 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating patient cohorts from electronic health records using two-step retrieval-augmented text-to-SQL generation
Feb 28, 2025Clinical cohort definition is crucial for patient recruitment and observational studies, yet translating inclusion/exclusion criteria into SQL queries remains challenging and manual. We present an automated system utilizing large language models that combines criteria parsing, two-level retrieval augmented generation with specialized knowledge bases, medical concept standardization, and SQL generation to retrieve patient cohorts with patient funnels. The system achieves 0.75 F1-score in cohort identification on EHR data, effectively capturing complex temporal and logical relationships. These results demonstrate the feasibility of automated cohort generation for epidemiological research.
Fact Finder -- Enhancing Domain Expertise of Large Language Models by Incorporating Knowledge Graphs
Aug 06, 2024



Recent advancements in Large Language Models (LLMs) have showcased their proficiency in answering natural language queries. However, their effectiveness is hindered by limited domain-specific knowledge, raising concerns about the reliability of their responses. We introduce a hybrid system that augments LLMs with domain-specific knowledge graphs (KGs), thereby aiming to enhance factual correctness using a KG-based retrieval approach. We focus on a medical KG to demonstrate our methodology, which includes (1) pre-processing, (2) Cypher query generation, (3) Cypher query processing, (4) KG retrieval, and (5) LLM-enhanced response generation. We evaluate our system on a curated dataset of 69 samples, achieving a precision of 78\% in retrieving correct KG nodes. Our findings indicate that the hybrid system surpasses a standalone LLM in accuracy and completeness, as verified by an LLM-as-a-Judge evaluation method. This positions the system as a promising tool for applications that demand factual correctness and completeness, such as target identification -- a critical process in pinpointing biological entities for disease treatment or crop enhancement. Moreover, its intuitive search interface and ability to provide accurate responses within seconds make it well-suited for time-sensitive, precision-focused research contexts. We publish the source code together with the dataset and the prompt templates used.
Retrieval augmented text-to-SQL generation for epidemiological question answering using electronic health records
Mar 14, 2024Electronic health records (EHR) and claims data are rich sources of real-world data that reflect patient health status and healthcare utilization. Querying these databases to answer epidemiological questions is challenging due to the intricacy of medical terminology and the need for complex SQL queries. Here, we introduce an end-to-end methodology that combines text-to-SQL generation with retrieval augmented generation (RAG) to answer epidemiological questions using EHR and claims data. We show that our approach, which integrates a medical coding step into the text-to-SQL process, significantly improves the performance over simple prompting. Our findings indicate that although current language models are not yet sufficiently accurate for unsupervised use, RAG offers a promising direction for improving their capabilities, as shown in a realistic industry setting.
Biomedical Data-to-Text Generation via Fine-Tuning Transformers
Sep 03, 2021
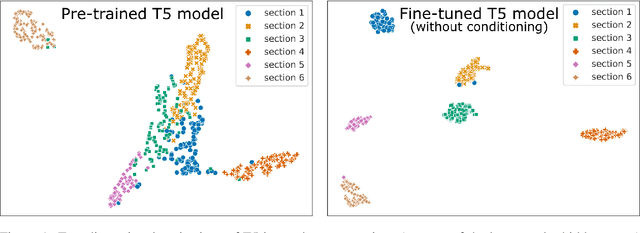
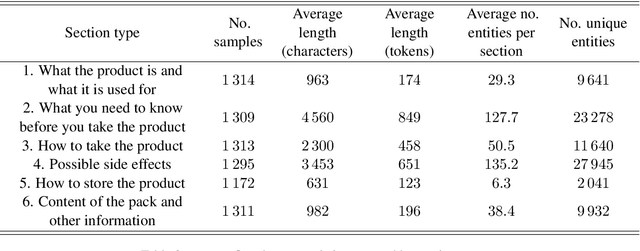
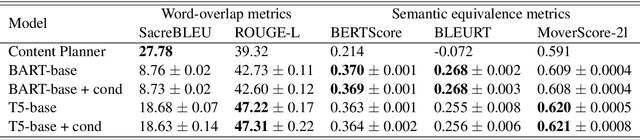
Data-to-text (D2T) generation in the biomedical domain is a promising - yet mostly unexplored - field of research. Here, we apply neural models for D2T generation to a real-world dataset consisting of package leaflets of European medicines. We show that fine-tuned transformers are able to generate realistic, multisentence text from data in the biomedical domain, yet have important limitations. We also release a new dataset (BioLeaflets) for benchmarking D2T generation models in the biomedical domain.
Discovering key topics from short, real-world medical inquiries via natural language processing and unsupervised learning
Dec 08, 2020
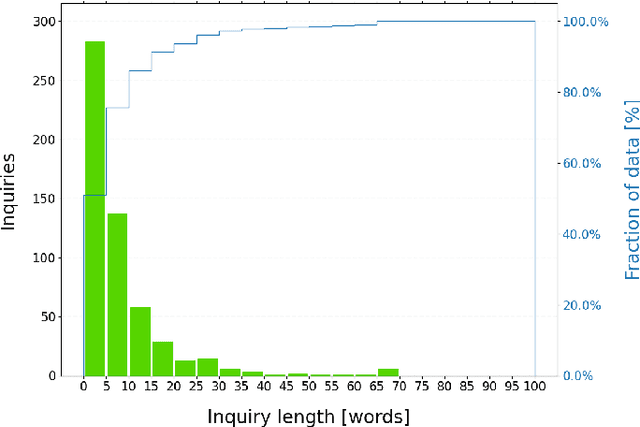
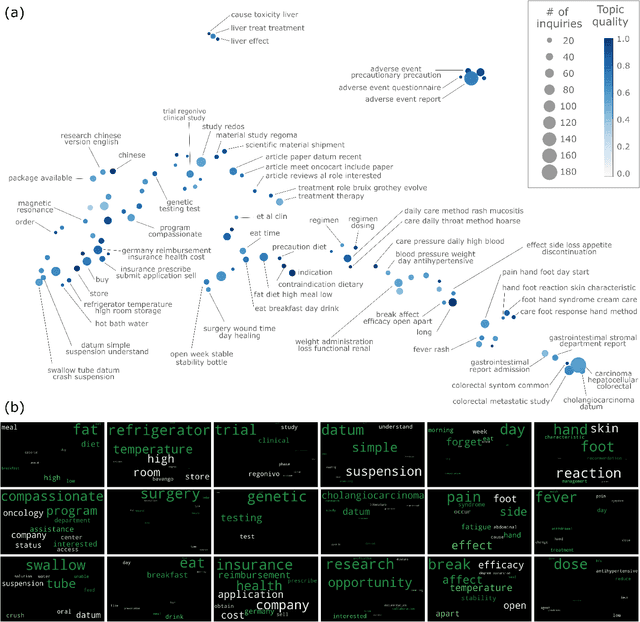
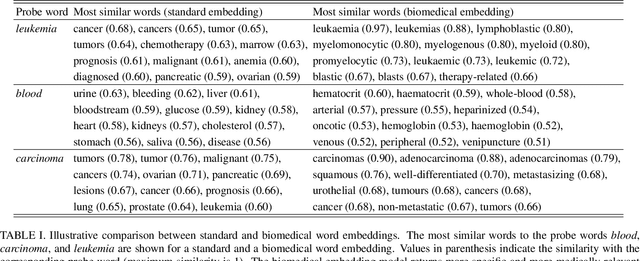
Millions of unsolicited medical inquiries are received by pharmaceutical companies every year. It has been hypothesized that these inquiries represent a treasure trove of information, potentially giving insight into matters regarding medicinal products and the associated medical treatments. However, due to the large volume and specialized nature of the inquiries, it is difficult to perform timely, recurrent, and comprehensive analyses. Here, we propose a machine learning approach based on natural language processing and unsupervised learning to automatically discover key topics in real-world medical inquiries from customers. This approach does not require ontologies nor annotations. The discovered topics are meaningful and medically relevant, as judged by medical information specialists, thus demonstrating that unsolicited medical inquiries are a source of valuable customer insights. Our work paves the way for the machine-learning-driven analysis of medical inquiries in the pharmaceutical industry, which ultimately aims at improving patient care.