 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability of Deep Neural Networks via discrete rough paths
Jan 19, 2022
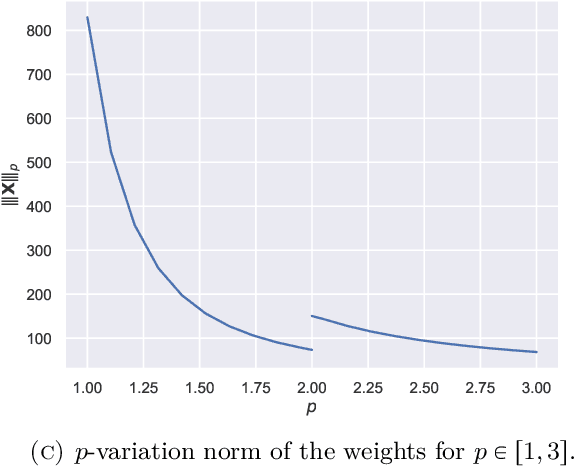
Using rough path techniques, we provide a priori estimates for the output of Deep Residual Neural Networks in terms of both the input data and the (trained) network weights. As trained network weights are typically very rough when seen as functions of the layer, we propose to derive stability bounds in terms of the total $p$-variation of trained weights for any $p\in[1,3]$. Unlike the $C^1$-theory underlying the neural ODE literature, our estimates remain bounded even in the limiting case of weights behaving like Brownian motions, as suggested in [arXiv:2105.12245]. Mathematically, we interpret residual neural network as solutions to (rough) difference equations, and analyse them based on recent results of discrete time signatures and rough path theory.
Reinforced optimal control
Nov 24, 2020
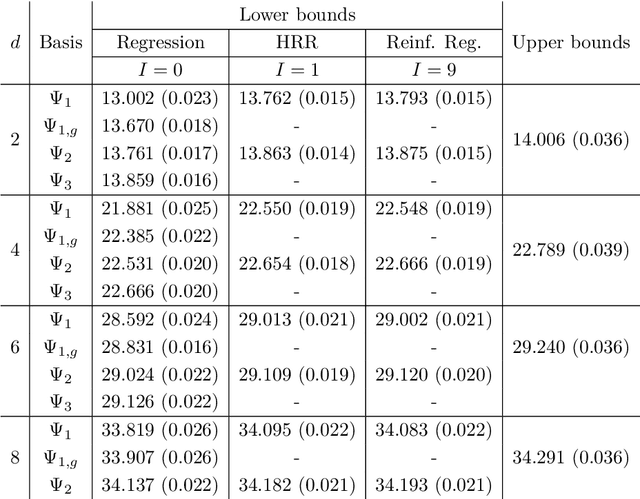
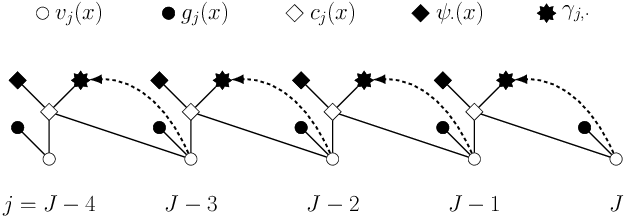
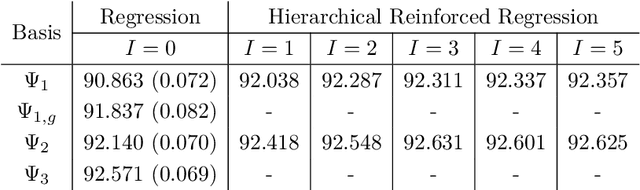
Least squares Monte Carlo methods are a popular numerical approximation method for solving stochastic control problems. Based on dynamic programming, their key feature is the approximation of the conditional expectation of future rewards by linear least squares regression. Hence, the choice of basis functions is crucial for the accuracy of the method. Earlier work by some of us [Belomestny, Schoenmakers, Spokoiny, Zharkynbay. Commun.~Math.~Sci., 18(1):109-121, 2020] proposes to \emph{reinforce} the basis functions in the case of optimal stopping problems by already computed value functions for later times, thereby considerably improving the accuracy with limited additional computational cost. We extend the reinforced regression method to a general class of stochastic control problems, while considerably improving the method's efficiency, as demonstrated by substantial numerical examples as well as theoretical analysis.
Deep calibration of rough stochastic volatility models
Oct 08, 2018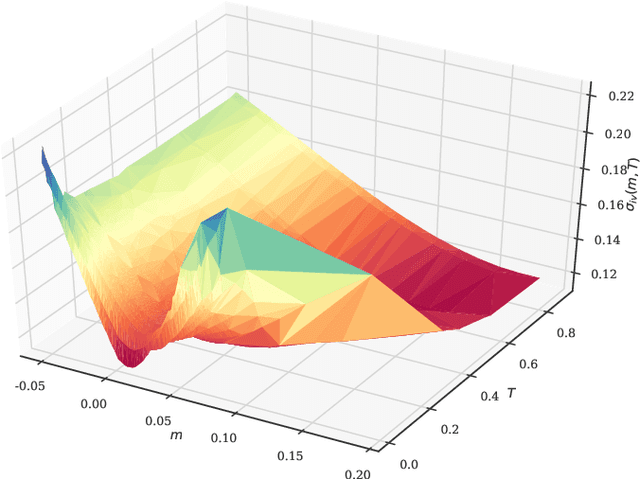
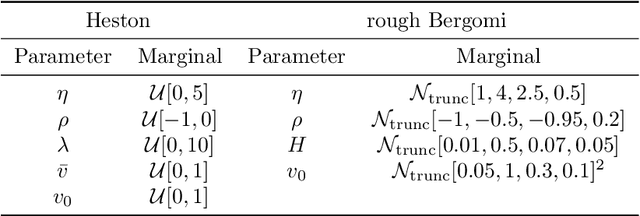
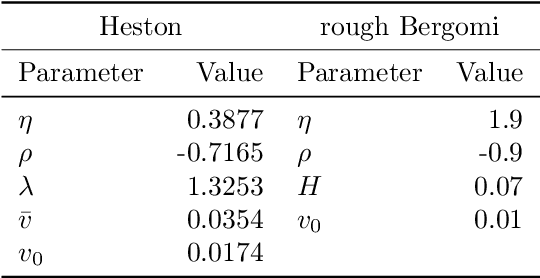
Sparked by Al\`os, Le\'on, and Vives (2007); Fukasawa (2011, 2017); Gatheral, Jaisson, and Rosenbaum (2018), so-called rough stochastic volatility models such as the rough Bergomi model by Bayer, Friz, and Gatheral (2016) constitute the latest evolution in option price modeling. Unlike standard bivariate diffusion models such as Heston (1993), these non-Markovian models with fractional volatility drivers allow to parsimoniously recover key stylized facts of market implied volatility surfaces such as the exploding power-law behaviour of the at-the-money volatility skew as time to maturity goes to zero. Standard model calibration routines rely on the repetitive evaluation of the map from model parameters to Black-Scholes implied volatility, rendering calibration of many (rough) stochastic volatility models prohibitively expensive since there the map can often only be approximated by costly Monte Carlo (MC) simulations (Bennedsen, Lunde, & Pakkanen, 2017; McCrickerd & Pakkanen, 2018; Bayer et al., 2016; Horvath, Jacquier, & Muguruza, 2017). As a remedy, we propose to combine a standard Levenberg-Marquardt calibration routine with neural network regression, replacing expensive MC simulations with cheap forward runs of a neural network trained to approximate the implied volatility map. Numerical experiments confirm the high accuracy and speed of our approach.