 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRUR: Coupled-Recurrent Unit for Unification, Conceptualization and Context Capture for Language Representation -- A Generalization of Bi Directional LSTM
Paper and Code
Nov 22, 2019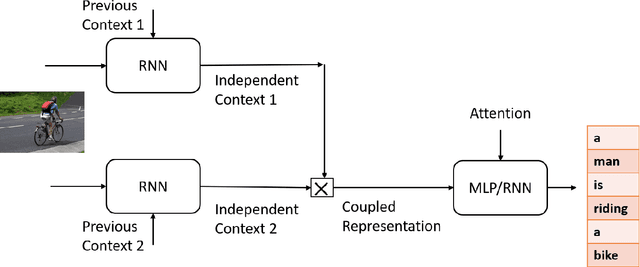

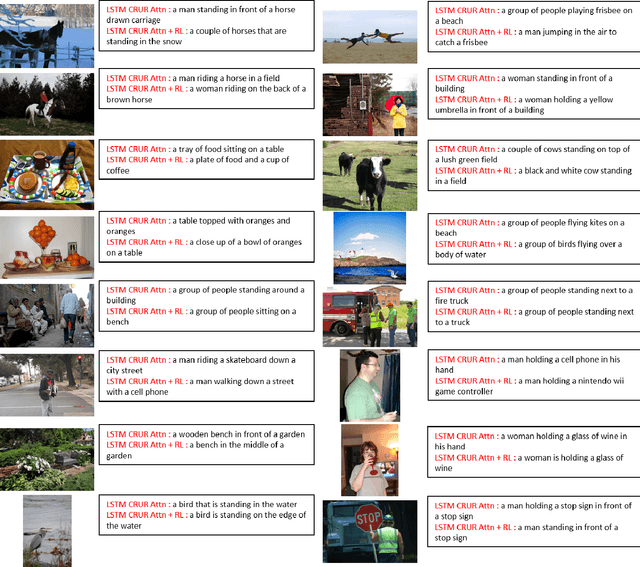
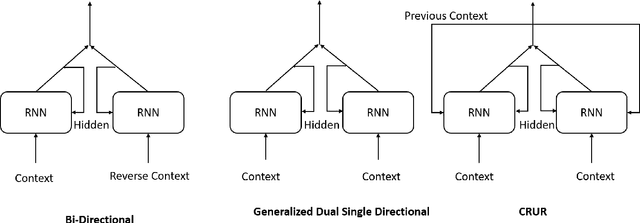
In this work we have analyzed a novel concept of sequential binding based learning capable network based on the coupling of recurrent units with Bayesian prior definition. The coupling structure encodes to generate efficient tensor representations that can be decoded to generate efficient sentences and can describe certain events. These descriptions are derived from structural representations of visual features of images and media. An elaborated study of the different types of coupling recurrent structures are studied and some insights of their performance are provided. Supervised learning performance for natural language processing is judged based on statistical evaluations, however, the truth is perspective, and in this case the qualitative evaluations reveal the real capability of the different architectural strengths and variations. Bayesian prior definition of different embedding helps in better characterization of the sentences based on the natural language structure related to parts of speech and other semantic level categorization in a form which is machine interpret-able and inherits the characteristics of the Tensor Representation binding and unbinding based on the mutually orthogonality. Our approach has surpassed some of the existing basic works related to image captioning.