 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Extract Cross-Domain Aspects and Understanding Sentiments Using Large Language Models
Jan 15, 2025


Aspect-based sentiment analysis (ASBA) is a refined approach to sentiment analysis that aims to extract and classify sentiments based on specific aspects or features of a product, service, or entity. Unlike traditional sentiment analysis, which assigns a general sentiment score to entire reviews or texts, ABSA focuses on breaking down the text into individual components or aspects (e.g., quality, price, service) and evaluating the sentiment towards each. This allows for a more granular level of understanding of customer opinions, enabling businesses to pinpoint specific areas of strength and improvement. The process involves several key steps, including aspect extraction, sentiment classification, and aspect-level sentiment aggregation for a review paragraph or any other form that the users have provided. ABSA has significant applications in areas such as product reviews, social media monitoring, customer feedback analysis, and market research. By leveraging techniques from natural language processing (NLP) and machine learning, ABSA facilitates the extraction of valuable insights, enabling companies to make data-driven decisions that enhance customer satisfaction and optimize offerings. As ABSA evolves, it holds the potential to greatly improve personalized customer experiences by providing a deeper understanding of sentiment across various product aspects. In this work, we have analyzed the strength of LLMs for a complete cross-domain aspect-based sentiment analysis with the aim of defining the framework for certain products and using it for other similar situations. We argue that it is possible to that at an effectiveness of 92\% accuracy for the Aspect Based Sentiment Analysis dataset of SemEval-2015 Task 12.
Self-Segregating and Coordinated-Segregating Transformer for Focused Deep Multi-Modular Network for Visual Question Answering
Jun 25, 2020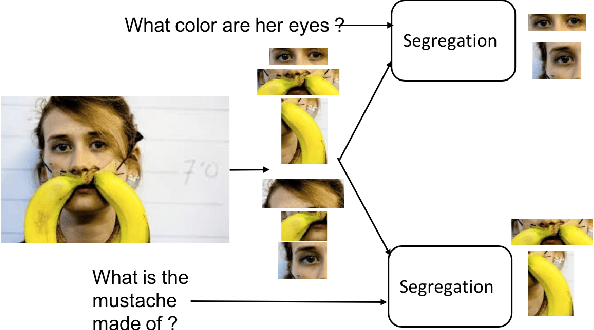
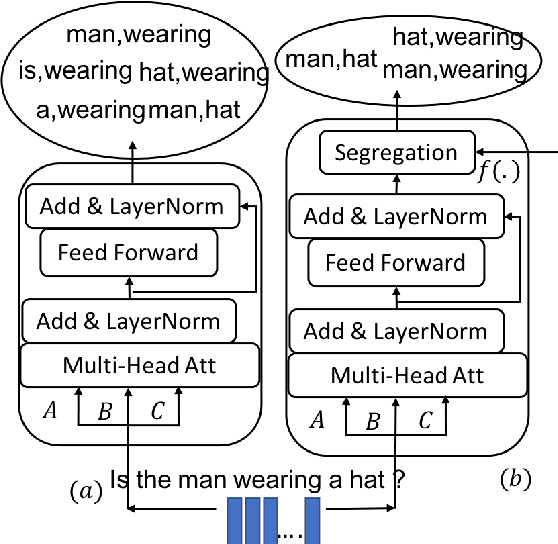
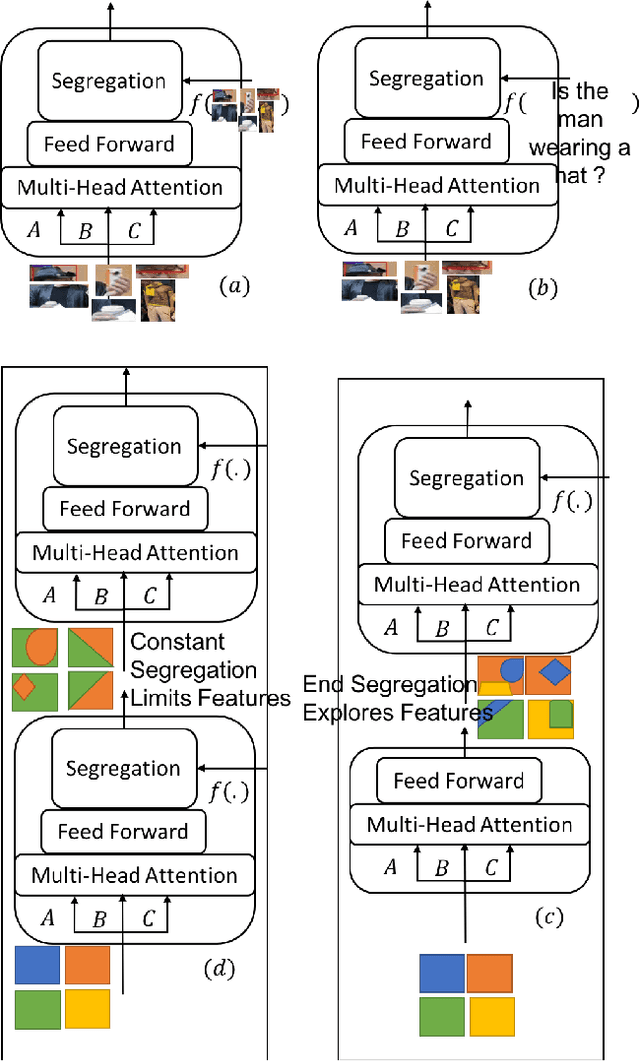
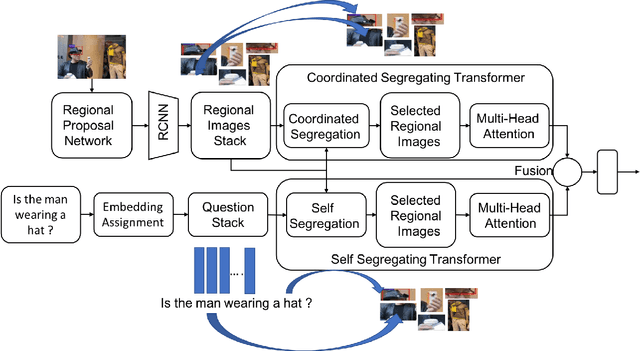
Attention mechanism has gained huge popularity due to its effectiveness in achieving high accuracy in different domains. But attention is opportunistic and is not justified by the content or usability of the content. Transformer like structure creates all/any possible attention(s). We define segregating strategies that can prioritize the contents for the applications for enhancement of performance. We defined two strategies: Self-Segregating Transformer (SST) and Coordinated-Segregating Transformer (CST) and used it to solve visual question answering application. Self-segregation strategy for attention contributes in better understanding and filtering the information that can be most helpful for answering the question and create diversity of visual-reasoning for attention. This work can easily be used in many other applications that involve repetition and multiple frames of features and would reduce the commonality of the attentions to a great extent. Visual Question Answering (VQA) requires understanding and coordination of both images and textual interpretations. Experiments demonstrate that segregation strategies for cascaded multi-head transformer attention outperforms many previous works and achieved considerable improvement for VQA-v2 dataset benchmark.
SACT: Self-Aware Multi-Space Feature Composition Transformer for Multinomial Attention for Video Captioning
Jun 25, 2020


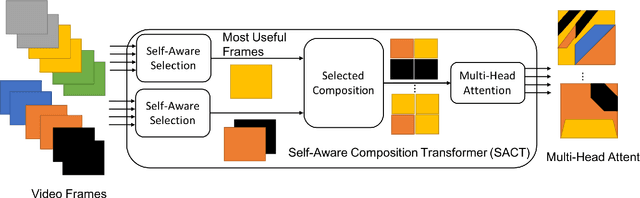
Video captioning works on the two fundamental concepts, feature detection and feature composition. While modern day transformers are beneficial in composing features, they lack the fundamental problems of selecting and understanding of the contents. As the feature length increases, it becomes increasingly important to include provisions for improved capturing of the pertinent contents. In this work, we have introduced a new concept of Self-Aware Composition Transformer (SACT) that is capable of generating Multinomial Attention (MultAtt) which is a way of generating distributions of various combinations of frames. Also, multi-head attention transformer works on the principle of combining all possible contents for attention, which is good for natural language classification, but has limitations for video captioning. Video contents have repetitions and require parsing of important contents for better content composition. In this work, we have introduced SACT for more selective attention and combined them for different attention heads for better capturing of the usable contents for any applications. To address the problem of diversification and encourage selective utilization, we propose the Self-Aware Composition Transformer model for dense video captioning and apply the technique on two benchmark datasets like ActivityNet and YouCookII.
ReLGAN: Generalization of Consistency for GAN with Disjoint Constraints and Relative Learning of Generative Processes for Multiple Transformation Learning
Jun 14, 2020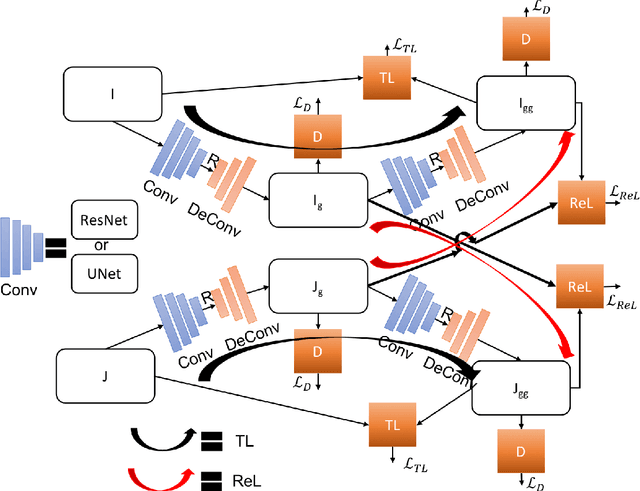
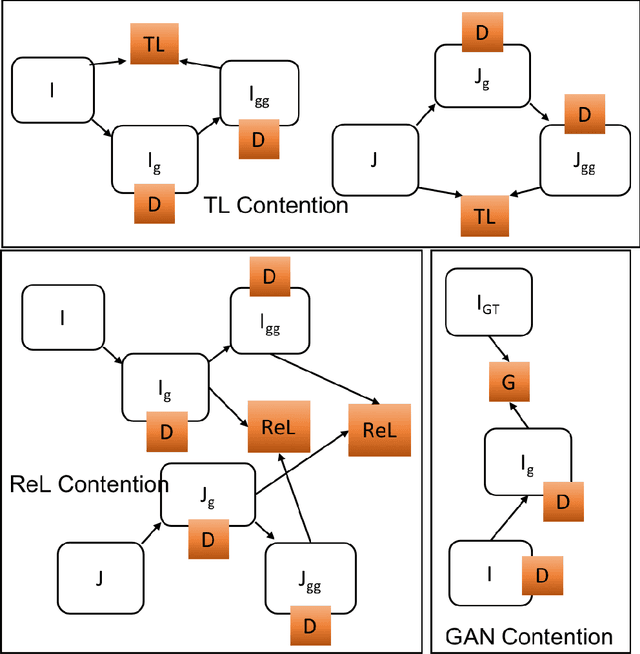

Image to image transformation has gained popularity from different research communities due to its enormous impact on different applications, including medical. In this work, we have introduced a generalized scheme for consistency for GAN architectures with two new concepts of Transformation Learning (TL) and Relative Learning (ReL) for enhanced learning image transformations. Consistency for GAN architectures suffered from inadequate constraints and failed to learn multiple and multi-modal transformations, which is inevitable for many medical applications. The main drawback is that it focused on creating an intermediate and workable hybrid, which is not permissible for the medical applications which focus on minute details. Another drawback is the weak interrelation between the two learning phases and TL and ReL have introduced improved coordination among them. We have demonstrated the capability of the novel network framework on public datasets. We emphasized that our novel architecture produced an improved neural image transformation version for the image, which is more acceptable to the medical community. Experiments and results demonstrated the effectiveness of our framework with enhancement compared to the previous works.
Gaussian Smoothen Semantic Features (GSSF) -- Exploring the Linguistic Aspects of Visual Captioning in Indian Languages (Bengali) Using MSCOCO Framework
Feb 16, 2020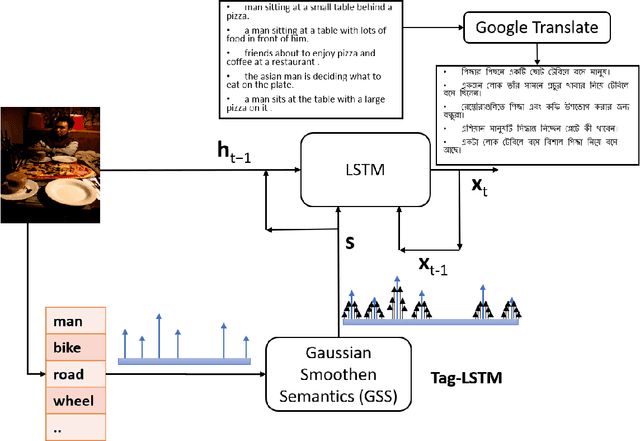


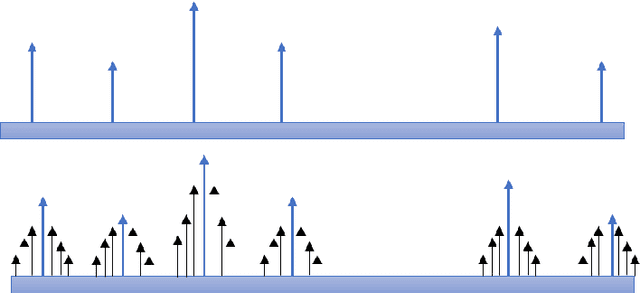
In this work, we have introduced Gaussian Smoothen Semantic Features (GSSF) for Better Semantic Selection for Indian regional language-based image captioning and introduced a procedure where we used the existing translation and English crowd-sourced sentences for training. We have shown that this architecture is a promising alternative source, where there is a crunch in resources. Our main contribution of this work is the development of deep learning architectures for the Bengali language (is the fifth widely spoken language in the world) with a completely different grammar and language attributes. We have shown that these are working well for complex applications like language generation from image contexts and can diversify the representation through introducing constraints, more extensive features, and unique feature spaces. We also established that we could achieve absolute precision and diversity when we use smoothened semantic tensor with the traditional LSTM and feature decomposition networks. With better learning architecture, we succeeded in establishing an automated algorithm and assessment procedure that can help in the evaluation of competent applications without the requirement for expertise and human intervention.
MRRC: Multiple Role Representation Crossover Interpretation for Image Captioning With R-CNN Feature Distribution Composition (FDC)
Feb 15, 2020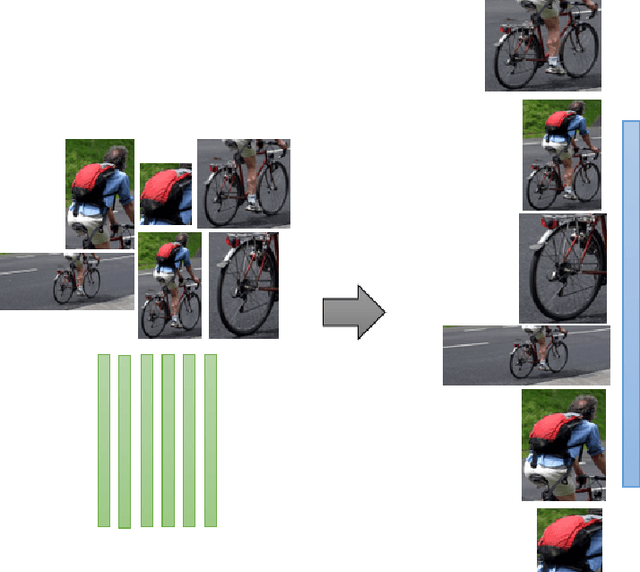


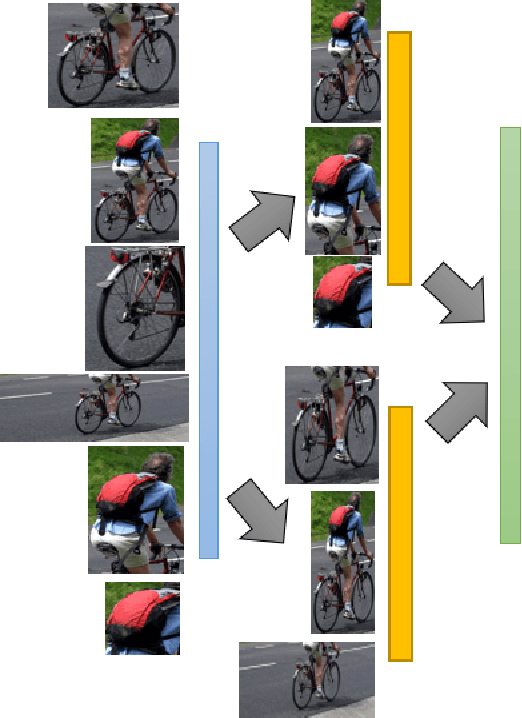
While image captioning through machines requires structured learning and basis for interpretation, improvement requires multiple context understanding and processing in a meaningful way. This research will provide a novel concept for context combination and will impact many applications to deal visual features as an equivalence of descriptions of objects, activities and events. There are three components of our architecture: Feature Distribution Composition (FDC) Layer Attention, Multiple Role Representation Crossover (MRRC) Attention Layer and the Language Decoder. FDC Layer Attention helps in generating the weighted attention from RCNN features, MRRC Attention Layer acts as intermediate representation processing and helps in generating the next word attention, while Language Decoder helps in estimation of the likelihood for the next probable word in the sentence. We demonstrated effectiveness of FDC, MRRC, regional object feature attention and reinforcement learning for effective learning to generate better captions from images. The performance of our model enhanced previous performances by 35.3\% and created a new standard and theory for representation generation based on logic, better interpretability and contexts.
aiTPR: Attribute Interaction-Tensor Product Representation for Image Caption
Jan 27, 2020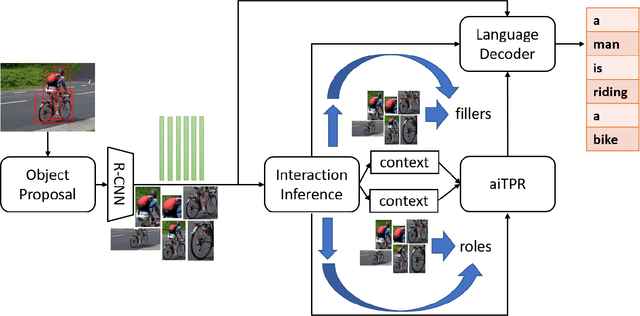
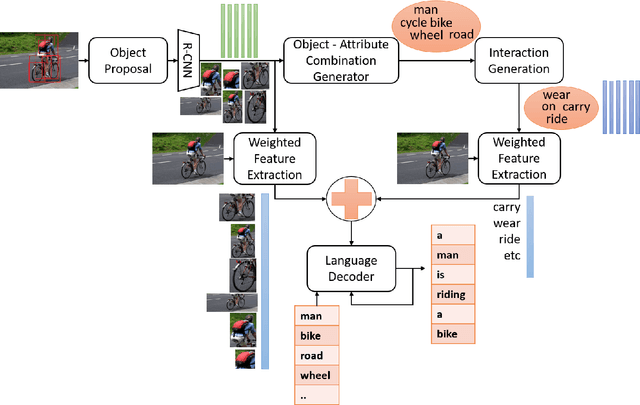
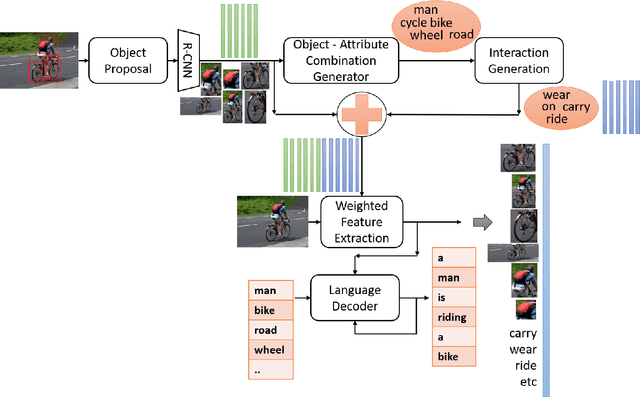

Region visual features enhance the generative capability of the machines based on features, however they lack proper interaction attentional perceptions and thus ends up with biased or uncorrelated sentences or pieces of misinformation. In this work, we propose Attribute Interaction-Tensor Product Representation (aiTPR) which is a convenient way of gathering more information through orthogonal combination and learning the interactions as physical entities (tensors) and improving the captions. Compared to previous works, where features are added up to undefined feature spaces, TPR helps in maintaining sanity in combinations and orthogonality helps in defining familiar spaces. We have introduced a new concept layer that defines the objects and also their interactions that can play a crucial role in determination of different descriptions. The interaction portions have contributed heavily for better caption quality and has out-performed different previous works on this domain and MSCOCO dataset. We introduced, for the first time, the notion of combining regional image features and abstracted interaction likelihood embedding for image captioning.
CRUR: Coupled-Recurrent Unit for Unification, Conceptualization and Context Capture for Language Representation -- A Generalization of Bi Directional LSTM
Nov 22, 2019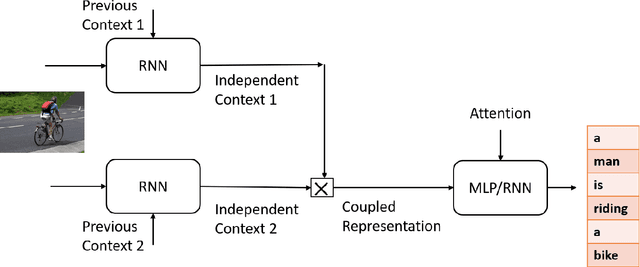

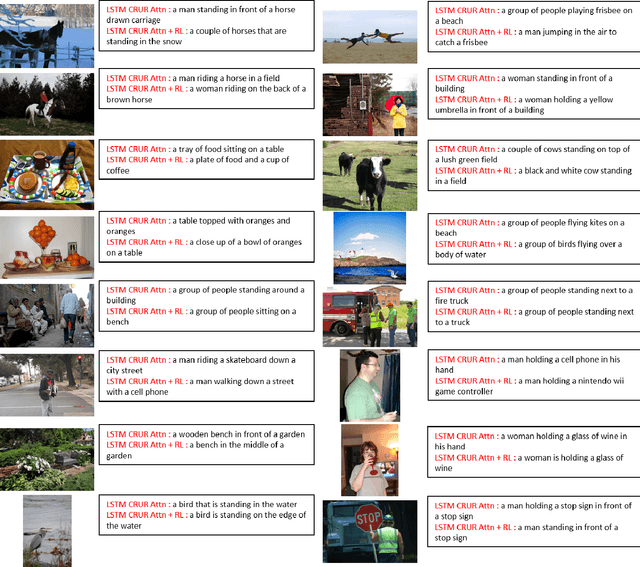
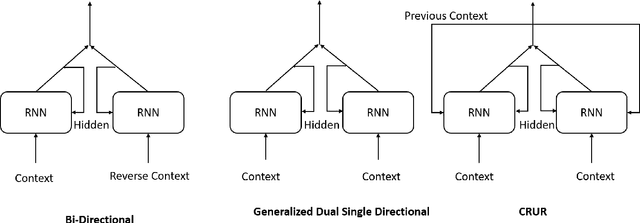
In this work we have analyzed a novel concept of sequential binding based learning capable network based on the coupling of recurrent units with Bayesian prior definition. The coupling structure encodes to generate efficient tensor representations that can be decoded to generate efficient sentences and can describe certain events. These descriptions are derived from structural representations of visual features of images and media. An elaborated study of the different types of coupling recurrent structures are studied and some insights of their performance are provided. Supervised learning performance for natural language processing is judged based on statistical evaluations, however, the truth is perspective, and in this case the qualitative evaluations reveal the real capability of the different architectural strengths and variations. Bayesian prior definition of different embedding helps in better characterization of the sentences based on the natural language structure related to parts of speech and other semantic level categorization in a form which is machine interpret-able and inherits the characteristics of the Tensor Representation binding and unbinding based on the mutually orthogonality. Our approach has surpassed some of the existing basic works related to image captioning.
TPsgtR: Neural-Symbolic Tensor Product Scene-Graph-Triplet Representation for Image Captioning
Nov 22, 2019

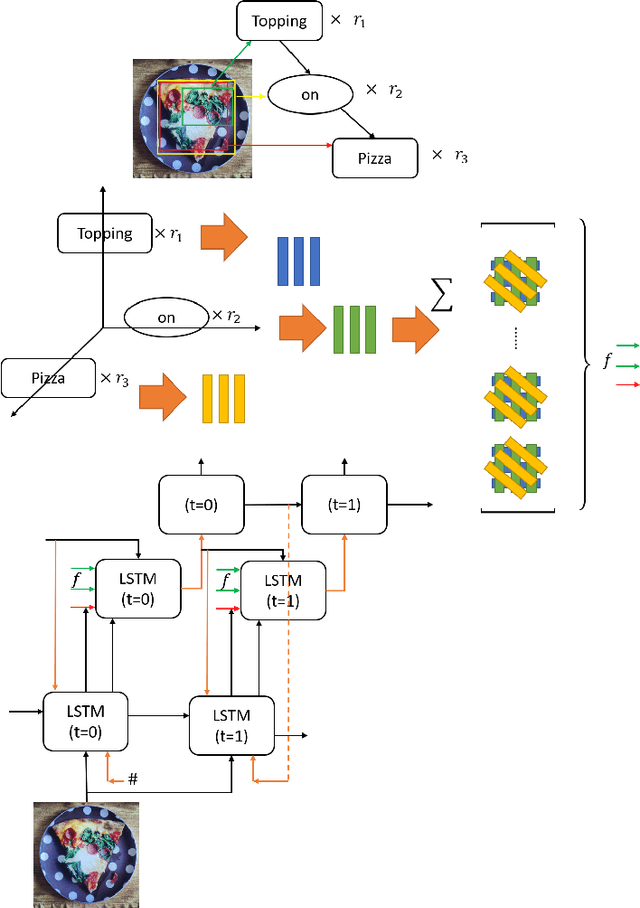
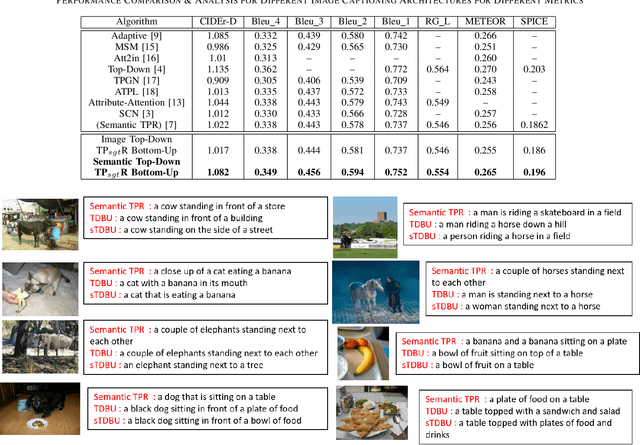
Image captioning can be improved if the structure of the graphical representations can be formulated with conceptual positional binding. In this work, we have introduced a novel technique for caption generation using the neural-symbolic encoding of the scene-graphs, derived from regional visual information of the images and we call it Tensor Product Scene-Graph-Triplet Representation (TP$_{sgt}$R). While, most of the previous works concentrated on identification of the object features in images, we introduce a neuro-symbolic embedding that can embed identified relationships among different regions of the image into concrete forms, instead of relying on the model to compose for any/all combinations. These neural symbolic representation helps in better definition of the neural symbolic space for neuro-symbolic attention and can be transformed to better captions. With this approach, we introduced two novel architectures (TP$_{sgt}$R-TDBU and TP$_{sgt}$R-sTDBU) for comparison and experiment result demonstrates that our approaches outperformed the other models, and generated captions are more comprehensive and natural.
Feature Fusion Effects of Tensor Product Representation on (De)Compositional Network for Caption Generation for Images
Dec 17, 2018


Progress in image captioning is gradually getting complex as researchers try to generalized the model and define the representation between visual features and natural language processing. This work tried to define such kind of relationship in the form of representation called Tensor Product Representation (TPR) which generalized the scheme of language modeling and structuring the linguistic attributes (related to grammar and parts of speech of language) which will provide a much better structure and grammatically correct sentence. TPR enables better and unique representation and structuring of the feature space and will enable better sentence composition from these representations. A large part of the different ways of defining and improving these TPR are discussed and their performance with respect to the traditional procedures and feature representations are evaluated for image captioning application. The new models achieved considerable improvement than the corresponding previous architectures.