 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-aware Attention Network for Protein-Protein Interaction Extraction
Paper and Code
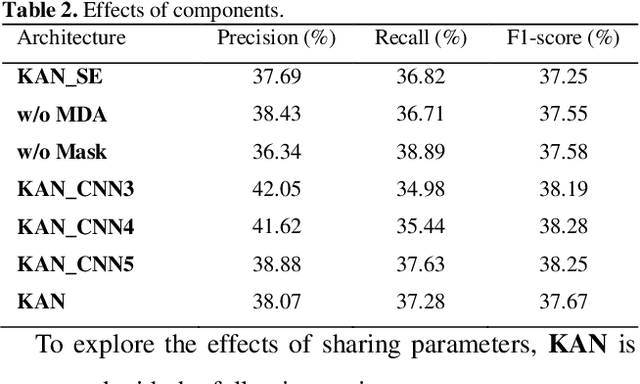
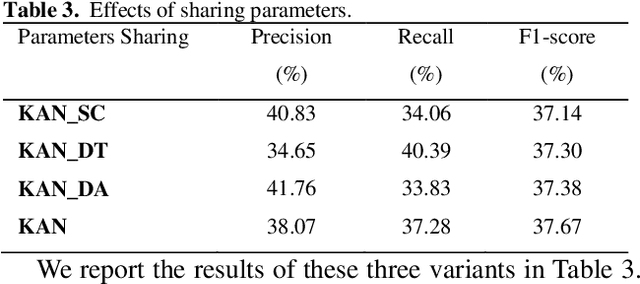
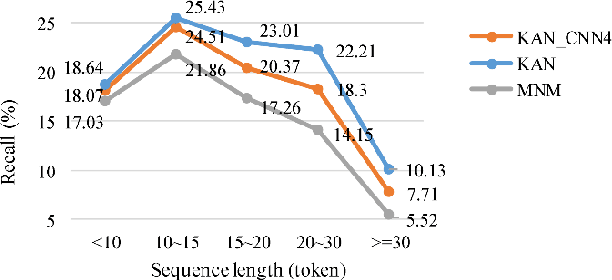
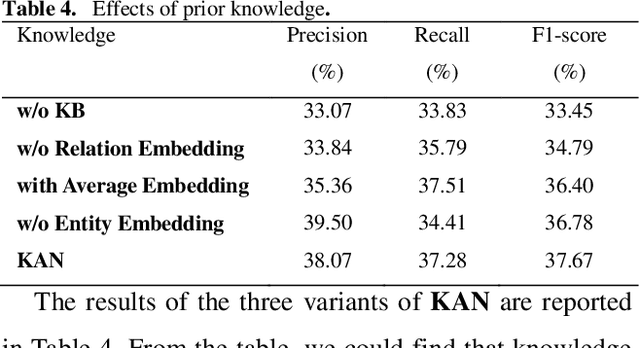
Protein-protein interaction (PPI) extraction from published scientific literature provides additional support for precision medicine efforts. However, many of the current PPI extraction methods need extensive feature engineering and cannot make full use of the prior knowledge in knowledge bases (KB). KBs contain huge amounts of structured information about entities and relationships, therefore plays a pivotal role in PPI extraction. This paper proposes a knowledge-aware attention network (KAN) to fuse prior knowledge about protein-protein pairs and context information for PPI extraction. The proposed model first adopts a diagonal-disabled multi-head attention mechanism to encode context sequence along with knowledge representations learned from KB. Then a novel multi-dimensional attention mechanism is used to select the features that can best describe the encoded context. Experiment results on the BioCreative VI PPI dataset show that the proposed approach could acquire knowledge-aware dependencies between different words in a sequence and lead to a new state-of-the-art performance.