 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysSFI-Net: Physics-informed Geometric Learning of Skeletal and Facial Interactions for Orthognathic Surgical Outcome Prediction
Jan 06, 2026Orthognathic surgery repositions jaw bones to restore occlusion and enhance facial aesthetics. Accurate simulation of postoperative facial morphology is essential for preoperative planning. However, traditional biomechanical models are computationally expensive, while geometric deep learning approaches often lack interpretability. In this study, we develop and validate a physics-informed geometric deep learning framework named PhysSFI-Net for precise prediction of soft tissue deformation following orthognathic surgery. PhysSFI-Net consists of three components: a hierarchical graph module with craniofacial and surgical plan encoders combined with attention mechanisms to extract skeletal-facial interaction features; a Long Short-Term Memory (LSTM)-based sequential predictor for incremental soft tissue deformation; and a biomechanics-inspired module for high-resolution facial surface reconstruction. Model performance was assessed using point cloud shape error (Hausdorff distance), surface deviation error, and landmark localization error (Euclidean distances of craniomaxillofacial landmarks) between predicted facial shapes and corresponding ground truths. A total of 135 patients who underwent combined orthodontic and orthognathic treatment were included for model training and validation. Quantitative analysis demonstrated that PhysSFI-Net achieved a point cloud shape error of 1.070 +/- 0.088 mm, a surface deviation error of 1.296 +/- 0.349 mm, and a landmark localization error of 2.445 +/- 1.326 mm. Comparative experiments indicated that PhysSFI-Net outperformed the state-of-the-art method ACMT-Net in prediction accuracy. In conclusion, PhysSFI-Net enables interpretable, high-resolution prediction of postoperative facial morphology with superior accuracy, showing strong potential for clinical application in orthognathic surgical planning and simulation.
A new solution and concrete implementation steps for Artificial General Intelligence
Aug 12, 2023



At present, the mainstream artificial intelligence generally adopts the technical path of "attention mechanism + deep learning" + "reinforcement learning". It has made great progress in the field of AIGC (Artificial Intelligence Generated Content), setting off the technical wave of big models[ 2][13 ]. But in areas that need to interact with the actual environment, such as elderly care, home nanny, agricultural production, and vehicle driving, trial and error are expensive and a reinforcement learning process that requires much trial and error is difficult to achieve. Therefore, in order to achieve Artificial General Intelligence(AGI) that can be applied to any field, we need to use both existing technologies and solve the defects of existing technologies, so as to further develop the technological wave of artificial intelligence. In this paper, we analyze the limitations of the technical route of large models, and by addressing these limitations, we propose solutions, thus solving the inherent defects of large models. In this paper, we will reveal how to achieve true AGI step by step.
Class Knowledge Overlay to Visual Feature Learning for Zero-Shot Image Classification
Feb 26, 2021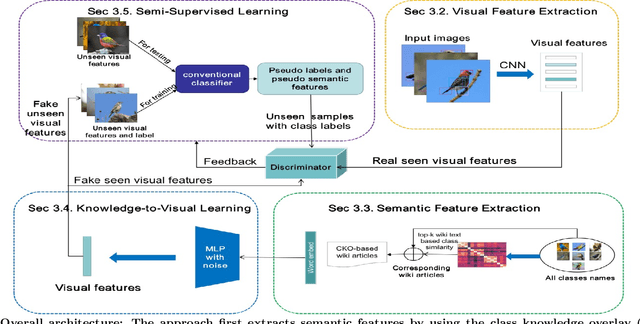
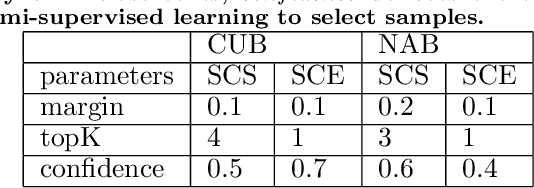
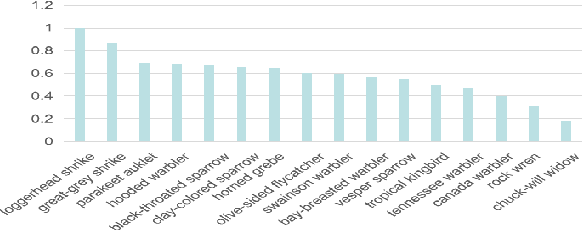

New categories can be discovered by transforming semantic features into synthesized visual features without corresponding training samples in zero-shot image classification. Although significant progress has been made in generating high-quality synthesized visual features using generative adversarial networks, guaranteeing semantic consistency between the semantic features and visual features remains very challenging. In this paper, we propose a novel zero-shot learning approach, GAN-CST, based on class knowledge to visual feature learning to tackle the problem. The approach consists of three parts, class knowledge overlay, semi-supervised learning and triplet loss. It applies class knowledge overlay (CKO) to obtain knowledge not only from the corresponding class but also from other classes that have the knowledge overlay. It ensures that the knowledge-to-visual learning process has adequate information to generate synthesized visual features. The approach also applies a semi-supervised learning process to re-train knowledge-to-visual model. It contributes to reinforcing synthesized visual features generation as well as new category prediction. We tabulate results on a number of benchmark datasets demonstrating that the proposed model delivers superior performance over state-of-the-art approaches.
Multi-Knowledge Fusion for New Feature Generation in Generalized Zero-Shot Learning
Feb 23, 2021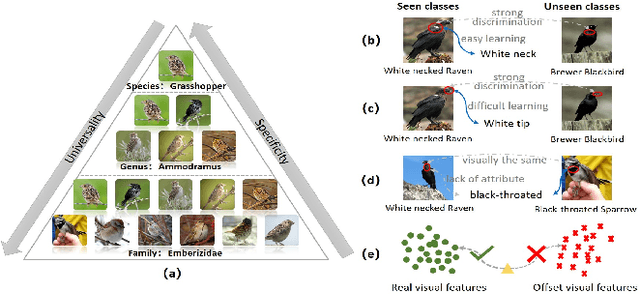
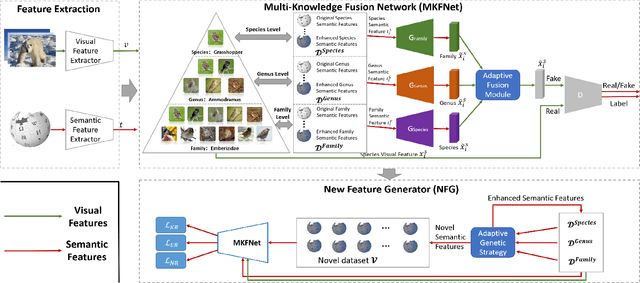

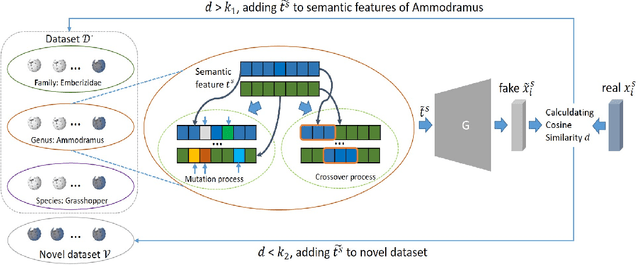
Suffering from the semantic insufficiency and domain-shift problems, most of existing state-of-the-art methods fail to achieve satisfactory results for Zero-Shot Learning (ZSL). In order to alleviate these problems, we propose a novel generative ZSL method to learn more generalized features from multi-knowledge with continuously generated new semantics in semantic-to-visual embedding. In our approach, the proposed Multi-Knowledge Fusion Network (MKFNet) takes different semantic features from multi-knowledge as input, which enables more relevant semantic features to be trained for semantic-to-visual embedding, and finally generates more generalized visual features by adaptively fusing visual features from different knowledge domain. The proposed New Feature Generator (NFG) with adaptive genetic strategy is used to enrich semantic information on the one hand, and on the other hand it greatly improves the intersection of visual feature generated by MKFNet and unseen visual faetures. Empirically, we show that our approach can achieve significantly better performance compared to existing state-of-the-art methods on a large number of benchmarks for several ZSL tasks, including traditional ZSL, generalized ZSL and zero-shot retrieval.
Cross Knowledge-based Generative Zero-Shot Learning Approach with Taxonomy Regularization
Jan 25, 2021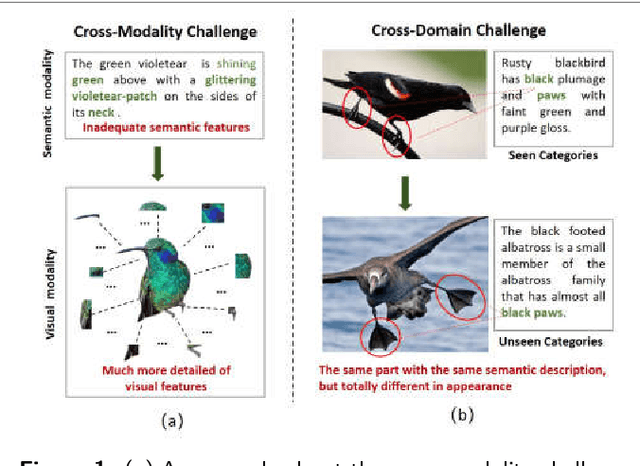
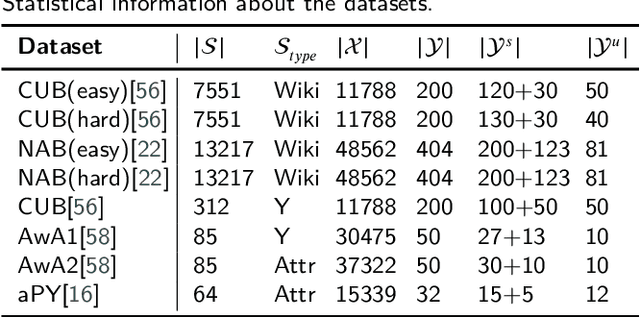
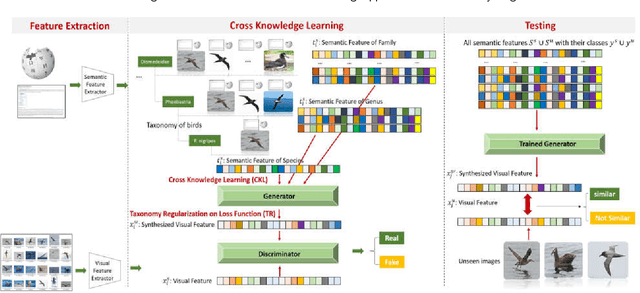
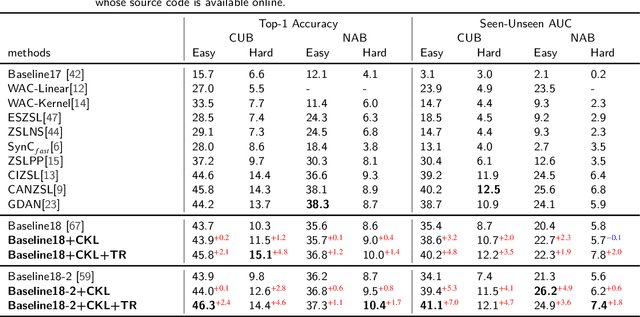
Although zero-shot learning (ZSL) has an inferential capability of recognizing new classes that have never been seen before, it always faces two fundamental challenges of the cross modality and crossdomain challenges. In order to alleviate these problems, we develop a generative network-based ZSL approach equipped with the proposed Cross Knowledge Learning (CKL) scheme and Taxonomy Regularization (TR). In our approach, the semantic features are taken as inputs, and the output is the synthesized visual features generated from the corresponding semantic features. CKL enables more relevant semantic features to be trained for semantic-to-visual feature embedding in ZSL, while Taxonomy Regularization (TR) significantly improves the intersections with unseen images with more generalized visual features generated from generative network. Extensive experiments on several benchmark datasets (i.e., AwA1, AwA2, CUB, NAB and aPY) show that our approach is superior to these state-of-the-art methods in terms of ZSL image classification and retrieval.