 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving logical and functional dependencies in synthetic tabular data
Sep 26, 2024



Dependencies among attributes are a common aspect of tabular data. However, whether existing tabular data generation algorithms preserve these dependencies while generating synthetic data is yet to be explored. In addition to the existing notion of functional dependencies, we introduce the notion of logical dependencies among the attributes in this article. Moreover, we provide a measure to quantify logical dependencies among attributes in tabular data. Utilizing this measure, we compare several state-of-the-art synthetic data generation algorithms and test their capability to preserve logical and functional dependencies on several publicly available datasets. We demonstrate that currently available synthetic tabular data generation algorithms do not fully preserve functional dependencies when they generate synthetic datasets. In addition, we also showed that some tabular synthetic data generation models can preserve inter-attribute logical dependencies. Our review and comparison of the state-of-the-art reveal research needs and opportunities to develop task-specific synthetic tabular data generation models.
Convex space learning for tabular synthetic data generation
Jul 13, 2024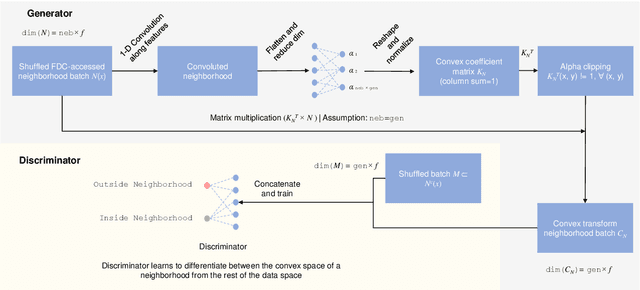
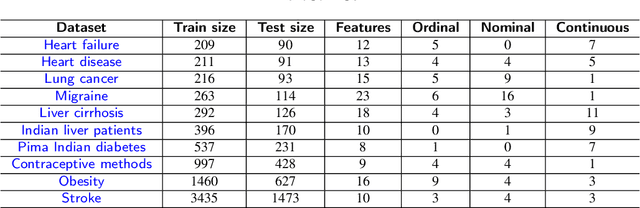
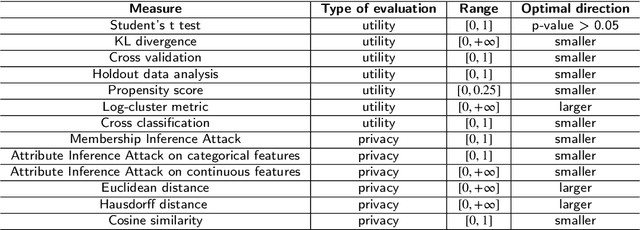
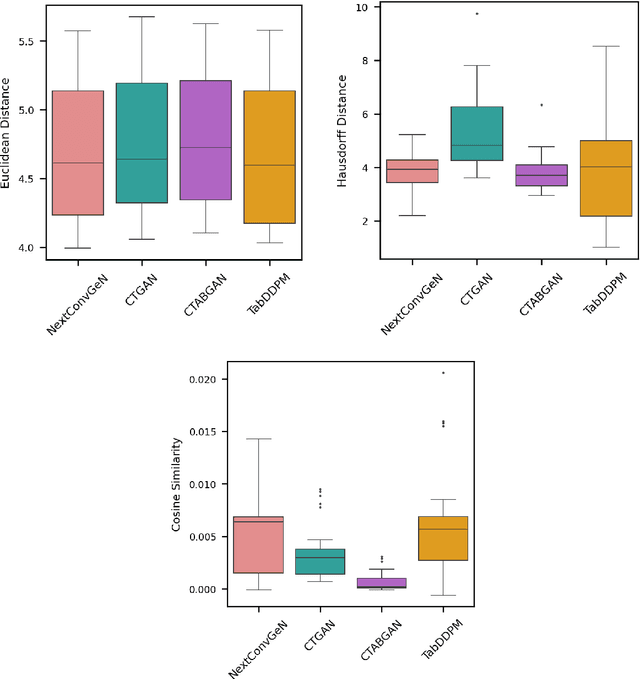
Generating synthetic samples from the convex space of the minority class is a popular oversampling approach for imbalanced classification problems. Recently, deep-learning approaches have been successfully applied to modeling the convex space of minority samples. Beyond oversampling, learning the convex space of neighborhoods in training data has not been used to generate entire tabular datasets. In this paper, we introduce a deep learning architecture (NextConvGeN) with a generator and discriminator component that can generate synthetic samples by learning to model the convex space of tabular data. The generator takes data neighborhoods as input and creates synthetic samples within the convex space of that neighborhood. Thereafter, the discriminator tries to classify these synthetic samples against a randomly sampled batch of data from the rest of the data space. We compared our proposed model with five state-of-the-art tabular generative models across ten publicly available datasets from the biomedical domain. Our analysis reveals that synthetic samples generated by NextConvGeN can better preserve classification and clustering performance across real and synthetic data than other synthetic data generation models. Synthetic data generation by deep learning of the convex space produces high scores for popular utility measures. We further compared how diverse synthetic data generation strategies perform in the privacy-utility spectrum and produced critical arguments on the necessity of high utility models. Our research on deep learning of the convex space of tabular data opens up opportunities in clinical research, machine learning model development, decision support systems, and clinical data sharing.