 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRRC: Multiple Role Representation Crossover Interpretation for Image Captioning With R-CNN Feature Distribution Composition (FDC)
Paper and Code
Feb 15, 2020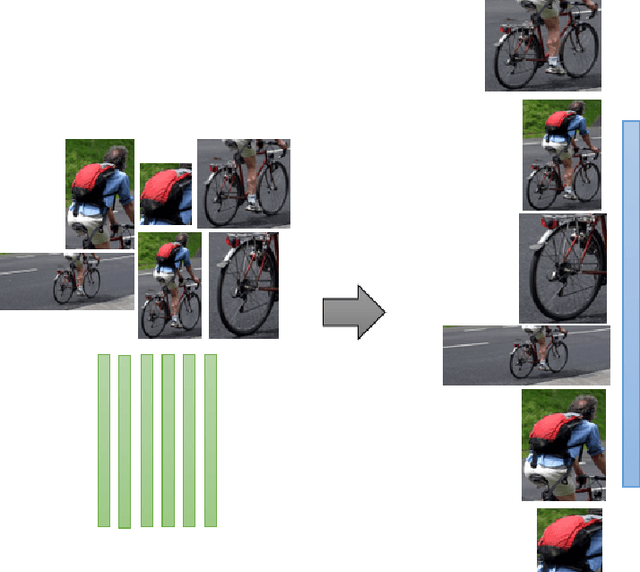


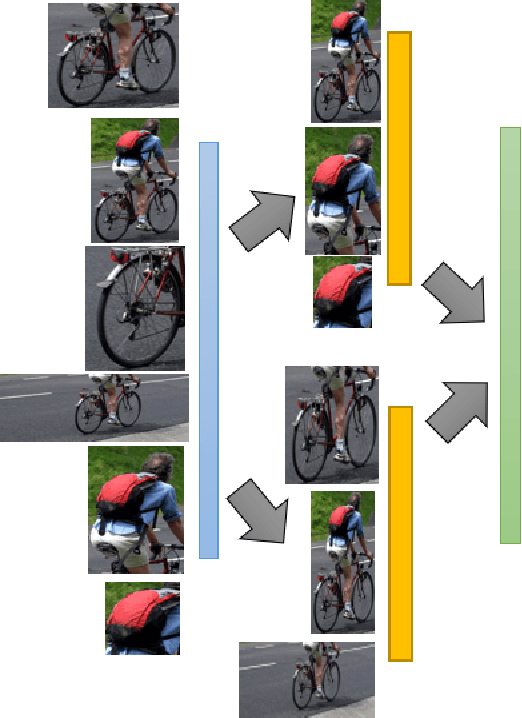
While image captioning through machines requires structured learning and basis for interpretation, improvement requires multiple context understanding and processing in a meaningful way. This research will provide a novel concept for context combination and will impact many applications to deal visual features as an equivalence of descriptions of objects, activities and events. There are three components of our architecture: Feature Distribution Composition (FDC) Layer Attention, Multiple Role Representation Crossover (MRRC) Attention Layer and the Language Decoder. FDC Layer Attention helps in generating the weighted attention from RCNN features, MRRC Attention Layer acts as intermediate representation processing and helps in generating the next word attention, while Language Decoder helps in estimation of the likelihood for the next probable word in the sentence. We demonstrated effectiveness of FDC, MRRC, regional object feature attention and reinforcement learning for effective learning to generate better captions from images. The performance of our model enhanced previous performances by 35.3\% and created a new standard and theory for representation generation based on logic, better interpretability and contexts.