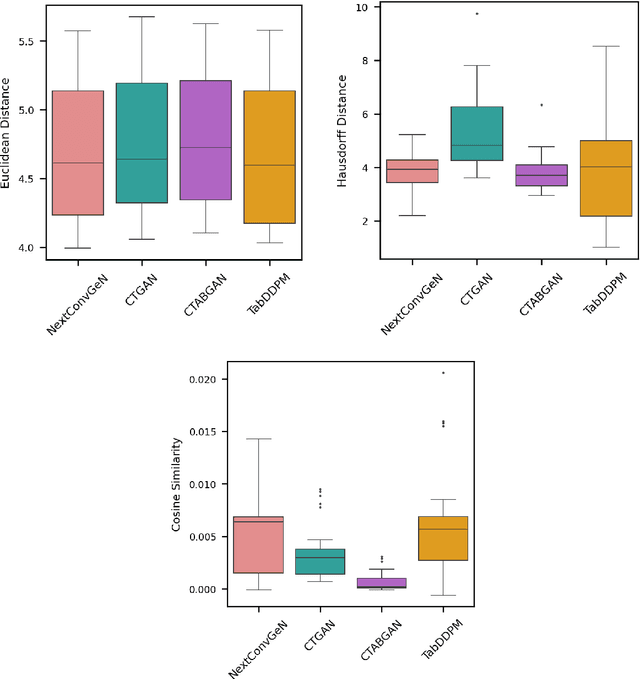
Generating synthetic samples from the convex space of the minority class is a popular oversampling approach for imbalanced classification problems. Recently, deep-learning approaches have been successfully applied to modeling the convex space of minority samples. Beyond oversampling, learning the convex space of neighborhoods in training data has not been used to generate entire tabular datasets. In this paper, we introduce a deep learning architecture (NextConvGeN) with a generator and discriminator component that can generate synthetic samples by learning to model the convex space of tabular data. The generator takes data neighborhoods as input and creates synthetic samples within the convex space of that neighborhood. Thereafter, the discriminator tries to classify these synthetic samples against a randomly sampled batch of data from the rest of the data space. We compared our proposed model with five state-of-the-art tabular generative models across ten publicly available datasets from the biomedical domain. Our analysis reveals that synthetic samples generated by NextConvGeN can better preserve classification and clustering performance across real and synthetic data than other synthetic data generation models. Synthetic data generation by deep learning of the convex space produces high scores for popular utility measures. We further compared how diverse synthetic data generation strategies perform in the privacy-utility spectrum and produced critical arguments on the necessity of high utility models. Our research on deep learning of the convex space of tabular data opens up opportunities in clinical research, machine learning model development, decision support systems, and clinical data sharing.
Multivariate Functional Linear Discriminant Analysis for the Classification of Short Time Series with Missing Data
Feb 20, 2024Functional linear discriminant analysis (FLDA) is a powerful tool that extends LDA-mediated multiclass classification and dimension reduction to univariate time-series functions. However, in the age of large multivariate and incomplete data, statistical dependencies between features must be estimated in a computationally tractable way, while also dealing with missing data. There is a need for a computationally tractable approach that considers the statistical dependencies between features and can handle missing values. We here develop a multivariate version of FLDA (MUDRA) to tackle this issue and describe an efficient expectation/conditional-maximization (ECM) algorithm to infer its parameters. We assess its predictive power on the "Articulary Word Recognition" data set and show its improvement over the state-of-the-art, especially in the case of missing data. MUDRA allows interpretable classification of data sets with large proportions of missing data, which will be particularly useful for medical or psychological data sets.
Convex space learning improves deep-generative oversampling for tabular imbalanced classification on smaller datasets
Jun 20, 2022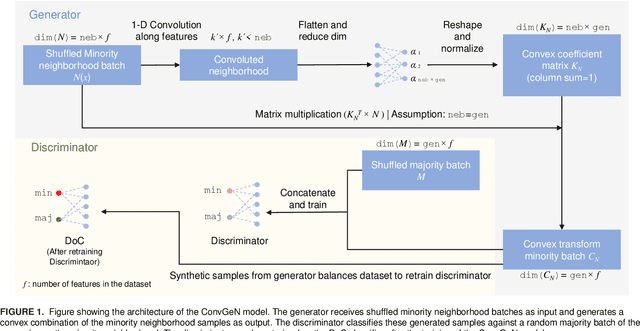
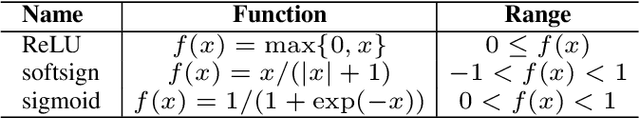
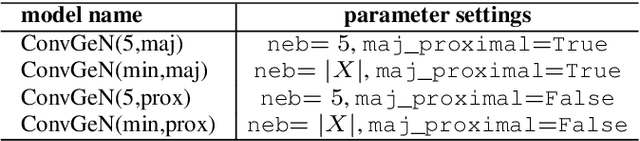
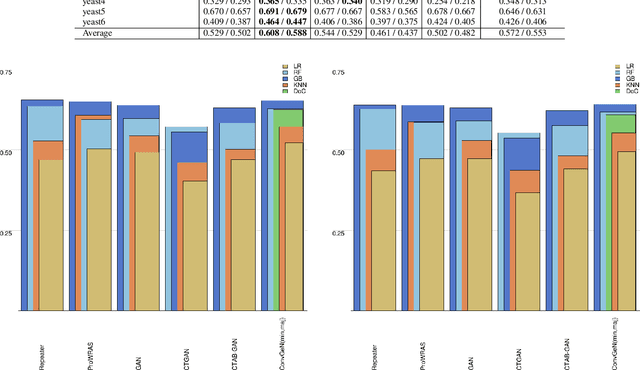
Data is commonly stored in tabular format. Several fields of research (e.g., biomedical, fault/fraud detection), are prone to small imbalanced tabular data. Supervised Machine Learning on such data is often difficult due to class imbalance, adding further to the challenge. Synthetic data generation i.e. oversampling is a common remedy used to improve classifier performance. State-of-the-art linear interpolation approaches, such as LoRAS and ProWRAS can be used to generate synthetic samples from the convex space of the minority class to improve classifier performance in such cases. Generative Adversarial Networks (GANs) are common deep learning approaches for synthetic sample generation. Although GANs are widely used for synthetic image generation, their scope on tabular data in the context of imbalanced classification is not adequately explored. In this article, we show that existing deep generative models perform poorly compared to linear interpolation approaches generating synthetic samples from the convex space of the minority class, for imbalanced classification problems on tabular datasets of small size. We propose a deep generative model, ConvGeN combining the idea of convex space learning and deep generative models. ConVGeN learns the coefficients for the convex combinations of the minority class samples, such that the synthetic data is distinct enough from the majority class. We demonstrate that our proposed model ConvGeN improves imbalanced classification on such small datasets, as compared to existing deep generative models while being at par with the existing linear interpolation approaches. Moreover, we discuss how our model can be used for synthetic tabular data generation in general, even outside the scope of data imbalance, and thus, improves the overall applicability of convex space learning.
A multi-schematic classifier-independent oversampling approach for imbalanced datasets
Jul 15, 2021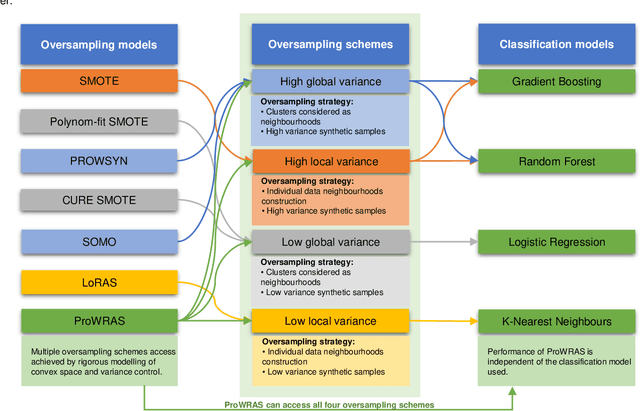
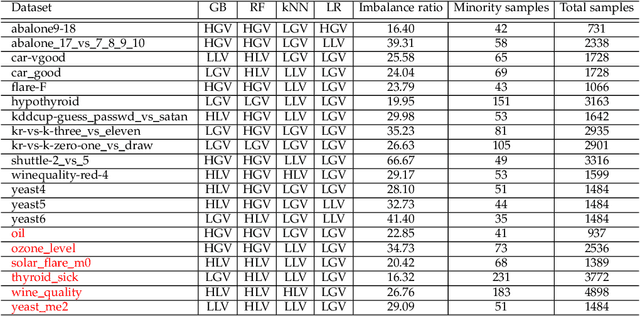
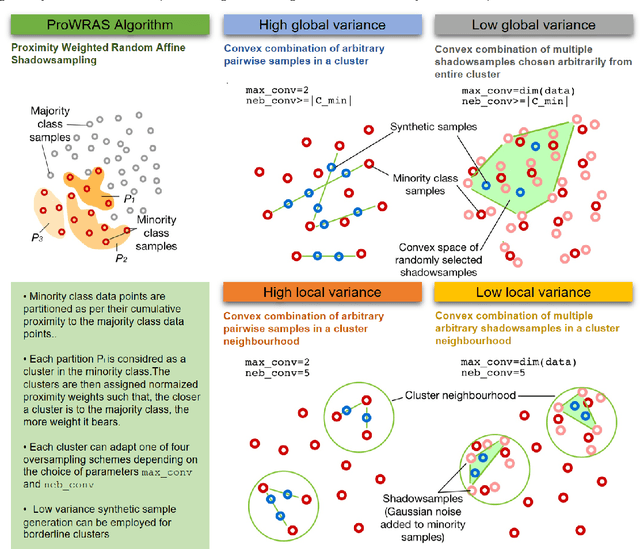
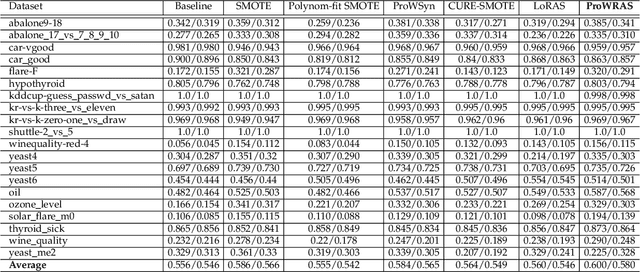
Over 85 oversampling algorithms, mostly extensions of the SMOTE algorithm, have been built over the past two decades, to solve the problem of imbalanced datasets. However, it has been evident from previous studies that different oversampling algorithms have different degrees of efficiency with different classifiers. With numerous algorithms available, it is difficult to decide on an oversampling algorithm for a chosen classifier. Here, we overcome this problem with a multi-schematic and classifier-independent oversampling approach: ProWRAS(Proximity Weighted Random Affine Shadowsampling). ProWRAS integrates the Localized Random Affine Shadowsampling (LoRAS)algorithm and the Proximity Weighted Synthetic oversampling (ProWSyn) algorithm. By controlling the variance of the synthetic samples, as well as a proximity-weighted clustering system of the minority classdata, the ProWRAS algorithm improves performance, compared to algorithms that generate synthetic samples through modelling high dimensional convex spaces of the minority class. ProWRAS has four oversampling schemes, each of which has its unique way to model the variance of the generated data. Most importantly, the performance of ProWRAS with proper choice of oversampling schemes, is independent of the classifier used. We have benchmarked our newly developed ProWRAS algorithm against five sate-of-the-art oversampling models and four different classifiers on 20 publicly available datasets. ProWRAS outperforms other oversampling algorithms in a statistically significant way, in terms of both F1-score and Kappa-score. Moreover, we have introduced a novel measure for classifier independence I-score, and showed quantitatively that ProWRAS performs better, independent of the classifier used. In practice, ProWRAS customizes synthetic sample generation according to a classifier of choice and thereby reduces benchmarking efforts.
LoRAS: An oversampling approach for imbalanced datasets
Aug 23, 2019
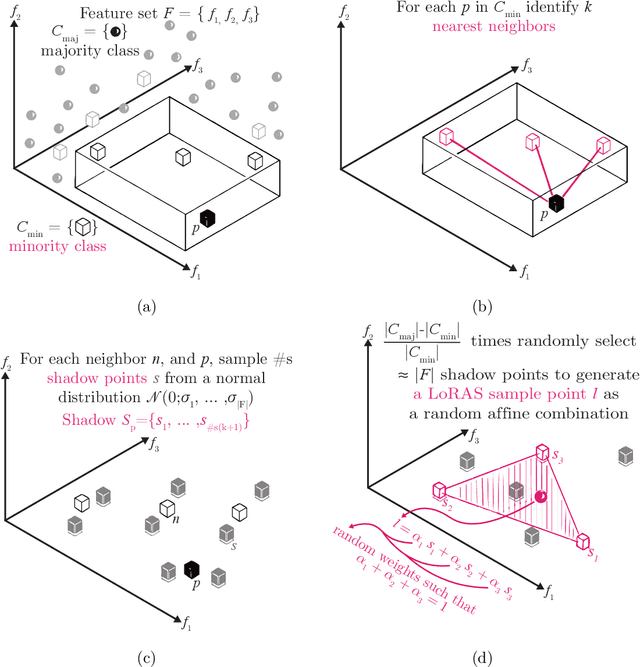
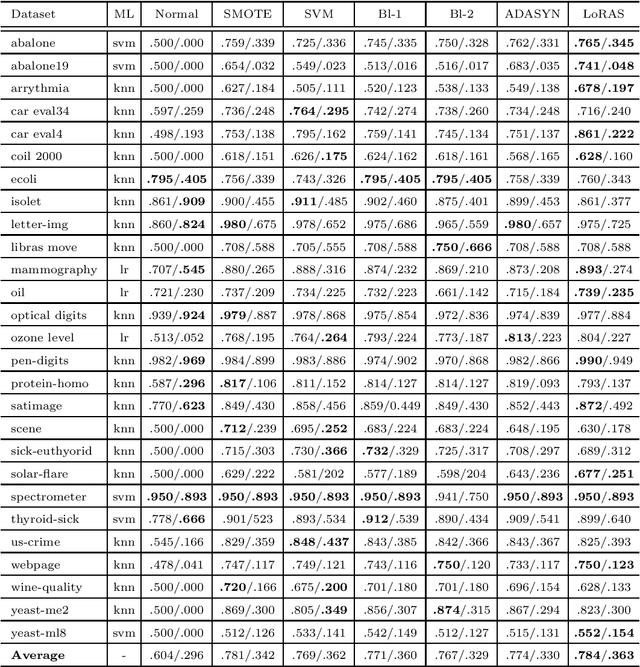
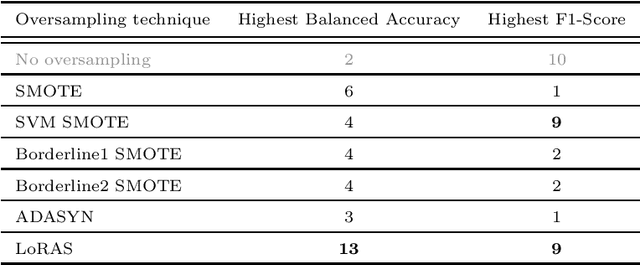
The Synthetic Minority Oversampling TEchnique (SMOTE) is widely-used for the analysis of imbalanced datasets. It is known that SMOTE frequently over-generalizes the minority class, leading to misclassifications for the majority class, and effecting the overall balance of the model. In this article, we present an approach that overcomes this limitation of SMOTE, employing Localized Random Affine Shadowsampling (LoRAS) to oversample from an approximated data manifold of the minority class. We benchmarked our LoRAS algorithm with 28 publicly available datasets and show that that drawing samples from an approximated data manifold of the minority class is the key to successful oversampling. We compared the performance of LoRAS, SMOTE, and several SMOTE extensions and observed that for imbalanced datasets LoRAS, on average generates better Machine Learning (ML) models in terms of F1-score and Balanced Accuracy. Moreover, to explain the success of the algorithm, we have constructed a mathematical framework to prove that LoRAS is a more effective oversampling technique since it provides a better estimate to mean of the underlying local data distribution of the minority class data space.