 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvex space learning improves deep-generative oversampling for tabular imbalanced classification on smaller datasets
Jun 20, 2022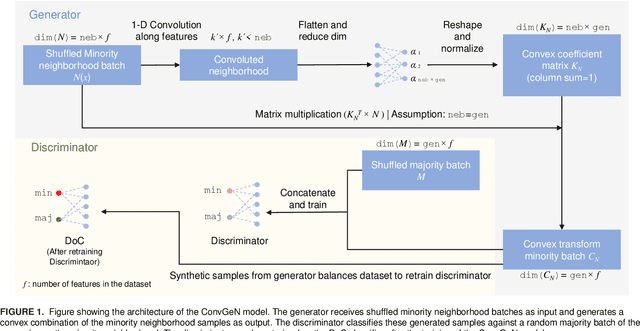
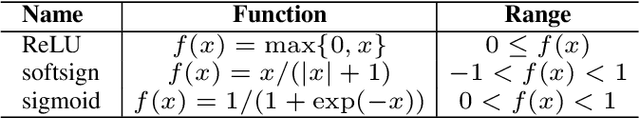
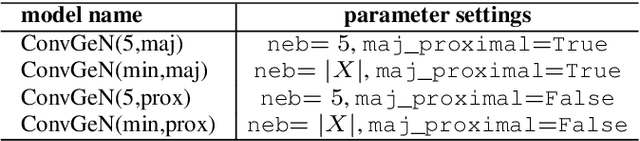
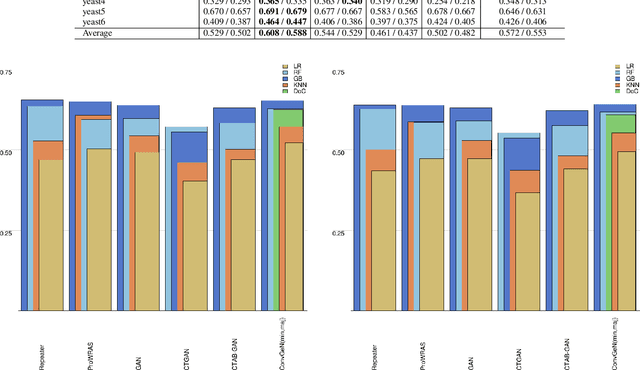
Data is commonly stored in tabular format. Several fields of research (e.g., biomedical, fault/fraud detection), are prone to small imbalanced tabular data. Supervised Machine Learning on such data is often difficult due to class imbalance, adding further to the challenge. Synthetic data generation i.e. oversampling is a common remedy used to improve classifier performance. State-of-the-art linear interpolation approaches, such as LoRAS and ProWRAS can be used to generate synthetic samples from the convex space of the minority class to improve classifier performance in such cases. Generative Adversarial Networks (GANs) are common deep learning approaches for synthetic sample generation. Although GANs are widely used for synthetic image generation, their scope on tabular data in the context of imbalanced classification is not adequately explored. In this article, we show that existing deep generative models perform poorly compared to linear interpolation approaches generating synthetic samples from the convex space of the minority class, for imbalanced classification problems on tabular datasets of small size. We propose a deep generative model, ConvGeN combining the idea of convex space learning and deep generative models. ConVGeN learns the coefficients for the convex combinations of the minority class samples, such that the synthetic data is distinct enough from the majority class. We demonstrate that our proposed model ConvGeN improves imbalanced classification on such small datasets, as compared to existing deep generative models while being at par with the existing linear interpolation approaches. Moreover, we discuss how our model can be used for synthetic tabular data generation in general, even outside the scope of data imbalance, and thus, improves the overall applicability of convex space learning.
A multi-schematic classifier-independent oversampling approach for imbalanced datasets
Jul 15, 2021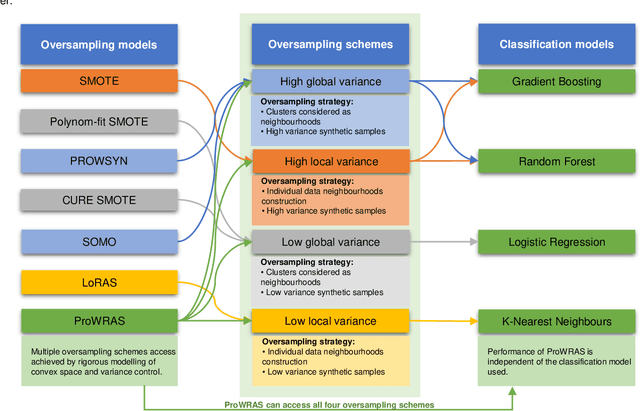
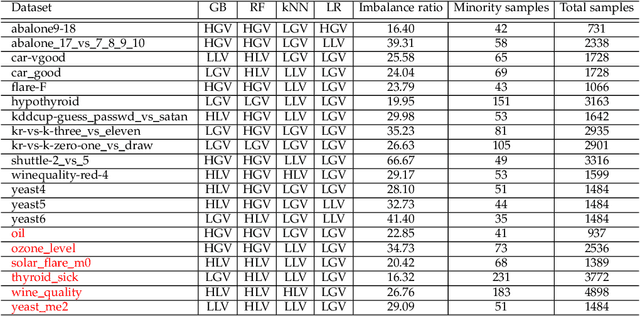
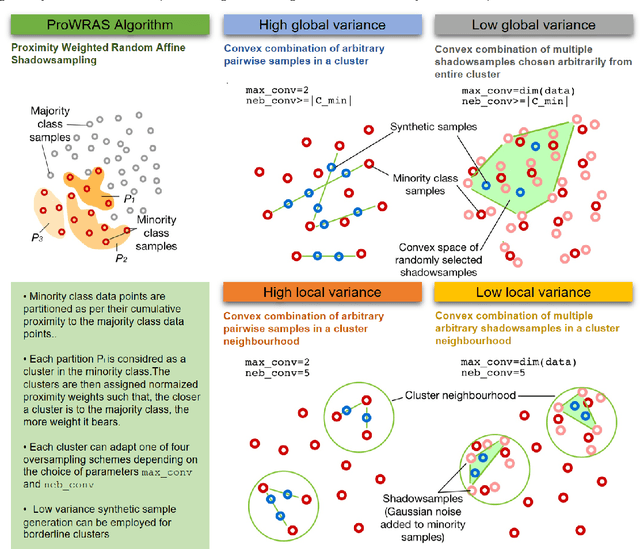
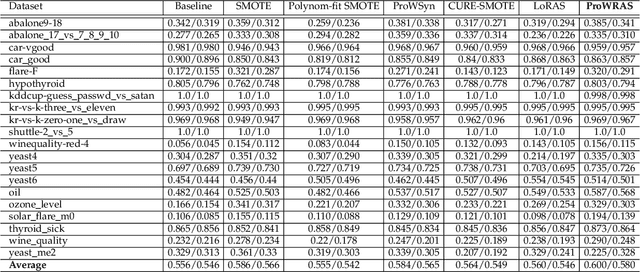
Over 85 oversampling algorithms, mostly extensions of the SMOTE algorithm, have been built over the past two decades, to solve the problem of imbalanced datasets. However, it has been evident from previous studies that different oversampling algorithms have different degrees of efficiency with different classifiers. With numerous algorithms available, it is difficult to decide on an oversampling algorithm for a chosen classifier. Here, we overcome this problem with a multi-schematic and classifier-independent oversampling approach: ProWRAS(Proximity Weighted Random Affine Shadowsampling). ProWRAS integrates the Localized Random Affine Shadowsampling (LoRAS)algorithm and the Proximity Weighted Synthetic oversampling (ProWSyn) algorithm. By controlling the variance of the synthetic samples, as well as a proximity-weighted clustering system of the minority classdata, the ProWRAS algorithm improves performance, compared to algorithms that generate synthetic samples through modelling high dimensional convex spaces of the minority class. ProWRAS has four oversampling schemes, each of which has its unique way to model the variance of the generated data. Most importantly, the performance of ProWRAS with proper choice of oversampling schemes, is independent of the classifier used. We have benchmarked our newly developed ProWRAS algorithm against five sate-of-the-art oversampling models and four different classifiers on 20 publicly available datasets. ProWRAS outperforms other oversampling algorithms in a statistically significant way, in terms of both F1-score and Kappa-score. Moreover, we have introduced a novel measure for classifier independence I-score, and showed quantitatively that ProWRAS performs better, independent of the classifier used. In practice, ProWRAS customizes synthetic sample generation according to a classifier of choice and thereby reduces benchmarking efforts.