 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Knowledge Fusion for New Feature Generation in Generalized Zero-Shot Learning
Paper and Code
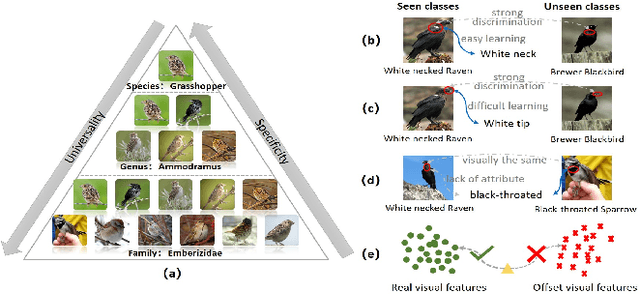
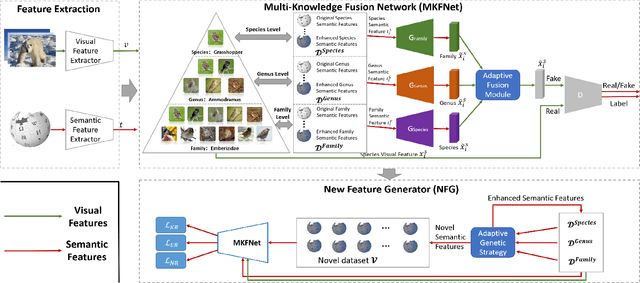

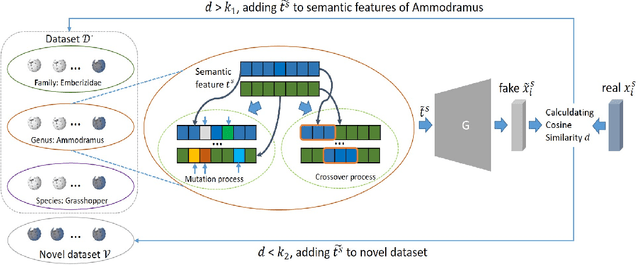
Suffering from the semantic insufficiency and domain-shift problems, most of existing state-of-the-art methods fail to achieve satisfactory results for Zero-Shot Learning (ZSL). In order to alleviate these problems, we propose a novel generative ZSL method to learn more generalized features from multi-knowledge with continuously generated new semantics in semantic-to-visual embedding. In our approach, the proposed Multi-Knowledge Fusion Network (MKFNet) takes different semantic features from multi-knowledge as input, which enables more relevant semantic features to be trained for semantic-to-visual embedding, and finally generates more generalized visual features by adaptively fusing visual features from different knowledge domain. The proposed New Feature Generator (NFG) with adaptive genetic strategy is used to enrich semantic information on the one hand, and on the other hand it greatly improves the intersection of visual feature generated by MKFNet and unseen visual faetures. Empirically, we show that our approach can achieve significantly better performance compared to existing state-of-the-art methods on a large number of benchmarks for several ZSL tasks, including traditional ZSL, generalized ZSL and zero-shot retrieval.