 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Segregating and Coordinated-Segregating Transformer for Focused Deep Multi-Modular Network for Visual Question Answering
Paper and Code
Jun 25, 2020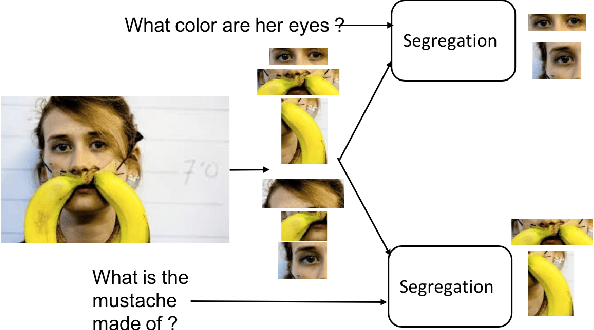
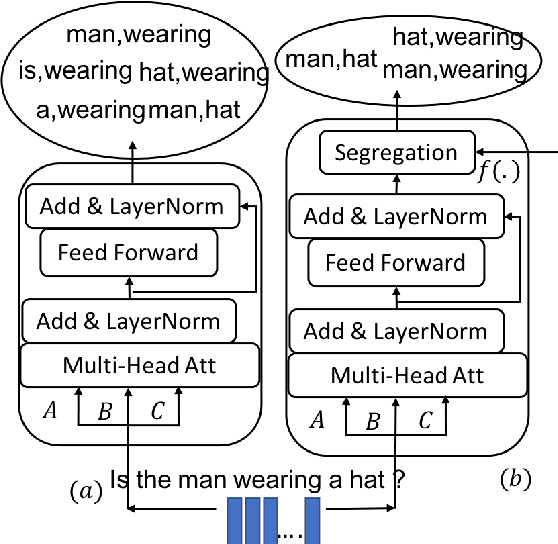
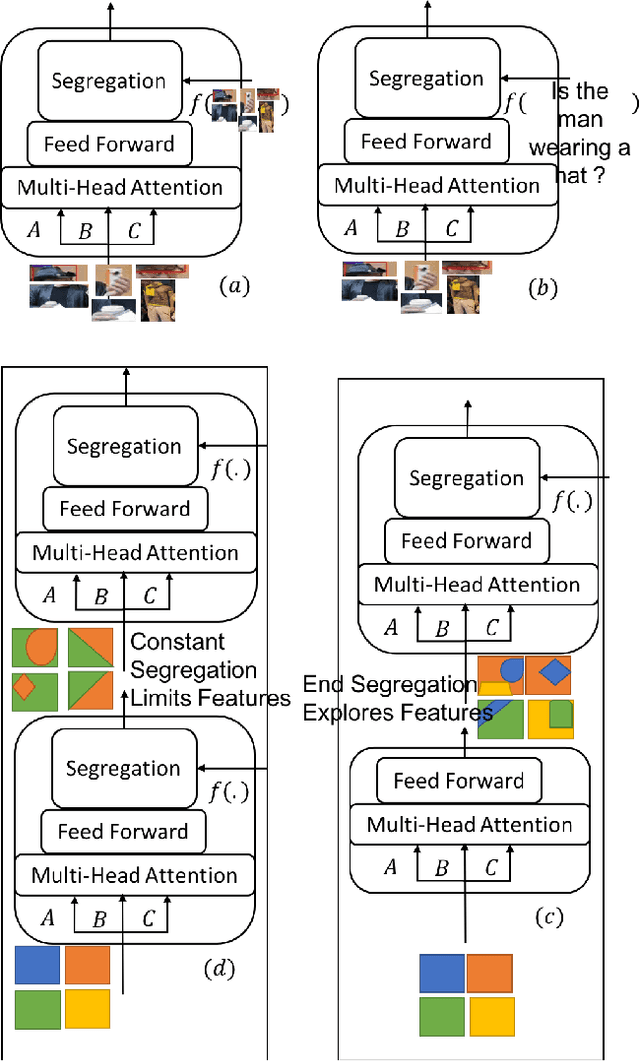
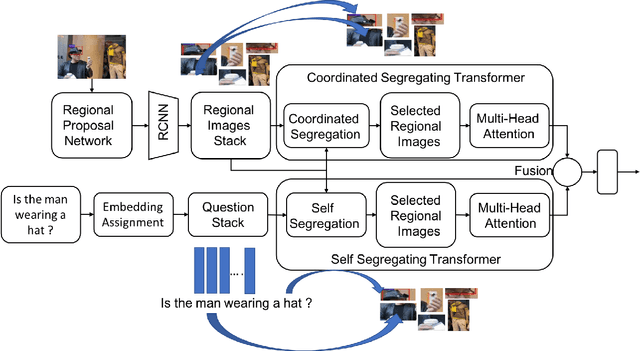
Attention mechanism has gained huge popularity due to its effectiveness in achieving high accuracy in different domains. But attention is opportunistic and is not justified by the content or usability of the content. Transformer like structure creates all/any possible attention(s). We define segregating strategies that can prioritize the contents for the applications for enhancement of performance. We defined two strategies: Self-Segregating Transformer (SST) and Coordinated-Segregating Transformer (CST) and used it to solve visual question answering application. Self-segregation strategy for attention contributes in better understanding and filtering the information that can be most helpful for answering the question and create diversity of visual-reasoning for attention. This work can easily be used in many other applications that involve repetition and multiple frames of features and would reduce the commonality of the attentions to a great extent. Visual Question Answering (VQA) requires understanding and coordination of both images and textual interpretations. Experiments demonstrate that segregation strategies for cascaded multi-head transformer attention outperforms many previous works and achieved considerable improvement for VQA-v2 dataset benchmark.