 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSACT: Self-Aware Multi-Space Feature Composition Transformer for Multinomial Attention for Video Captioning
Paper and Code
Jun 25, 2020


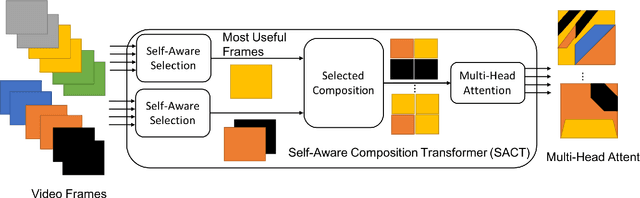
Video captioning works on the two fundamental concepts, feature detection and feature composition. While modern day transformers are beneficial in composing features, they lack the fundamental problems of selecting and understanding of the contents. As the feature length increases, it becomes increasingly important to include provisions for improved capturing of the pertinent contents. In this work, we have introduced a new concept of Self-Aware Composition Transformer (SACT) that is capable of generating Multinomial Attention (MultAtt) which is a way of generating distributions of various combinations of frames. Also, multi-head attention transformer works on the principle of combining all possible contents for attention, which is good for natural language classification, but has limitations for video captioning. Video contents have repetitions and require parsing of important contents for better content composition. In this work, we have introduced SACT for more selective attention and combined them for different attention heads for better capturing of the usable contents for any applications. To address the problem of diversification and encourage selective utilization, we propose the Self-Aware Composition Transformer model for dense video captioning and apply the technique on two benchmark datasets like ActivityNet and YouCookII.