 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTA-GGAD: Testing-time Adaptive Graph Model for Generalist Graph Anomaly Detection
Mar 10, 2026A significant number of anomalous nodes in the real world, such as fake news, noncompliant users, malicious transactions, and malicious posts, severely compromises the health of the graph data ecosystem and urgently requires effective identification and processing. With anomalies that span multiple data domains yet exhibit vast differences in features, cross-domain detection models face severe domain shift issues, which limit their generalizability across all domains. This study identifies and quantitatively analyzes a specific feature mismatch pattern exhibited by domain shift in graph anomaly detection, which we define as the \emph{Anomaly Disassortativity} issue ($\mathcal{AD}$). Based on the modeling of the issue $\mathcal{AD}$, we introduce a novel graph foundation model for anomaly detection. It achieves cross-domain generalization in different graphs, requiring only a single training phase to perform effectively across diverse domains. The experimental findings, based on fourteen diverse real-world graphs, confirm a breakthrough in the model's cross-domain adaptation, achieving a pioneering state-of-the-art (SOTA) level in terms of detection accuracy. In summary, the proposed theory of $\mathcal{AD}$ provides a novel theoretical perspective and a practical route for future research in generalist graph anomaly detection (GGAD). The code is available at https://anonymous.4open.science/r/Anonymization-TA-GGAD/.
GCTAM: Global and Contextual Truncated Affinity Combined Maximization Model For Unsupervised Graph Anomaly Detection
Mar 02, 2026Anomalies often occur in real-world information networks/graphs, such as malevolent users, malicious comments, banned users, and fake news in social graphs. The latest graph anomaly detection methods use a novel mechanism called truncated affinity maximization (TAM) to detect anomaly nodes without using any label information and achieve impressive results. TAM maximizes the affinities among the normal nodes while truncating the affinities of the anomalous nodes to identify the anomalies. However, existing TAM-based methods truncate suspicious nodes according to a rigid threshold that ignores the specificity and high-order affinities of different nodes. This inevitably causes inefficient truncations from both normal and anomalous nodes, limiting the effectiveness of anomaly detection. To this end, this paper proposes a novel truncation model combining contextual and global affinity to truncate the anomalous nodes. The core idea of the work is to use contextual truncation to decrease the affinity of anomalous nodes, while global truncation increases the affinity of normal nodes. Extensive experiments on massive real-world datasets show that our method surpasses peer methods in most graph anomaly detection tasks. In highlights, compared with previous state-of-the-art methods, the proposed method has +15\% $\sim$ +20\% improvements in two famous real-world datasets, Amazon and YelpChi. Notably, our method works well in large datasets, Amazin-all and YelpChi-all, and achieves the best results, while most previous models cannot complete the tasks.
Bridging Granularity Gaps: Hierarchical Semantic Learning for Cross-domain Few-shot Segmentation
Nov 15, 2025Cross-domain Few-shot Segmentation (CD-FSS) aims to segment novel classes from target domains that are not involved in training and have significantly different data distributions from the source domain, using only a few annotated samples, and recent years have witnessed significant progress on this task. However, existing CD-FSS methods primarily focus on style gaps between source and target domains while ignoring segmentation granularity gaps, resulting in insufficient semantic discriminability for novel classes in target domains. Therefore, we propose a Hierarchical Semantic Learning (HSL) framework to tackle this problem. Specifically, we introduce a Dual Style Randomization (DSR) module and a Hierarchical Semantic Mining (HSM) module to learn hierarchical semantic features, thereby enhancing the model's ability to recognize semantics at varying granularities. DSR simulates target domain data with diverse foreground-background style differences and overall style variations through foreground and global style randomization respectively, while HSM leverages multi-scale superpixels to guide the model to mine intra-class consistency and inter-class distinction at different granularities. Additionally, we also propose a Prototype Confidence-modulated Thresholding (PCMT) module to mitigate segmentation ambiguity when foreground and background are excessively similar. Extensive experiments are conducted on four popular target domain datasets, and the results demonstrate that our method achieves state-of-the-art performance.
NoiseHGNN: Synthesized Similarity Graph-Based Neural Network For Noised Heterogeneous Graph Representation Learning
Dec 24, 2024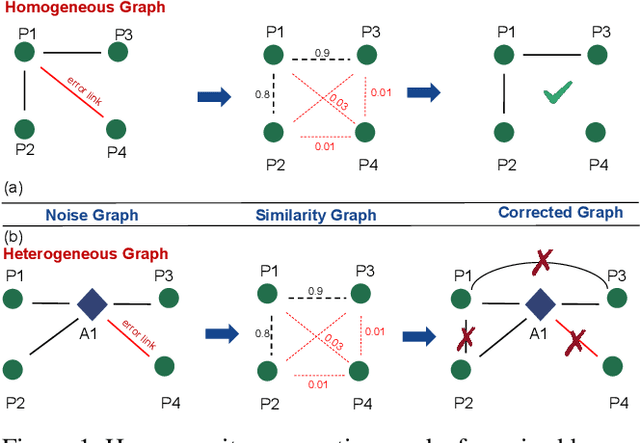

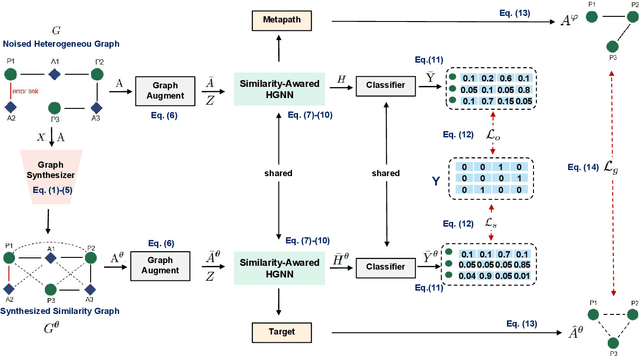

Real-world graph data environments intrinsically exist noise (e.g., link and structure errors) that inevitably disturb the effectiveness of graph representation and downstream learning tasks. For homogeneous graphs, the latest works use original node features to synthesize a similarity graph that can correct the structure of the noised graph. This idea is based on the homogeneity assumption, which states that similar nodes in the homogeneous graph tend to have direct links in the original graph. However, similar nodes in heterogeneous graphs usually do not have direct links, which can not be used to correct the original noise graph. This causes a significant challenge in noised heterogeneous graph learning. To this end, this paper proposes a novel synthesized similarity-based graph neural network compatible with noised heterogeneous graph learning. First, we calculate the original feature similarities of all nodes to synthesize a similarity-based high-order graph. Second, we propose a similarity-aware encoder to embed original and synthesized graphs with shared parameters. Then, instead of graph-to-graph supervising, we synchronously supervise the original and synthesized graph embeddings to predict the same labels. Meanwhile, a target-based graph extracted from the synthesized graph contrasts the structure of the metapath-based graph extracted from the original graph to learn the mutual information. Extensive experiments in numerous real-world datasets show the proposed method achieves state-of-the-art records in the noised heterogeneous graph learning tasks. In highlights, +5$\sim$6\% improvements are observed in several noised datasets compared with previous SOTA methods. The code and datasets are available at https://github.com/kg-cc/NoiseHGNN.
LegoNet: Alternating Model Blocks for Medical Image Segmentation
Jun 06, 2023Since the emergence of convolutional neural networks (CNNs), and later vision transformers (ViTs), the common paradigm for model development has always been using a set of identical block types with varying parameters/hyper-parameters. To leverage the benefits of different architectural designs (e.g. CNNs and ViTs), we propose to alternate structurally different types of blocks to generate a new architecture, mimicking how Lego blocks can be assembled together. Using two CNN-based and one SwinViT-based blocks, we investigate three variations to the so-called LegoNet that applies the new concept of block alternation for the segmentation task in medical imaging. We also study a new clinical problem which has not been investigated before, namely the right internal mammary artery (RIMA) and perivascular space segmentation from computed tomography angiography (CTA) which has demonstrated a prognostic value to major cardiovascular outcomes. We compare the model performance against popular CNN and ViT architectures using two large datasets (e.g. achieving 0.749 dice similarity coefficient (DSC) on the larger dataset). We evaluate the performance of the model on three external testing cohorts as well, where an expert clinician made corrections to the model segmented results (DSC>0.90 for the three cohorts). To assess our proposed model for suitability in clinical use, we perform intra- and inter-observer variability analysis. Finally, we investigate a joint self-supervised learning approach to assess its impact on model performance. The code and the pretrained model weights will be available upon acceptance.
EBSD Grain Knowledge Graph Representation Learning for Material Structure-Property Prediction
Sep 29, 2021



The microstructure is an essential part of materials, storing the genes of materials and having a decisive influence on materials' physical and chemical properties. The material genetic engineering program aims to establish the relationship between material composition/process, organization, and performance to realize the reverse design of materials, thereby accelerating the research and development of new materials. However, tissue analysis methods of materials science, such as metallographic analysis, XRD analysis, and EBSD analysis, cannot directly establish a complete quantitative relationship between tissue structure and performance. Therefore, this paper proposes a novel data-knowledge-driven organization representation and performance prediction method to obtain a quantitative structure-performance relationship. First, a knowledge graph based on EBSD is constructed to describe the material's mesoscopic microstructure. Then a graph representation learning network based on graph attention is constructed, and the EBSD organizational knowledge graph is input into the network to obtain graph-level feature embedding. Finally, the graph-level feature embedding is input to a graph feature mapping network to obtain the material's mechanical properties. The experimental results show that our method is superior to traditional machine learning and machine vision methods.
Class Knowledge Overlay to Visual Feature Learning for Zero-Shot Image Classification
Feb 26, 2021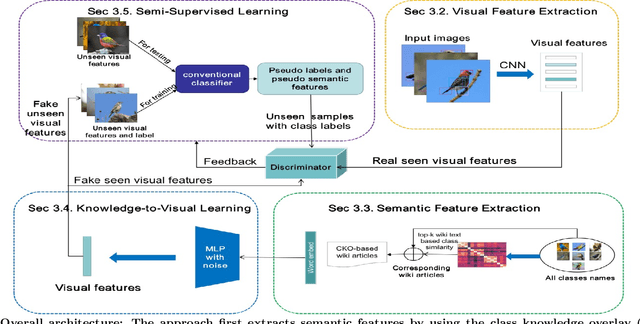
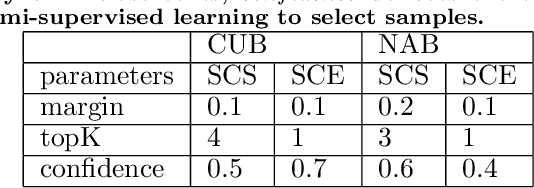
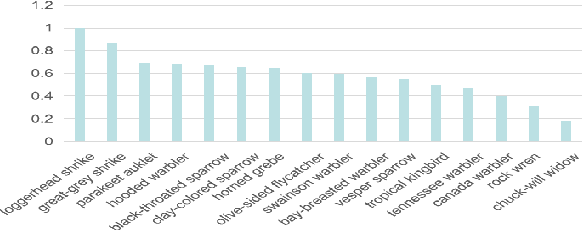

New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
Multi-Knowledge Fusion for New Feature Generation in Generalized Zero-Shot Learning
Feb 23, 2021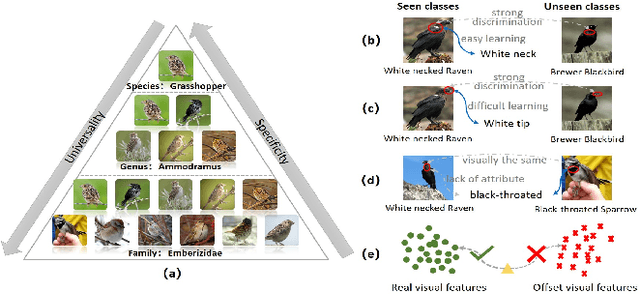
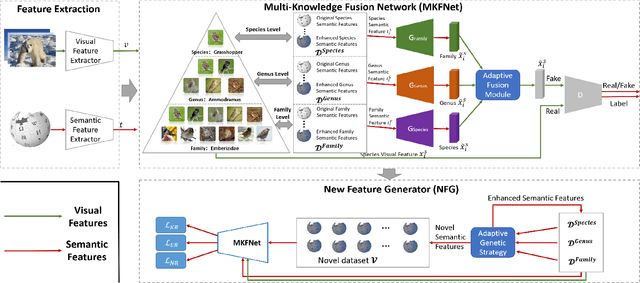

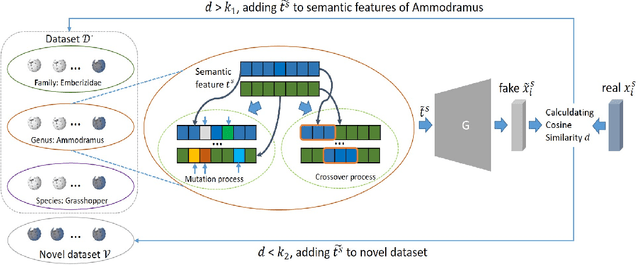
Suffering from the semantic insufficiency and domain-shift problems, most of existing state-of-the-art methods fail to achieve satisfactory results for Zero-Shot Learning (ZSL). In order to alleviate these problems, we propose a novel generative ZSL method to learn more generalized features from multi-knowledge with continuously generated new semantics in semantic-to-visual embedding. In our approach, the proposed Multi-Knowledge Fusion Network (MKFNet) takes different semantic features from multi-knowledge as input, which enables more relevant semantic features to be trained for semantic-to-visual embedding, and finally generates more generalized visual features by adaptively fusing visual features from different knowledge domain. The proposed New Feature Generator (NFG) with adaptive genetic strategy is used to enrich semantic information on the one hand, and on the other hand it greatly improves the intersection of visual feature generated by MKFNet and unseen visual faetures. Empirically, we show that our approach can achieve significantly better performance compared to existing state-of-the-art methods on a large number of benchmarks for several ZSL tasks, including traditional ZSL, generalized ZSL and zero-shot retrieval.
Cross Knowledge-based Generative Zero-Shot Learning Approach with Taxonomy Regularization
Jan 25, 2021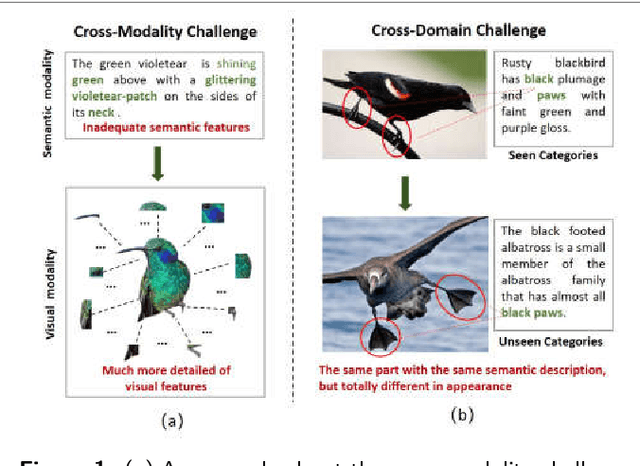
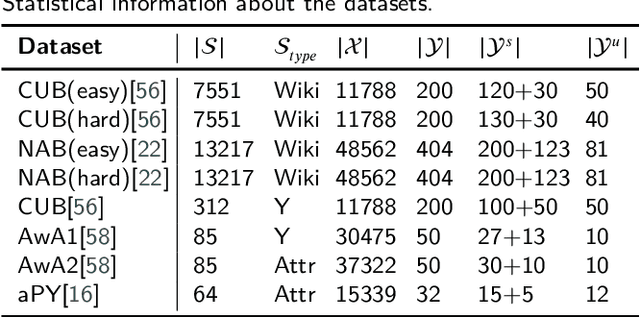
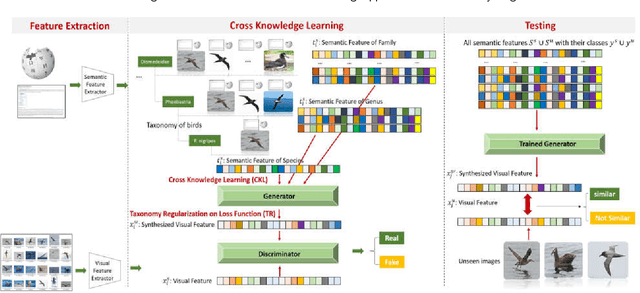
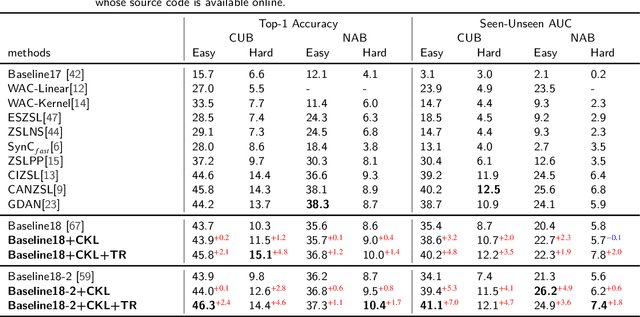
Although zero-shot learning (ZSL) has an inferential capability of recognizing new classes that have never been seen before, it always faces two fundamental challenges of the cross modality and crossdomain challenges. In order to alleviate these problems, we develop a generative network-based ZSL approach equipped with the proposed Cross Knowledge Learning (CKL) scheme and Taxonomy Regularization (TR). In our approach, the semantic features are taken as inputs, and the output is the synthesized visual features generated from the corresponding semantic features. CKL enables more relevant semantic features to be trained for semantic-to-visual feature embedding in ZSL, while Taxonomy Regularization (TR) significantly improves the intersections with unseen images with more generalized visual features generated from generative network. Extensive experiments on several benchmark datasets (i.e., AwA1, AwA2, CUB, NAB and aPY) show that our approach is superior to these state-of-the-art methods in terms of ZSL image classification and retrieval.
Progressive Reinforcement Learning with Distillation for Multi-Skilled Motion Control
Feb 13, 2018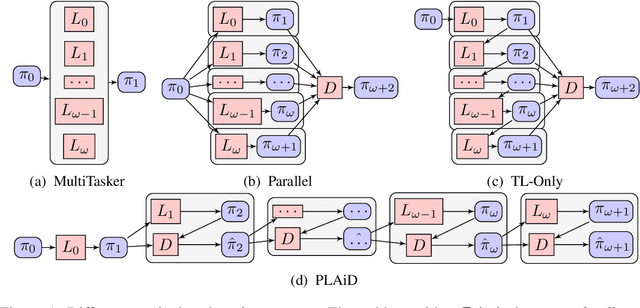

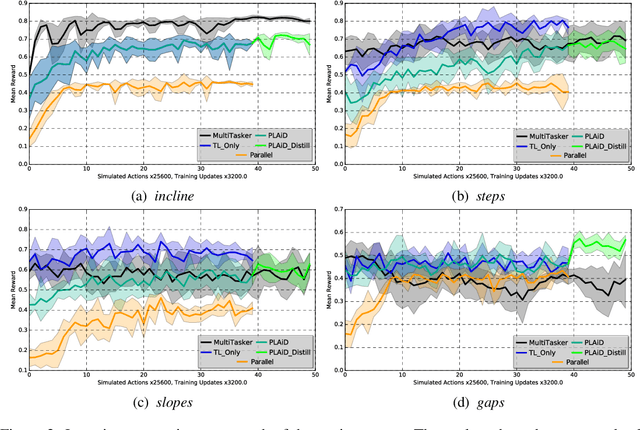

Deep reinforcement learning has demonstrated increasing capabilities for continuous control problems, including agents that can move with skill and agility through their environment. An open problem in this setting is that of developing good strategies for integrating or merging policies for multiple skills, where each individual skill is a specialist in a specific skill and its associated state distribution. We extend policy distillation methods to the continuous action setting and leverage this technique to combine expert policies, as evaluated in the domain of simulated bipedal locomotion across different classes of terrain. We also introduce an input injection method for augmenting an existing policy network to exploit new input features. Lastly, our method uses transfer learning to assist in the efficient acquisition of new skills. The combination of these methods allows a policy to be incrementally augmented with new skills. We compare our progressive learning and integration via distillation (PLAID) method against three alternative baselines.