 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Smoothen Semantic Features (GSSF) -- Exploring the Linguistic Aspects of Visual Captioning in Indian Languages (Bengali) Using MSCOCO Framework
Paper and Code
Feb 16, 2020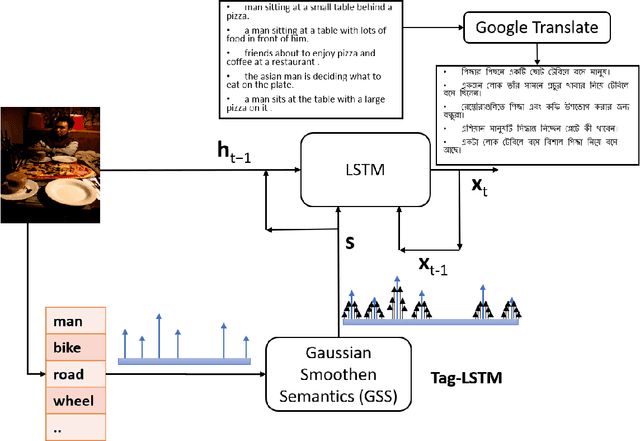


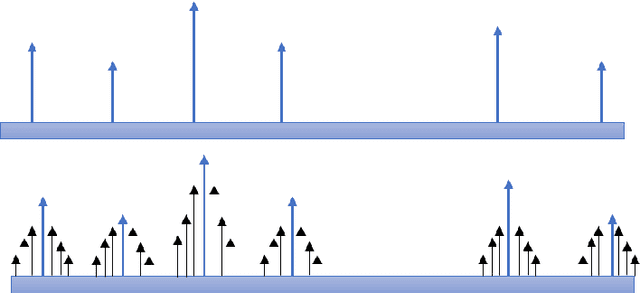
In this work, we have introduced Gaussian Smoothen Semantic Features (GSSF) for Better Semantic Selection for Indian regional language-based image captioning and introduced a procedure where we used the existing translation and English crowd-sourced sentences for training. We have shown that this architecture is a promising alternative source, where there is a crunch in resources. Our main contribution of this work is the development of deep learning architectures for the Bengali language (is the fifth widely spoken language in the world) with a completely different grammar and language attributes. We have shown that these are working well for complex applications like language generation from image contexts and can diversify the representation through introducing constraints, more extensive features, and unique feature spaces. We also established that we could achieve absolute precision and diversity when we use smoothened semantic tensor with the traditional LSTM and feature decomposition networks. With better learning architecture, we succeeded in establishing an automated algorithm and assessment procedure that can help in the evaluation of competent applications without the requirement for expertise and human intervention.