 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Is Not Static: Order-Aware Hypergraph RAG for Language Models
Apr 14, 2026Retrieval-augmented generation (RAG) enhances large language models by grounding outputs in retrieved knowledge. However, existing RAG methods including graph- and hypergraph-based approaches treat retrieved evidence as an unordered set, implicitly assuming permutation invariance. This assumption is misaligned with many real-world reasoning tasks, where outcomes depend not only on which interactions occur, but also on the order in which they unfold. We propose Order-Aware Knowledge Hypergraph RAG (OKH-RAG), which treats order as a first-class structural property. OKH-RAG represents knowledge as higher-order interactions within a hypergraph augmented with precedence structure, and reformulates retrieval as sequence inference over hyperedges. Instead of selecting independent facts, it recovers coherent interaction trajectories that reflect underlying reasoning processes. A learned transition model infers precedence directly from data without requiring explicit temporal supervision. We evaluate OKH-RAG on order-sensitive question answering and explanation tasks, including tropical cyclone and port operation scenarios. OKH-RAG consistently outperforms permutation-invariant baselines, and ablations show that these gains arise specifically from modeling interaction order. These results highlight a key limitation of set-based retrieval: effective reasoning requires not only retrieving relevant evidence, but organizing it into structured sequences.
How Independent are Large Language Models? A Statistical Framework for Auditing Behavioral Entanglement and Reweighting Verifier Ensembles
Apr 08, 2026The rapid growth of the large language model (LLM) ecosystem raises a critical question: are seemingly diverse models truly independent? Shared pretraining data, distillation, and alignment pipelines can induce hidden behavioral dependencies, latent entanglement, that undermine multi-model systems such as LLM-as-a-judge pipelines and ensemble verification, which implicitly assume independent signals. In practice, this manifests as correlated reasoning patterns and synchronized failures, where apparent agreement reflects shared error modes rather than independent validation. To address this, we develop a statistical framework for auditing behavioral entanglement among black-box LLMs. Our approach introduces a multi-resolution hierarchy that characterizes the joint failure manifold through two information-theoretic metrics: (i) a Difficulty-Weighted Behavioral Entanglement Index, which amplifies synchronized failures on easy tasks, and (ii) a Cumulative Information Gain (CIG) metric, which captures directional alignment in erroneous responses. Through extensive experiments on 18 LLMs from six model families, we identify widespread behavioral entanglement and analyze its impact on LLM-as-a-judge evaluation. We find that CIG exhibits a statistically significant association with degradation in judge precision, with Spearman coefficient of 0.64 (p < 0.001) for GPT-4o-mini and 0.71 (p < 0.01) for Llama3-based judges, indicating that stronger dependency corresponds to increased over-endorsement bias. Finally, we demonstrate a practical use case of entanglement through de-entangled verifier ensemble reweighting. By adjusting model contributions based on inferred independence, the proposed method mitigates correlated bias and improves verification performance, achieving up to a 4.5% accuracy gain over majority voting.
Knowledge-Grounded Agentic Large Language Models for Multi-Hazard Understanding from Reconnaissance Reports
Nov 19, 2025Post-disaster reconnaissance reports contain critical evidence for understanding multi-hazard interactions, yet their unstructured narratives make systematic knowledge transfer difficult. Large language models (LLMs) offer new potential for analyzing these reports, but often generate unreliable or hallucinated outputs when domain grounding is absent. This study introduces the Mixture-of-Retrieval Agentic RAG (MoRA-RAG), a knowledge-grounded LLM framework that transforms reconnaissance reports into a structured foundation for multi-hazard reasoning. The framework integrates a Mixture-of-Retrieval mechanism that dynamically routes queries across hazard-specific databases while using agentic chunking to preserve contextual coherence during retrieval. It also includes a verification loop that assesses evidence sufficiency, refines queries, and initiates targeted searches when information remains incomplete. We construct HazardRecQA by deriving question-answer pairs from GEER reconnaissance reports, which document 90 global events across seven major hazard types. MoRA-RAG achieves up to 94.5 percent accuracy, outperforming zero-shot LLMs by 30 percent and state-of-the-art RAG systems by 10 percent, while reducing hallucinations across diverse LLM architectures. MoRA-RAG also enables open-weight LLMs to achieve performance comparable to proprietary models. It establishes a new paradigm for transforming post-disaster documentation into actionable, trustworthy intelligence for hazard resilience.
Reconstructing Human Mobility Pattern: A Semi-Supervised Approach for Cross-Dataset Transfer Learning
Oct 03, 2024



Understanding human mobility patterns is crucial for urban planning, transportation management, and public health. This study tackles two primary challenges in the field: the reliance on trajectory data, which often fails to capture the semantic interdependencies of activities, and the inherent incompleteness of real-world trajectory data. We have developed a model that reconstructs and learns human mobility patterns by focusing on semantic activity chains. We introduce a semi-supervised iterative transfer learning algorithm to adapt models to diverse geographical contexts and address data scarcity. Our model is validated using comprehensive datasets from the United States, where it effectively reconstructs activity chains and generates high-quality synthetic mobility data, achieving a low Jensen-Shannon Divergence (JSD) value of 0.001, indicating a close similarity between synthetic and real data. Additionally, sparse GPS data from Egypt is used to evaluate the transfer learning algorithm, demonstrating successful adaptation of US mobility patterns to Egyptian contexts, achieving a 64\% of increase in similarity, i.e., a JSD reduction from 0.09 to 0.03. This mobility reconstruction model and the associated transfer learning algorithm show significant potential for global human mobility modeling studies, enabling policymakers and researchers to design more effective and culturally tailored transportation solutions.
NUMOSIM: A Synthetic Mobility Dataset with Anomaly Detection Benchmarks
Sep 04, 2024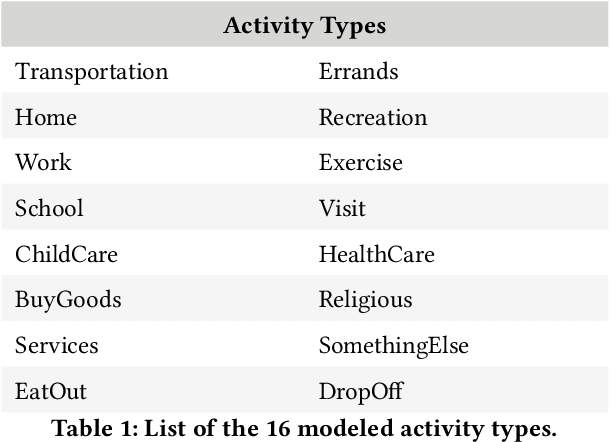
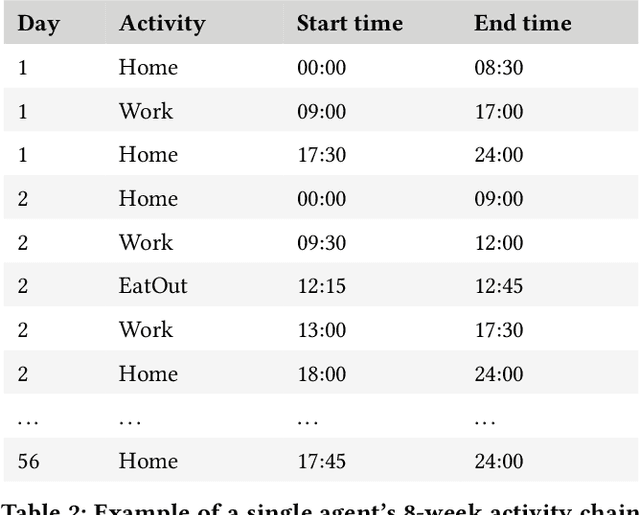
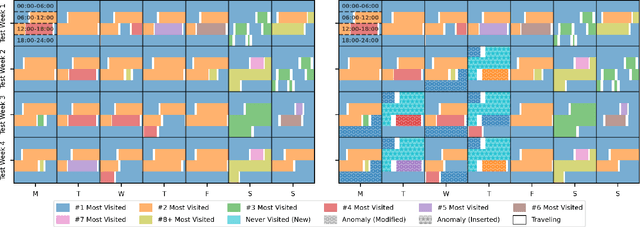
Collecting real-world mobility data is challenging. It is often fraught with privacy concerns, logistical difficulties, and inherent biases. Moreover, accurately annotating anomalies in large-scale data is nearly impossible, as it demands meticulous effort to distinguish subtle and complex patterns. These challenges significantly impede progress in geospatial anomaly detection research by restricting access to reliable data and complicating the rigorous evaluation, comparison, and benchmarking of methodologies. To address these limitations, we introduce a synthetic mobility dataset, NUMOSIM, that provides a controlled, ethical, and diverse environment for benchmarking anomaly detection techniques. NUMOSIM simulates a wide array of realistic mobility scenarios, encompassing both typical and anomalous behaviours, generated through advanced deep learning models trained on real mobility data. This approach allows NUMOSIM to accurately replicate the complexities of real-world movement patterns while strategically injecting anomalies to challenge and evaluate detection algorithms based on how effectively they capture the interplay between demographic, geospatial, and temporal factors. Our goal is to advance geospatial mobility analysis by offering a realistic benchmark for improving anomaly detection and mobility modeling techniques. To support this, we provide open access to the NUMOSIM dataset, along with comprehensive documentation, evaluation metrics, and benchmark results.
Deep Activity Model: A Generative Approach for Human Mobility Pattern Synthesis
May 24, 2024



Human mobility significantly impacts various aspects of society, including transportation, urban planning, and public health. The increasing availability of diverse mobility data and advancements in deep learning have revolutionized mobility modeling. Existing deep learning models, however, mainly study spatio-temporal patterns using trajectories and often fall short in capturing the underlying semantic interdependency among activities. Moreover, they are also constrained by the data source. These two factors thereby limit their realism and adaptability, respectively. Meanwhile, traditional activity-based models (ABMs) in transportation modeling rely on rigid assumptions and are costly and time-consuming to calibrate, making them difficult to adapt and scale to new regions, especially those regions with limited amount of required conventional travel data. To address these limitations, we develop a novel generative deep learning approach for human mobility modeling and synthesis, using ubiquitous and open-source data. Additionally, the model can be fine-tuned with local data, enabling adaptable and accurate representations of mobility patterns across different regions. The model is evaluated on a nationwide dataset of the United States, where it demonstrates superior performance in generating activity chains that closely follow ground truth distributions. Further tests using state- or city-specific datasets from California, Washington, and Mexico City confirm its transferability. This innovative approach offers substantial potential to advance mobility modeling research, especially in generating human activity chains as input for downstream activity-based mobility simulation models and providing enhanced tools for urban planners and policymakers.
Semantic Trajectory Data Mining with LLM-Informed POI Classification
May 20, 2024



Human travel trajectory mining is crucial for transportation systems, enhancing route optimization, traffic management, and the study of human travel patterns. Previous rule-based approaches without the integration of semantic information show a limitation in both efficiency and accuracy. Semantic information, such as activity types inferred from Points of Interest (POI) data, can significantly enhance the quality of trajectory mining. However, integrating these insights is challenging, as many POIs have incomplete feature information, and current learning-based POI algorithms require the integrity of datasets to do the classification. In this paper, we introduce a novel pipeline for human travel trajectory mining. Our approach first leverages the strong inferential and comprehension capabilities of large language models (LLMs) to annotate POI with activity types and then uses a Bayesian-based algorithm to infer activity for each stay point in a trajectory. In our evaluation using the OpenStreetMap (OSM) POI dataset, our approach achieves a 93.4% accuracy and a 96.1% F-1 score in POI classification, and a 91.7% accuracy with a 92.3% F-1 score in activity inference.