 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Perception based Imitation Learning under Limited Demonstration for Laparoscope Control in Robotic Surgery
Apr 07, 2022

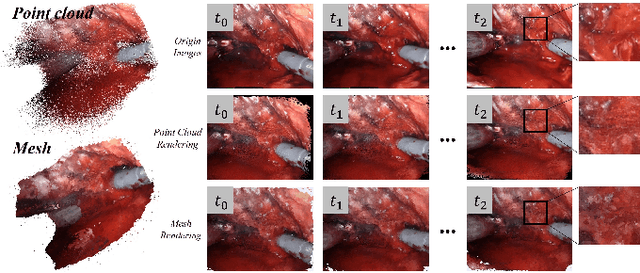
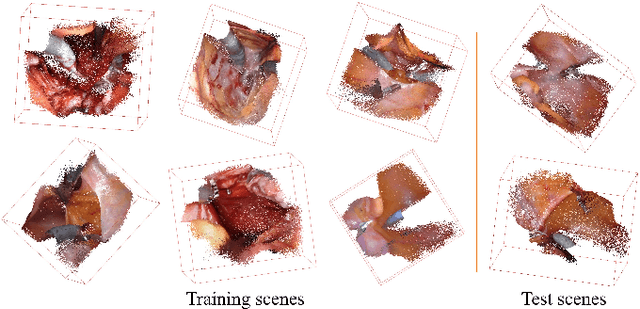
Automatic laparoscope motion control is fundamentally important for surgeons to efficiently perform operations. However, its traditional control methods based on tool tracking without considering information hidden in surgical scenes are not intelligent enough, while the latest supervised imitation learning (IL)-based methods require expensive sensor data and suffer from distribution mismatch issues caused by limited demonstrations. In this paper, we propose a novel Imitation Learning framework for Laparoscope Control (ILLC) with reinforcement learning (RL), which can efficiently learn the control policy from limited surgical video clips. Specially, we first extract surgical laparoscope trajectories from unlabeled videos as the demonstrations and reconstruct the corresponding surgical scenes. To fully learn from limited motion trajectory demonstrations, we propose Shape Preserving Trajectory Augmentation (SPTA) to augment these data, and build a simulation environment that supports parallel RGB-D rendering to reinforce the RL policy for interacting with the environment efficiently. With adversarial training for IL, we obtain the laparoscope control policy based on the generated rollouts and surgical demonstrations. Extensive experiments are conducted in unseen reconstructed surgical scenes, and our method outperforms the previous IL methods, which proves the feasibility of our unified learning-based framework for laparoscope control.
One to Many: Adaptive Instrument Segmentation via Meta Learning and Dynamic Online Adaptation in Robotic Surgical Video
Mar 24, 2021



Surgical instrument segmentation in robot-assisted surgery (RAS) - especially that using learning-based models - relies on the assumption that training and testing videos are sampled from the same domain. However, it is impractical and expensive to collect and annotate sufficient data from every new domain. To greatly increase the label efficiency, we explore a new problem, i.e., adaptive instrument segmentation, which is to effectively adapt one source model to new robotic surgical videos from multiple target domains, only given the annotated instruments in the first frame. We propose MDAL, a meta-learning based dynamic online adaptive learning scheme with a two-stage framework to fast adapt the model parameters on the first frame and partial subsequent frames while predicting the results. MDAL learns the general knowledge of instruments and the fast adaptation ability through the video-specific meta-learning paradigm. The added gradient gate excludes the noisy supervision from pseudo masks for dynamic online adaptation on target videos. We demonstrate empirically that MDAL outperforms other state-of-the-art methods on two datasets (including a real-world RAS dataset). The promising performance on ex-vivo scenes also benefits the downstream tasks such as robot-assisted suturing and camera control.