 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Knowledge-based Generative Zero-Shot Learning Approach with Taxonomy Regularization
Paper and Code
Jan 25, 2021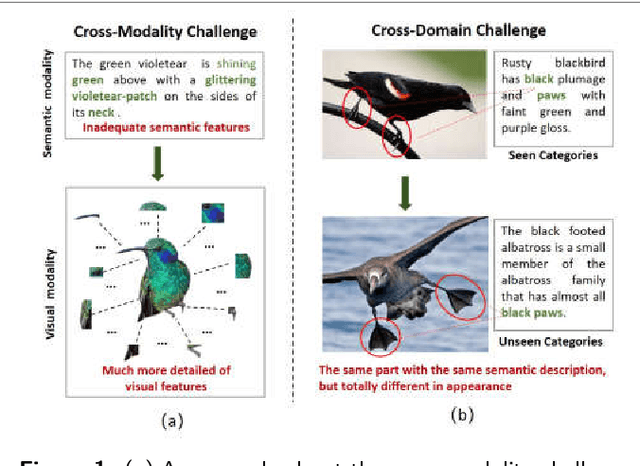
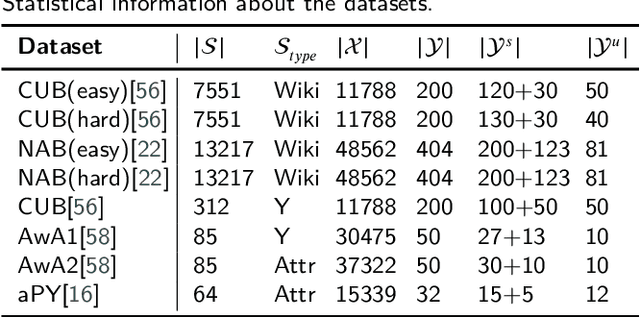
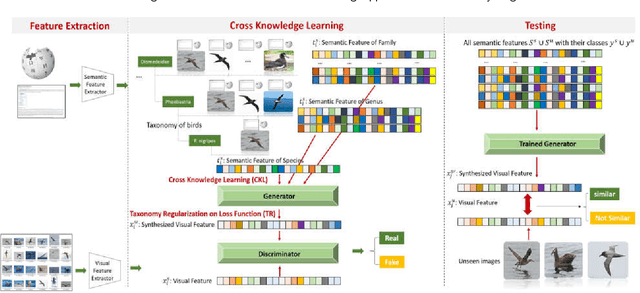
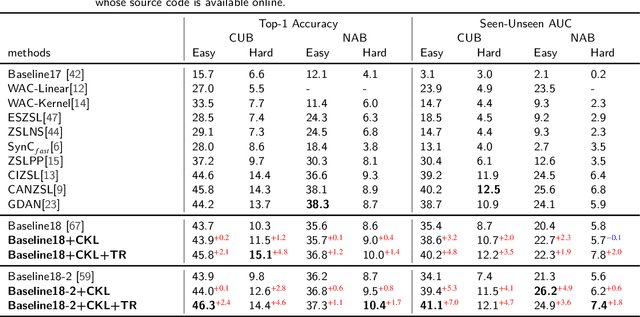
Although zero-shot learning (ZSL) has an inferential capability of recognizing new classes that have never been seen before, it always faces two fundamental challenges of the cross modality and crossdomain challenges. In order to alleviate these problems, we develop a generative network-based ZSL approach equipped with the proposed Cross Knowledge Learning (CKL) scheme and Taxonomy Regularization (TR). In our approach, the semantic features are taken as inputs, and the output is the synthesized visual features generated from the corresponding semantic features. CKL enables more relevant semantic features to be trained for semantic-to-visual feature embedding in ZSL, while Taxonomy Regularization (TR) significantly improves the intersections with unseen images with more generalized visual features generated from generative network. Extensive experiments on several benchmark datasets (i.e., AwA1, AwA2, CUB, NAB and aPY) show that our approach is superior to these state-of-the-art methods in terms of ZSL image classification and retrieval.