 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPsgtR: Neural-Symbolic Tensor Product Scene-Graph-Triplet Representation for Image Captioning
Paper and Code
Nov 22, 2019

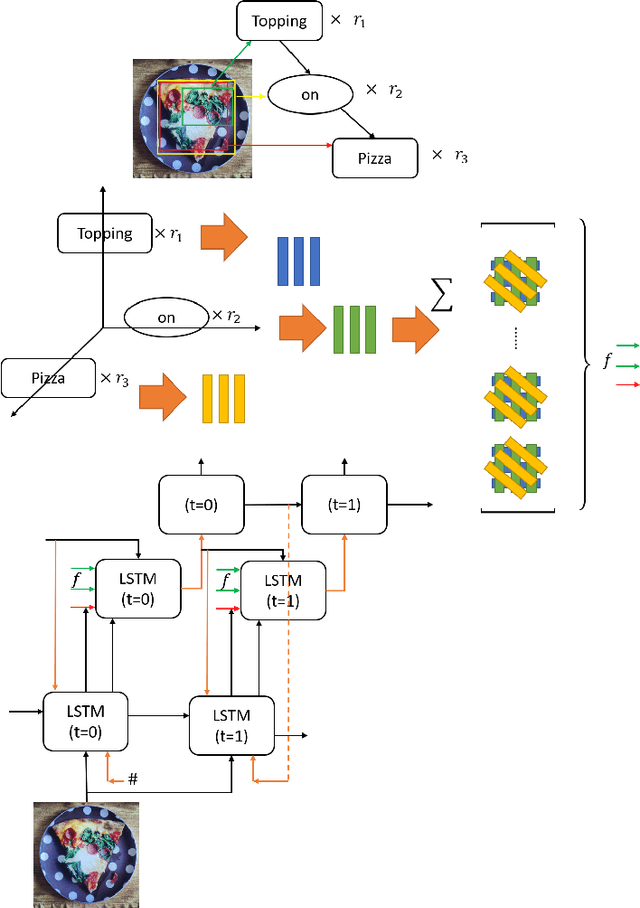
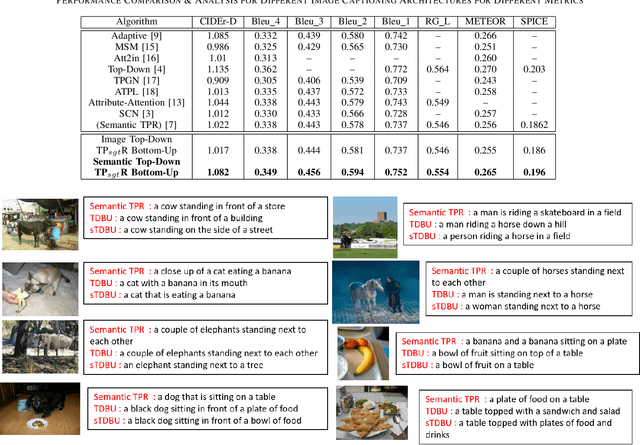
Image captioning can be improved if the structure of the graphical representations can be formulated with conceptual positional binding. In this work, we have introduced a novel technique for caption generation using the neural-symbolic encoding of the scene-graphs, derived from regional visual information of the images and we call it Tensor Product Scene-Graph-Triplet Representation (TP$_{sgt}$R). While, most of the previous works concentrated on identification of the object features in images, we introduce a neuro-symbolic embedding that can embed identified relationships among different regions of the image into concrete forms, instead of relying on the model to compose for any/all combinations. These neural symbolic representation helps in better definition of the neural symbolic space for neuro-symbolic attention and can be transformed to better captions. With this approach, we introduced two novel architectures (TP$_{sgt}$R-TDBU and TP$_{sgt}$R-sTDBU) for comparison and experiment result demonstrates that our approaches outperformed the other models, and generated captions are more comprehensive and natural.