 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Algorithms for Multi-Player Bandits without Collision Sensing Information
Mar 24, 2021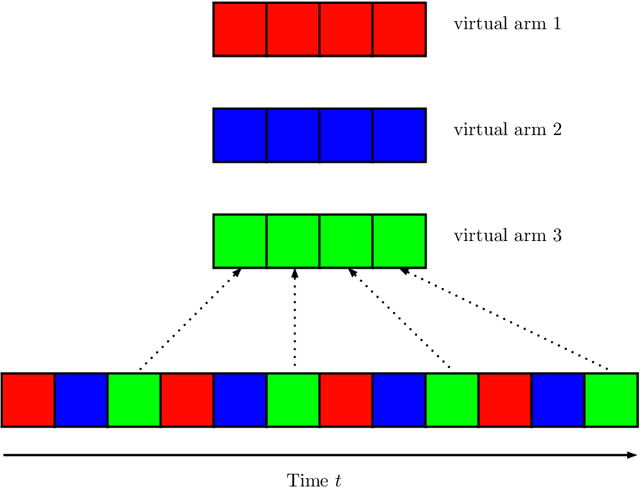
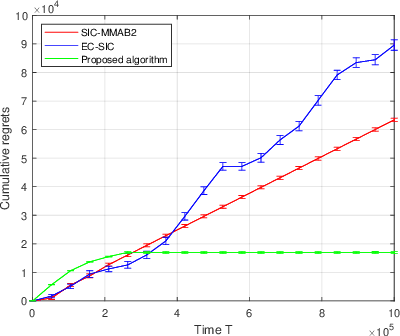
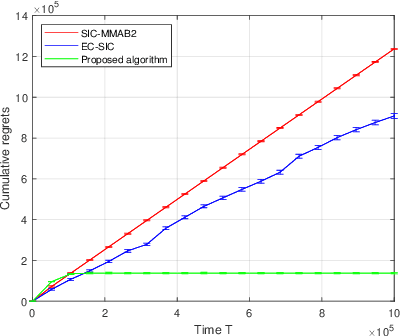
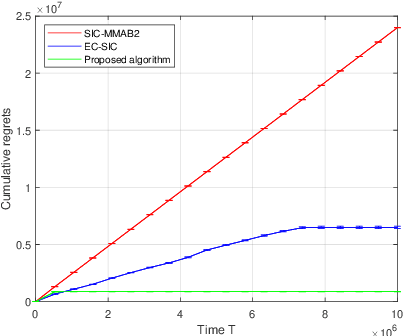
We propose a novel algorithm for multi-player multi-armed bandits without collision sensing information. Our algorithm circumvents two problems shared by all state-of-the-art algorithms: it does not need as an input a lower bound on the minimal expected reward of an arm, and its performance does not scale inversely proportionally to the minimal expected reward. We prove a theoretical regret upper bound to justify these claims. We complement our theoretical results with numerical experiments, showing that the proposed algorithm outperforms state-of-the-art in practice as well.
A High Performance, Low Complexity Algorithm for Multi-Player Bandits Without Collision Sensing Information
Feb 19, 2021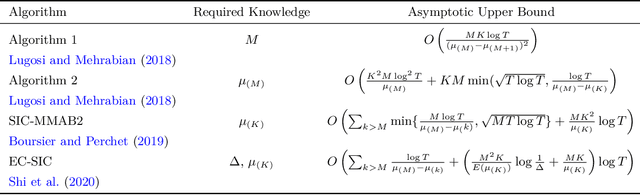


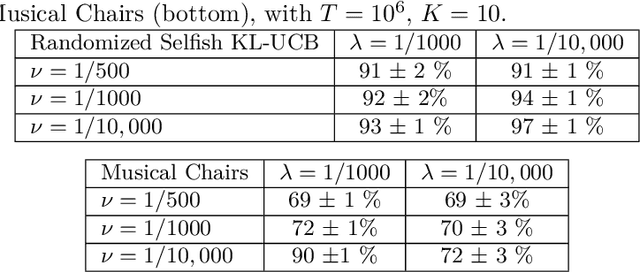
Motivated by applications in cognitive radio networks, we consider the decentralized multi-player multi-armed bandit problem, without collision nor sensing information. We propose Randomized Selfish KL-UCB, an algorithm with very low computational complexity, inspired by the Selfish KL-UCB algorithm, which has been abandoned as it provably performs sub-optimally in some cases. We subject Randomized Selfish KL-UCB to extensive numerical experiments showing that it far outperforms state-of-the-art algorithms in almost all environments, sometimes by several orders of magnitude, and without the additional knowledge required by state-of-the-art algorithms. We also emphasize the potential of this algorithm for the more realistic dynamic setting, and support our claims with further experiments. We believe that the low complexity and high performance of Randomized Selfish KL-UCB makes it the most suitable for implementation in practical systems amongst known algorithms.
MLPerf Mobile Inference Benchmark: Why Mobile AI Benchmarking Is Hard and What to Do About It
Dec 03, 2020

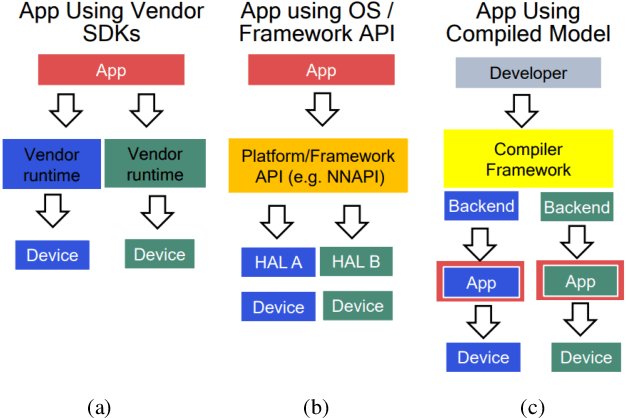
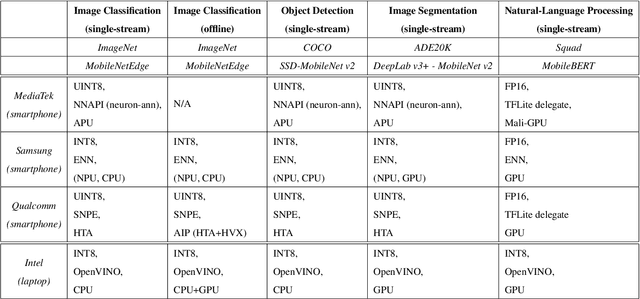
MLPerf Mobile is the first industry-standard open-source mobile benchmark developed by industry members and academic researchers to allow performance/accuracy evaluation of mobile devices with different AI chips and software stacks. The benchmark draws from the expertise of leading mobile-SoC vendors, ML-framework providers, and model producers. In this paper, we motivate the drive to demystify mobile-AI performance and present MLPerf Mobile's design considerations, architecture, and implementation. The benchmark comprises a suite of models that operate under standard models, data sets, quality metrics, and run rules. For the first iteration, we developed an app to provide an "out-of-the-box" inference-performance benchmark for computer vision and natural-language processing on mobile devices. MLPerf Mobile can serve as a framework for integrating future models, for customizing quality-target thresholds to evaluate system performance, for comparing software frameworks, and for assessing heterogeneous-hardware capabilities for machine learning, all fairly and faithfully with fully reproducible results.
Solving Bernoulli Rank-One Bandits with Unimodal Thompson Sampling
Dec 06, 2019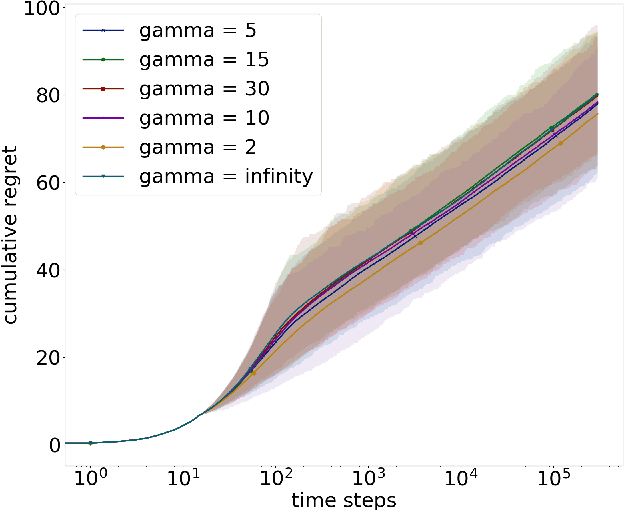
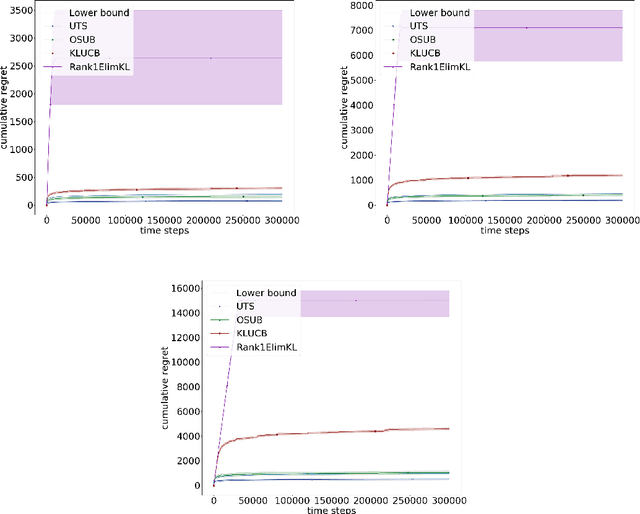
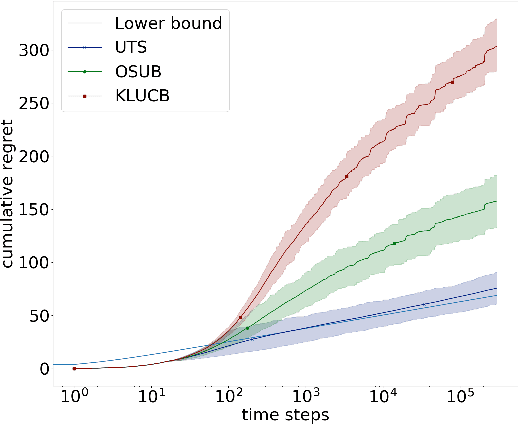
Stochastic Rank-One Bandits (Katarya et al, (2017a,b)) are a simple framework for regret minimization problems over rank-one matrices of arms. The initially proposed algorithms are proved to have logarithmic regret, but do not match the existing lower bound for this problem. We close this gap by first proving that rank-one bandits are a particular instance of unimodal bandits, and then providing a new analysis of Unimodal Thompson Sampling (UTS), initially proposed by Paladino et al (2017). We prove an asymptotically optimal regret bound on the frequentist regret of UTS and we support our claims with simulations showing the significant improvement of our method compared to the state-of-the-art.