Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimal Algorithms for Multi-Player Bandits without Collision Sensing Information
Paper and Code
Mar 24, 2021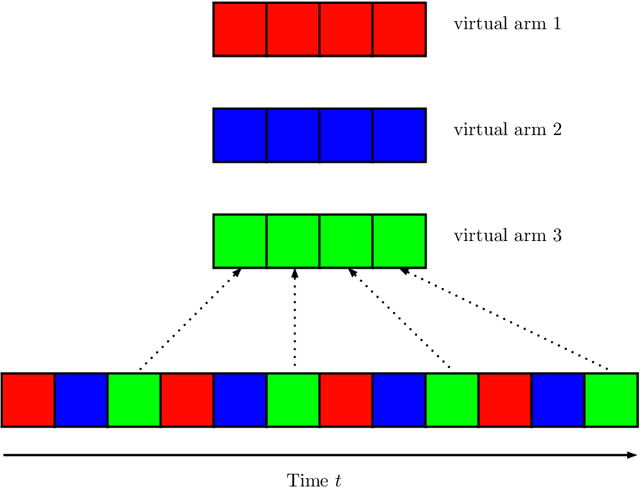
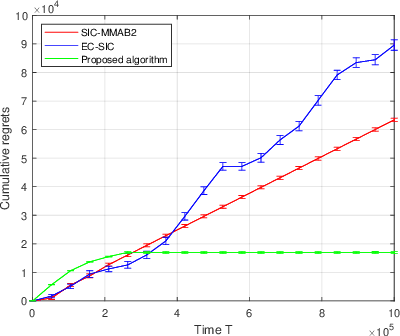
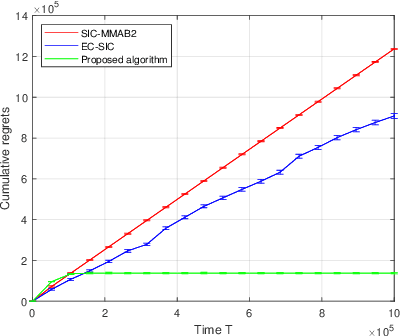
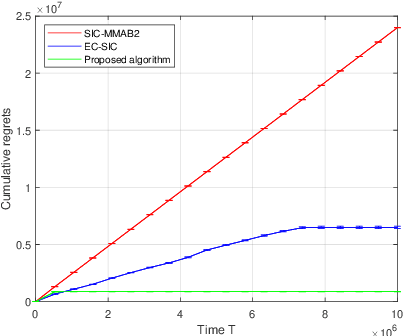
We propose a novel algorithm for multi-player multi-armed bandits without collision sensing information. Our algorithm circumvents two problems shared by all state-of-the-art algorithms: it does not need as an input a lower bound on the minimal expected reward of an arm, and its performance does not scale inversely proportionally to the minimal expected reward. We prove a theoretical regret upper bound to justify these claims. We complement our theoretical results with numerical experiments, showing that the proposed algorithm outperforms state-of-the-art in practice as well.
* 23 pages
View paper on