 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Prior Knowledge for Protein-Protein Interaction Extraction with Memory Network
Jan 07, 2020
Automatically extracting Protein-Protein Interactions (PPI) from biomedical literature provides additional support for precision medicine efforts. This paper proposes a novel memory network-based model (MNM) for PPI extraction, which leverages prior knowledge about protein-protein pairs with memory networks. The proposed MNM captures important context clues related to knowledge representations learned from knowledge bases. Both entity embeddings and relation embeddings of prior knowledge are effective in improving the PPI extraction model, leading to a new state-of-the-art performance on the BioCreative VI PPI dataset. The paper also shows that multiple computational layers over an external memory are superior to long short-term memory networks with the local memories.
* Published on Database-The Journal of Biological Databases and Curation, 11 pages, 5 figures
Knowledge-aware Attention Network for Protein-Protein Interaction Extraction
Jan 07, 2020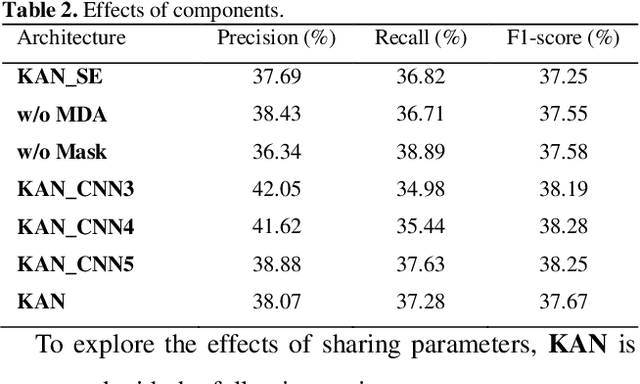
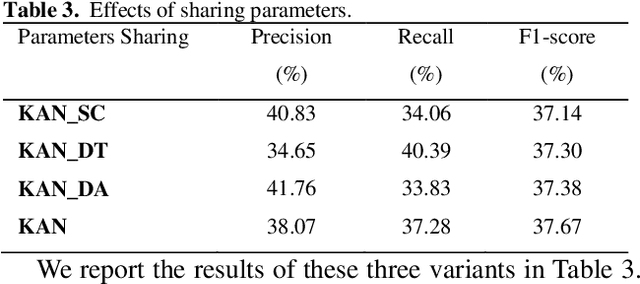
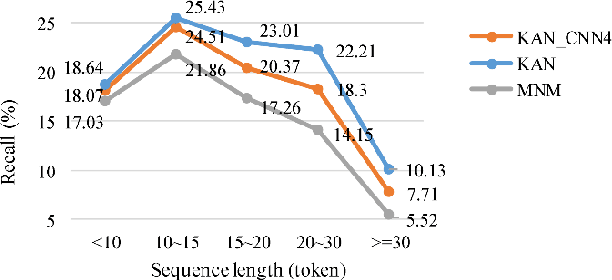
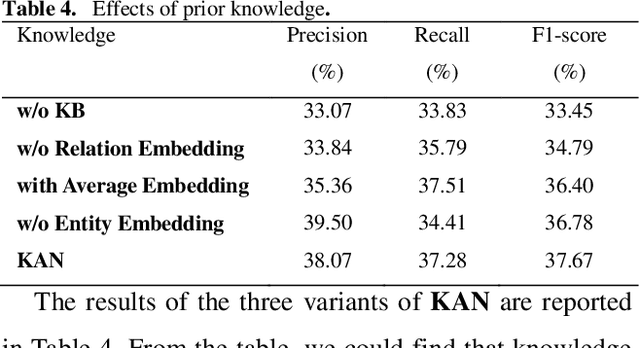
Protein-protein interaction (PPI) extraction from published scientific literature provides additional support for precision medicine efforts. However, many of the current PPI extraction methods need extensive feature engineering and cannot make full use of the prior knowledge in knowledge bases (KB). KBs contain huge amounts of structured information about entities and relationships, therefore plays a pivotal role in PPI extraction. This paper proposes a knowledge-aware attention network (KAN) to fuse prior knowledge about protein-protein pairs and context information for PPI extraction. The proposed model first adopts a diagonal-disabled multi-head attention mechanism to encode context sequence along with knowledge representations learned from KB. Then a novel multi-dimensional attention mechanism is used to select the features that can best describe the encoded context. Experiment results on the BioCreative VI PPI dataset show that the proposed approach could acquire knowledge-aware dependencies between different words in a sequence and lead to a new state-of-the-art performance.
* Published on Journal of Biomedical Informatics, 14 pages, 5 figures
Chemical-induced Disease Relation Extraction with Dependency Information and Prior Knowledge
Jan 02, 2020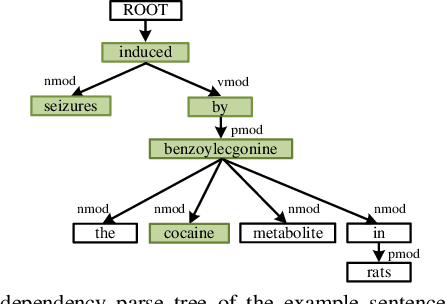
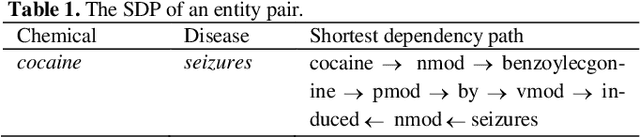
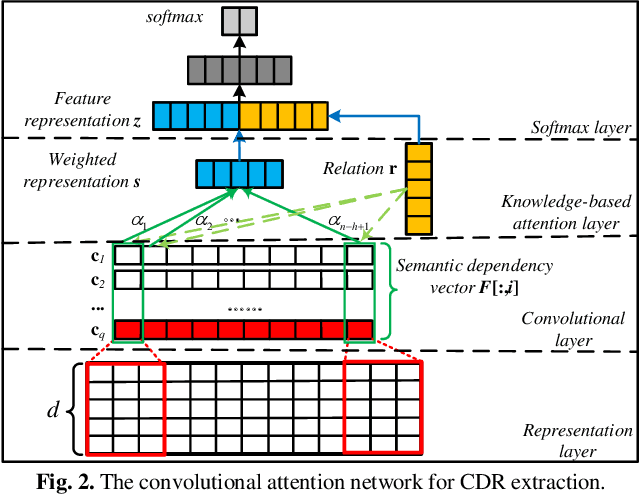
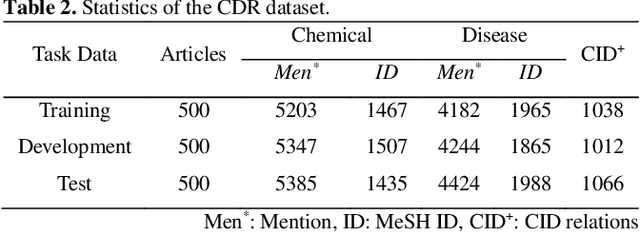
Chemical-disease relation (CDR) extraction is significantly important to various areas of biomedical research and health care. Nowadays, many large-scale biomedical knowledge bases (KBs) containing triples about entity pairs and their relations have been built. KBs are important resources for biomedical relation extraction. However, previous research pays little attention to prior knowledge. In addition, the dependency tree contains important syntactic and semantic information, which helps to improve relation extraction. So how to effectively use it is also worth studying. In this paper, we propose a novel convolutional attention network (CAN) for CDR extraction. Firstly, we extract the shortest dependency path (SDP) between chemical and disease pairs in a sentence, which includes a sequence of words, dependency directions, and dependency relation tags. Then the convolution operations are performed on the SDP to produce deep semantic dependency features. After that, an attention mechanism is employed to learn the importance/weight of each semantic dependency vector related to knowledge representations learned from KBs. Finally, in order to combine dependency information and prior knowledge, the concatenation of weighted semantic dependency representations and knowledge representations is fed to the softmax layer for classification. Experiments on the BioCreative V CDR dataset show that our method achieves comparable performance with the state-of-the-art systems, and both dependency information and prior knowledge play important roles in CDR extraction task.
* Published on Journal of Biomedical Informatics, 13 pages
Combining Context and Knowledge Representations for Chemical-Disease Relation Extraction
Dec 23, 2019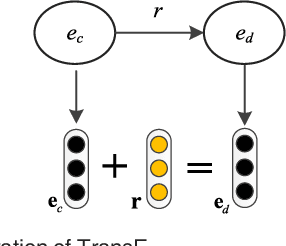

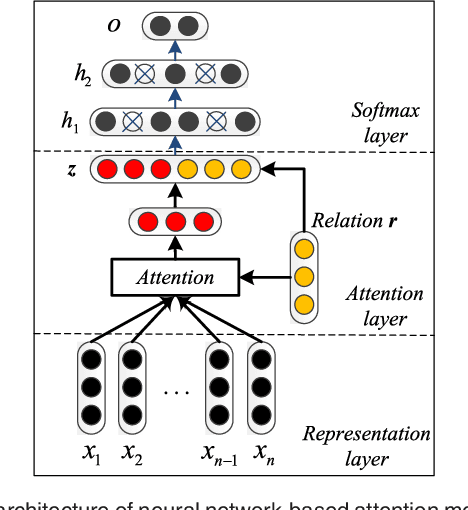
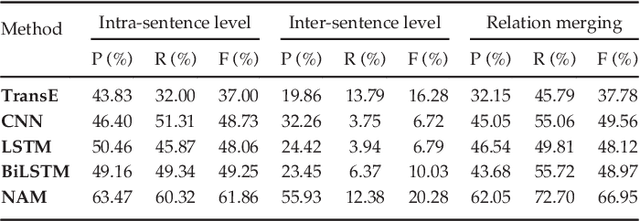
Automatically extracting the relationships between chemicals and diseases is significantly important to various areas of biomedical research and health care. Biomedical experts have built many large-scale knowledge bases (KBs) to advance the development of biomedical research. KBs contain huge amounts of structured information about entities and relationships, therefore plays a pivotal role in chemical-disease relation (CDR) extraction. However, previous researches pay less attention to the prior knowledge existing in KBs. This paper proposes a neural network-based attention model (NAM) for CDR extraction, which makes full use of context information in documents and prior knowledge in KBs. For a pair of entities in a document, an attention mechanism is employed to select important context words with respect to the relation representations learned from KBs. Experiments on the BioCreative V CDR dataset show that combining context and knowledge representations through the attention mechanism, could significantly improve the CDR extraction performance while achieve comparable results with state-of-the-art systems.
* Published on IEEE/ACM Transactions on Computational Biology and Bioinformatics, 11 pages, 5 figures
Knowledge-guided Convolutional Networks for Chemical-Disease Relation Extraction
Dec 23, 2019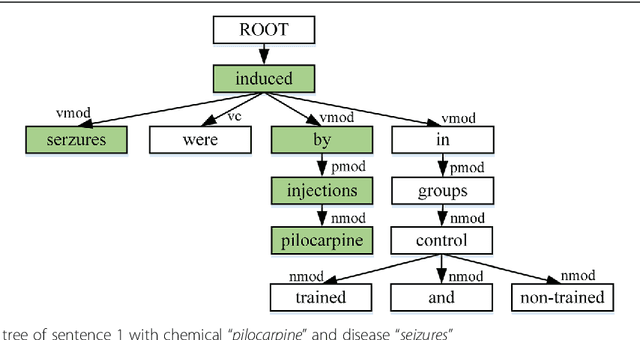
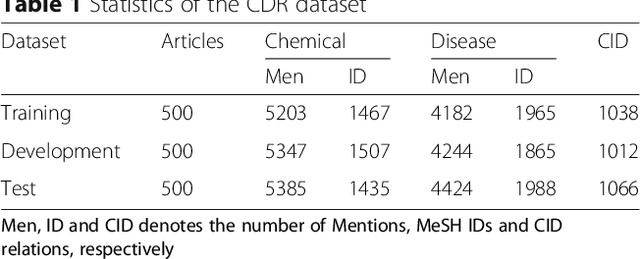
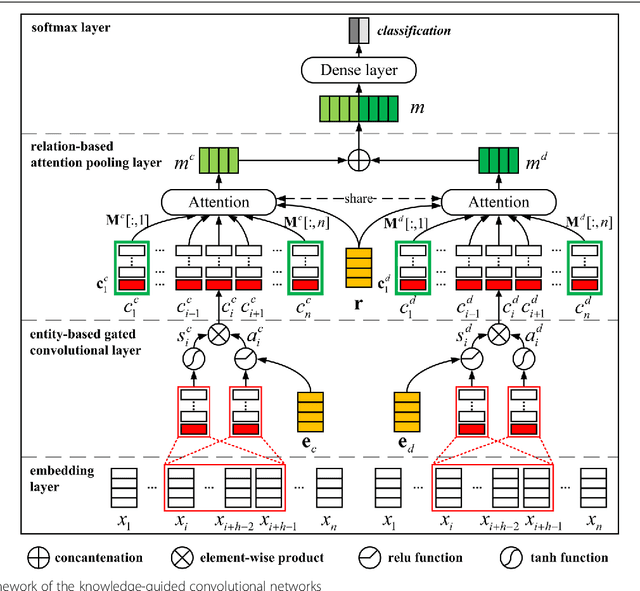
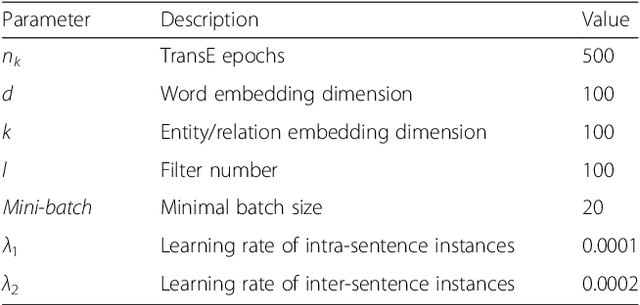
Background: Automatic extraction of chemical-disease relations (CDR) from unstructured text is of essential importance for disease treatment and drug development. Meanwhile, biomedical experts have built many highly-structured knowledge bases (KBs), which contain prior knowledge about chemicals and diseases. Prior knowledge provides strong support for CDR extraction. How to make full use of it is worth studying. Results: This paper proposes a novel model called "Knowledge-guided Convolutional Networks (KCN)" to leverage prior knowledge for CDR extraction. The proposed model first learns knowledge representations including entity embeddings and relation embeddings from KBs. Then, entity embeddings are used to control the propagation of context features towards a chemical-disease pair with gated convolutions. After that, relation embeddings are employed to further capture the weighted context features by a shared attention pooling. Finally, the weighted context features containing additional knowledge information are used for CDR extraction. Experiments on the BioCreative V CDR dataset show that the proposed KCN achieves 71.28% F1-score, which outperforms most of the state-of-the-art systems. Conclusions: This paper proposes a novel CDR extraction model KCN to make full use of prior knowledge. Experimental results demonstrate that KCN could effectively integrate prior knowledge and contexts for the performance improvement.
* Published on BMC Bioinformatics, 16 pages, 5 figures
Improving Neural Protein-Protein Interaction Extraction with Knowledge Selection
Dec 11, 2019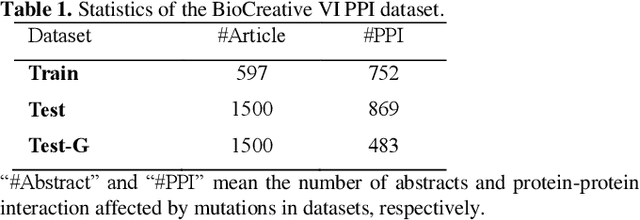
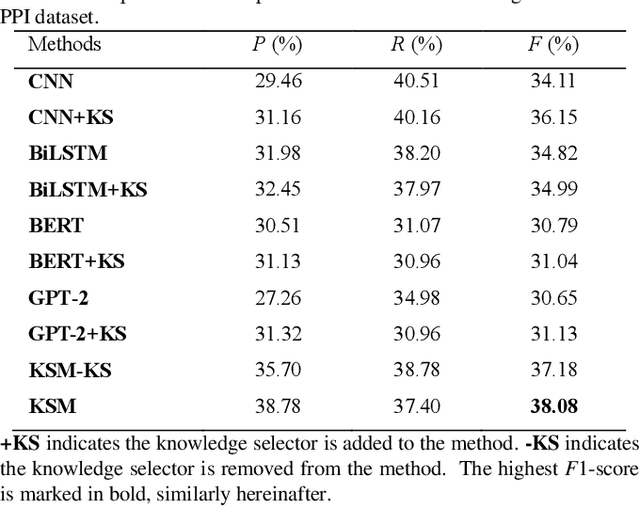
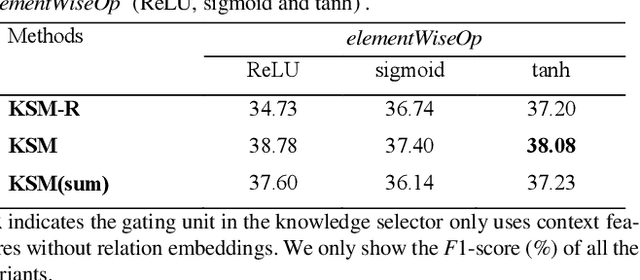
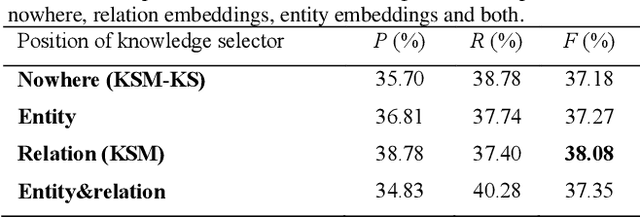
Protein-protein interaction (PPI) extraction from published scientific literature provides additional support for precision medicine efforts. Meanwhile, knowledge bases (KBs) contain huge amounts of structured information of protein entities and their relations, which can be encoded in entity and relation embeddings to help PPI extraction. However, the prior knowledge of protein-protein pairs must be selectively used so that it is suitable for different contexts. This paper proposes a Knowledge Selection Model (KSM) to fuse the selected prior knowledge and context information for PPI extraction. Firstly, two Transformers encode the context sequence of a protein pair according to each protein embedding, respectively. Then, the two outputs are fed to a mutual attention to capture the important context features towards the protein pair. Next, the context features are used to distill the relation embedding by a knowledge selector. Finally, the selected relation embedding and the context features are concatenated for PPI extraction. Experiments on the BioCreative VI PPI dataset show that KSM achieves a new state-of-the-art performance (38.08% F1-score) by adding knowledge selection.
* Published in Computational Biology and Chemistry; 14 pages, 2 figures