 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
Aug 06, 2024



Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78\% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Data Science Kitchen at GermEval 2021: A Fine Selection of Hand-Picked Features, Delivered Fresh from the Oven
Sep 06, 2021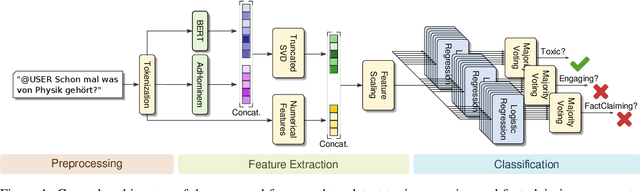
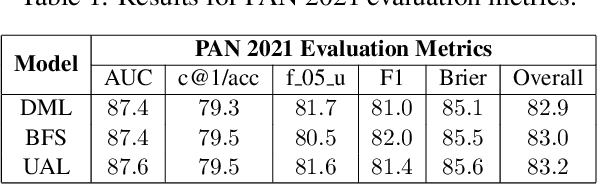
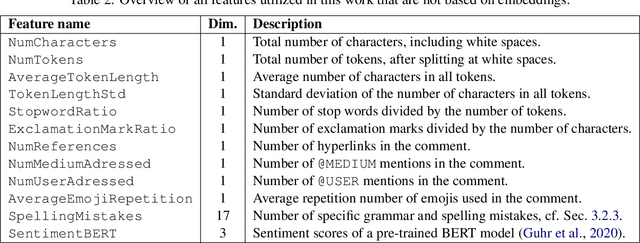
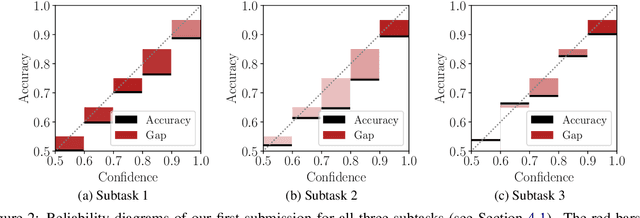
This paper presents the contribution of the Data Science Kitchen at GermEval 2021 shared task on the identification of toxic, engaging, and fact-claiming comments. The task aims at extending the identification of offensive language, by including additional subtasks that identify comments which should be prioritized for fact-checking by moderators and community managers. Our contribution focuses on a feature-engineering approach with a conventional classification backend. We combine semantic and writing style embeddings derived from pre-trained deep neural networks with additional numerical features, specifically designed for this task. Ensembles of Logistic Regression classifiers and Support Vector Machines are used to derive predictions for each subtask via a majority voting scheme. Our best submission achieved macro-averaged F1-scores of 66.8%, 69.9% and 72.5% for the identification of toxic, engaging, and fact-claiming comments.
PILOT: Introducing Transformers for Probabilistic Sound Event Localization
Jun 07, 2021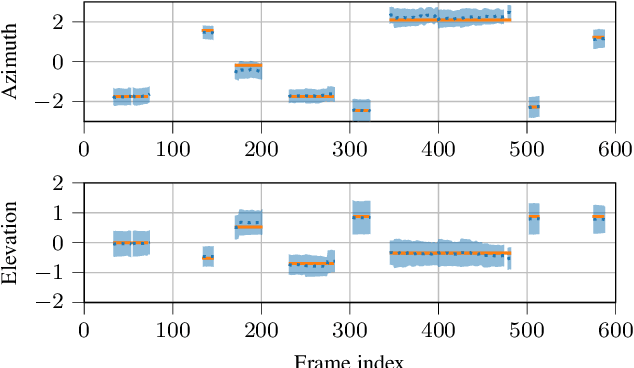
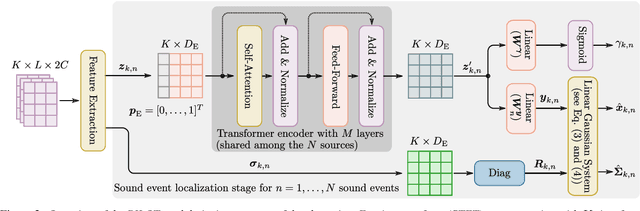
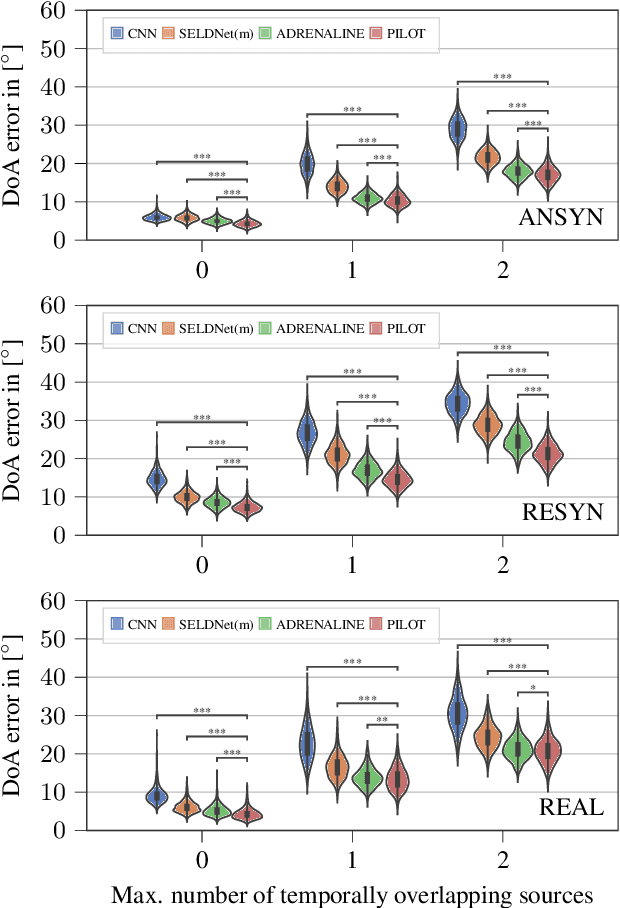
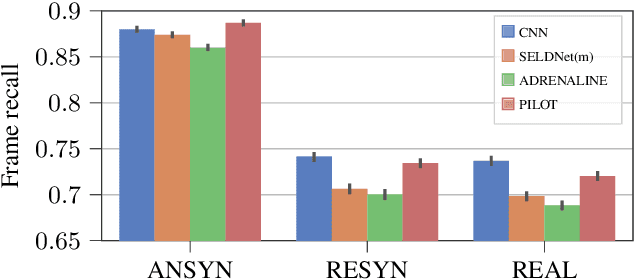
Sound event localization aims at estimating the positions of sound sources in the environment with respect to an acoustic receiver (e.g. a microphone array). Recent advances in this domain most prominently focused on utilizing deep recurrent neural networks. Inspired by the success of transformer architectures as a suitable alternative to classical recurrent neural networks, this paper introduces a novel transformer-based sound event localization framework, where temporal dependencies in the received multi-channel audio signals are captured via self-attention mechanisms. Additionally, the estimated sound event positions are represented as multivariate Gaussian variables, yielding an additional notion of uncertainty, which many previously proposed deep learning-based systems designed for this application do not provide. The framework is evaluated on three publicly available multi-source sound event localization datasets and compared against state-of-the-art methods in terms of localization error and event detection accuracy. It outperforms all competing systems on all datasets with statistical significant differences in performance.
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021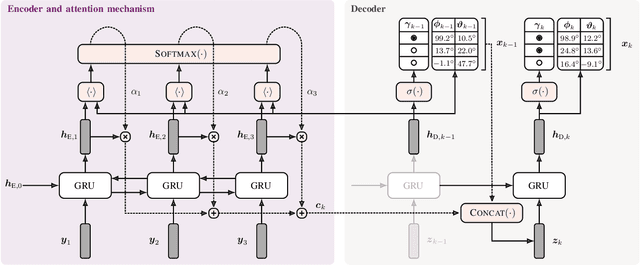
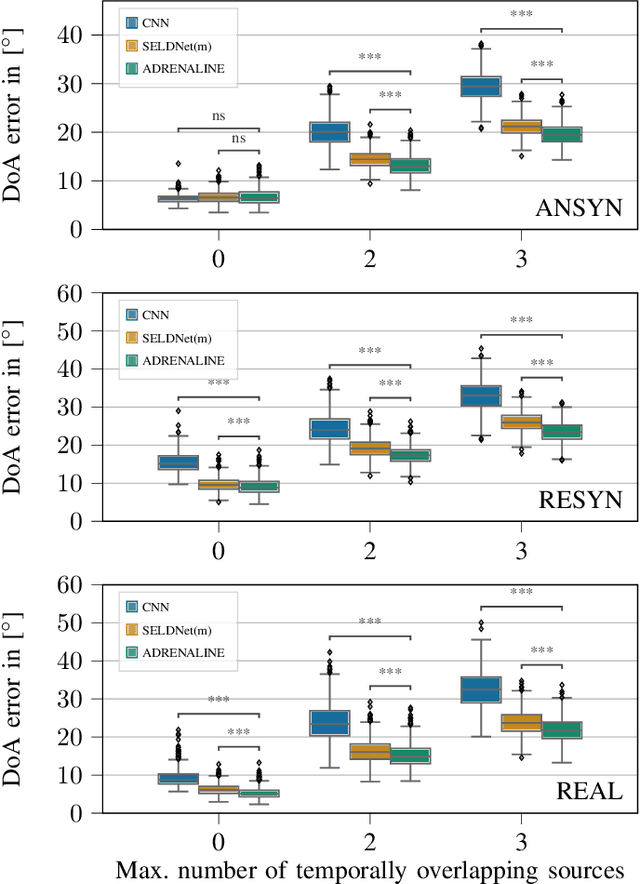
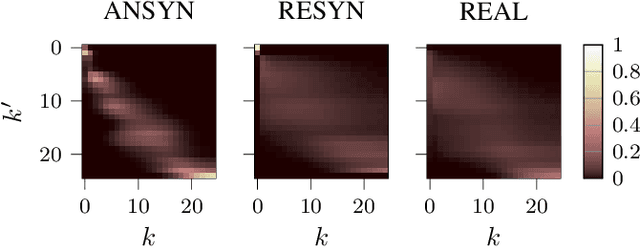
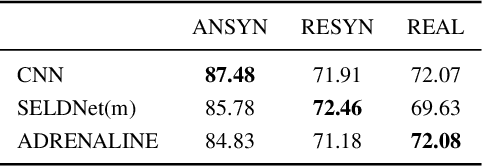
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 24, 2021
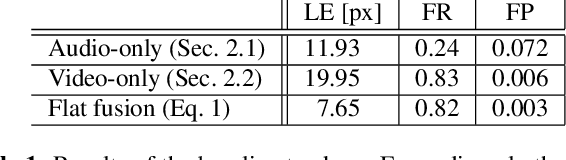
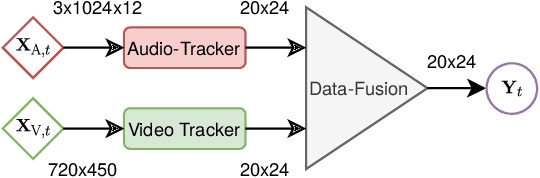
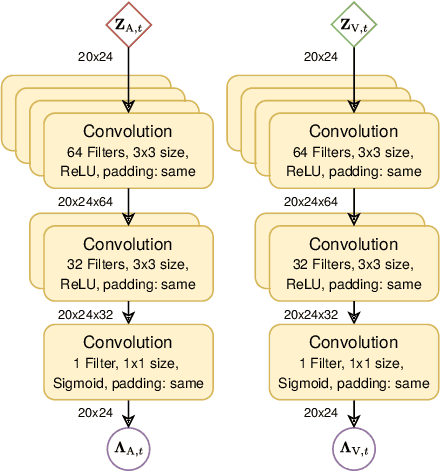
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
Audiovisual Speaker Tracking using Nonlinear Dynamical Systems with Dynamic Stream Weights
Mar 14, 2019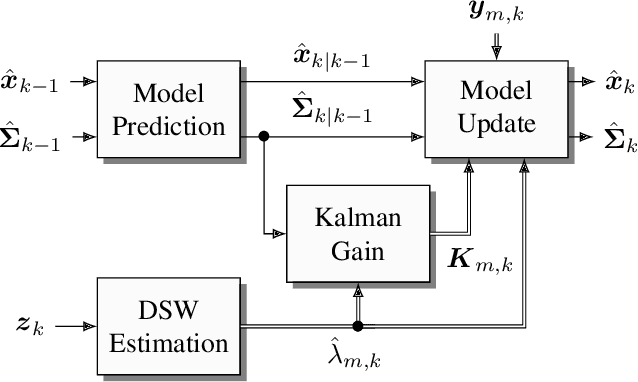
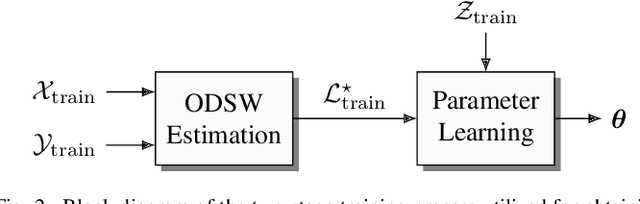

Data fusion plays an important role in many technical applications that require efficient processing of multimodal sensory observations. A prominent example is audiovisual signal processing, which has gained increasing attention in automatic speech recognition, speaker localization and related tasks. If appropriately combined with acoustic information, additional visual cues can help to improve the performance in these applications, especially under adverse acoustic conditions. A dynamic weighting of acoustic and visual streams based on instantaneous sensor reliability measures is an efficient approach to data fusion in this context. This paper presents a framework that extends the well-established theory of nonlinear dynamical systems with the notion of dynamic stream weights for an arbitrary number of sensory observations. It comprises a recursive state estimator based on the Gaussian filtering paradigm, which incorporates dynamic stream weights into a framework closely related to the extended Kalman filter. Additionally, a convex optimization approach to estimate oracle dynamic stream weights in fully observed dynamical systems utilizing a Dirichlet prior is presented. This serves as a basis for a generic parameter learning framework of dynamic stream weight estimators. The proposed system is application-independent and can be easily adapted to specific tasks and requirements. A study using audiovisual speaker tracking tasks is considered as an exemplary application in this work. An improved tracking performance of the dynamic stream weight-based estimation framework over state-of-the-art methods is demonstrated in the experiments.