 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion Boundary and Depth: Mutual Enhancement via Multi-Task Learning
May 27, 2025Occlusion Boundary Estimation (OBE) identifies boundaries arising from both inter-object occlusions and self-occlusion within individual objects, distinguishing intrinsic object edges from occlusion-induced contours to improve scene understanding and 3D reconstruction capacity. This is closely related to Monocular Depth Estimation (MDE), which infers depth from a single image, as occlusion boundaries provide critical geometric cues for resolving depth ambiguities, while depth priors can conversely refine occlusion reasoning in complex scenes. In this paper, we propose a novel network, MoDOT, that first jointly estimates depth and OBs. We propose CASM, a cross-attention multi-scale strip convolution module, leverages mid-level OB features to significantly enhance depth prediction. Additionally, we introduce an occlusion-aware loss function, OBDCL, which encourages sharper and more accurate depth boundaries. Extensive experiments on both real and synthetic datasets demonstrate the mutual benefits of jointly estimating depth and OB, and highlight the effectiveness of our model design. Our method achieves the state-of-the-art (SOTA) on both our proposed synthetic datasets and one popular real dataset, NYUD-v2, significantly outperforming multi-task baselines. Besides, without domain adaptation, results on real-world depth transfer are comparable to the competitors, while preserving sharp occlusion boundaries for geometric fidelity. We will release our code, pre-trained models, and datasets to support future research in this direction.
Interactive Occlusion Boundary Estimation through Exploitation of Synthetic Data
Aug 27, 2024Occlusion boundaries (OBs) geometrically localize the occlusion events in a 2D image, and contain useful information for addressing various scene understanding problems. To advance their study, we have led the investigation in the following three aspects. Firstly, we have studied interactive estimation of OBs, which is the first in the literature, and proposed an efficient deep-network-based method using multiple-scribble intervention, named DNMMSI, which significantly improves the performance over the state-of-the-art fully-automatic methods. Secondly, we propose to exploit the synthetic benchmark for the training process, thanks to the particularity that OBs are determined geometrically and unambiguously from the 3D scene. To this end, we have developed an efficient tool, named Mesh2OB, for the automatic generation of 2D images together with their ground-truth OBs, using which we have constructed a synthetic benchmark, named OB-FUTURE. Abundant experimental results demonstrate that leveraging such a synthetic benchmark for training achieves promising performance, even without the use of domain adaptation techniques. Finally, to achieve a more compelling and robust evaluation in OB-related research, we have created a real benchmark, named OB-LabName, consisting of 120 high-resolution images together with their ground-truth OBs, with precision surpassing that of previous benchmarks. We will release DNMMSI with pre-trained parameters, Mesh2OB, OB-FUTURE, and OB-LabName to support further research.
Pixel-Pair Occlusion Relationship Map(P2ORM): Formulation, Inference & Application
Jul 23, 2020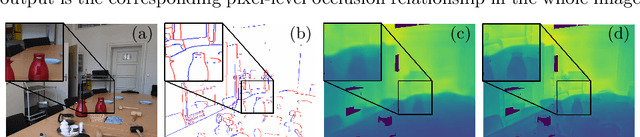
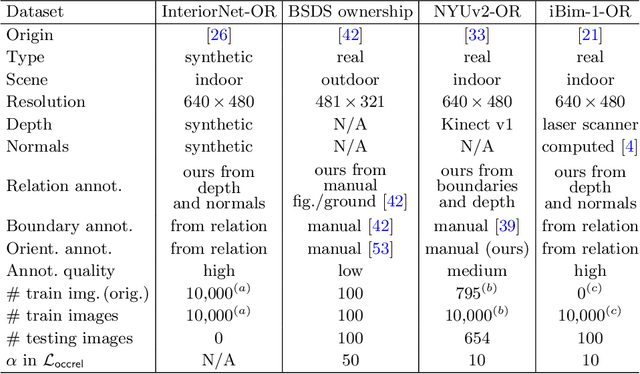
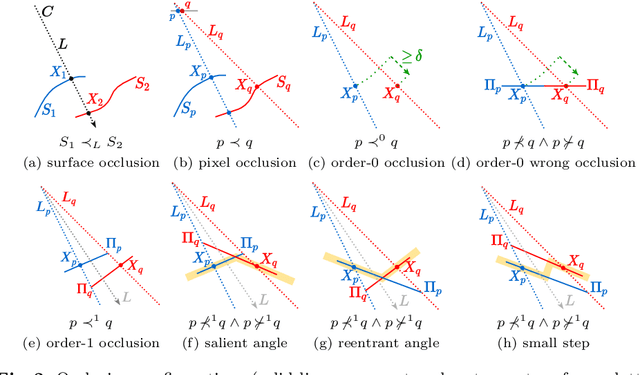
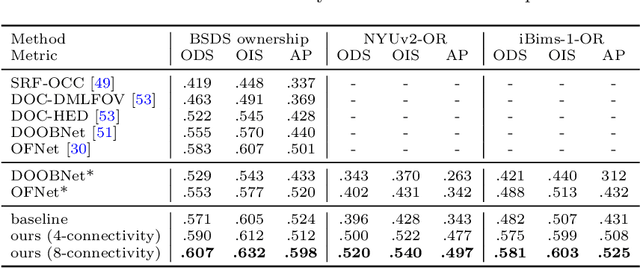
We formalize concepts around geometric occlusion in 2D images (i.e., ignoring semantics), and propose a novel unified formulation of both occlusion boundaries and occlusion orientations via a pixel-pair occlusion relation. The former provides a way to generate large-scale accurate occlusion datasets while, based on the latter, we propose a novel method for task-independent pixel-level occlusion relationship estimation from single images. Experiments on a variety of datasets demonstrate that our method outperforms existing ones on this task. To further illustrate the value of our formulation, we also propose a new depth map refinement method that consistently improve the performance of state-of-the-art monocular depth estimation methods. Our code and data are available at http://imagine.enpc.fr/~qiux/P2ORM/.
Robust Angular Local Descriptor Learning
Jan 26, 2019
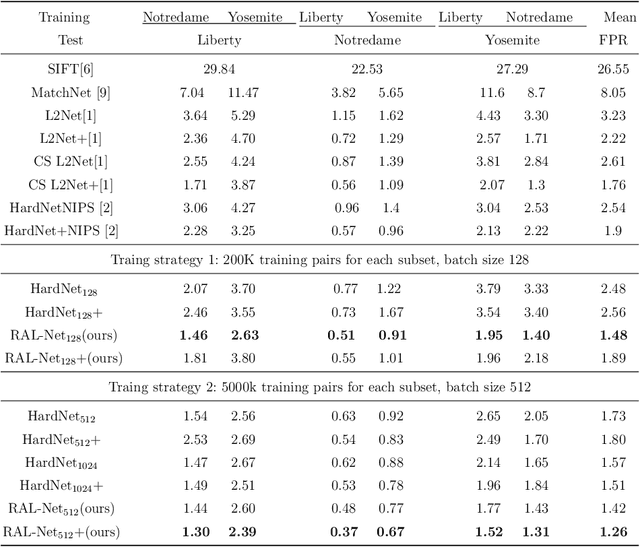
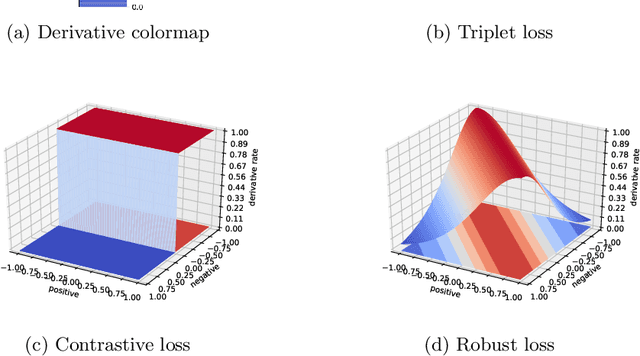
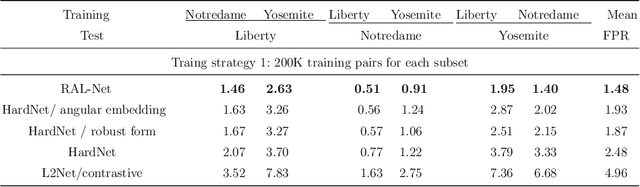
In recent years, the learned local descriptors have outperformed handcrafted ones by a large margin, due to the powerful deep convolutional neural network architectures such as L2-Net [1] and triplet based metric learning [2]. However, there are two problems in the current methods, which hinders the overall performance. Firstly, the widely-used margin loss is sensitive to incorrect correspondences, which are prevalent in the existing local descriptor learning datasets. Second, the L2 distance ignores the fact that the feature vectors have been normalized to unit norm. To tackle these two problems and further boost the performance, we propose a robust angular loss which 1) uses cosine similarity instead of L2 distance to compare descriptors and 2) relies on a robust loss function that gives smaller penalty to triplets with negative relative similarity. The resulting descriptor shows robustness on different datasets, reaching the state-of-the-art result on Brown dataset , as well as demonstrating excellent generalization ability on the Hpatches dataset and a Wide Baseline Stereo dataset.
Geometry-Consistent Adversarial Networks for One-Sided Unsupervised Domain Mapping
Sep 16, 2018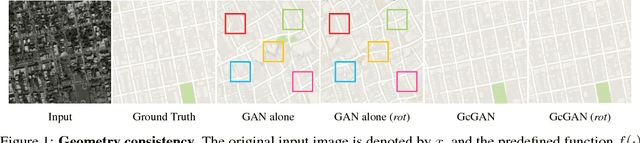
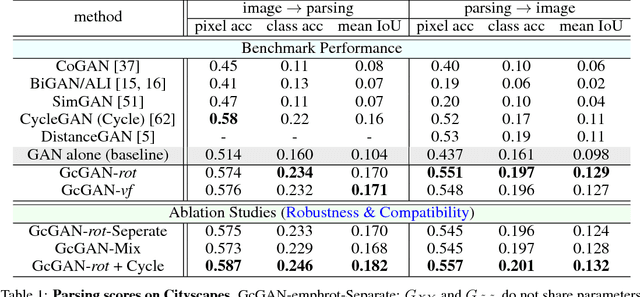
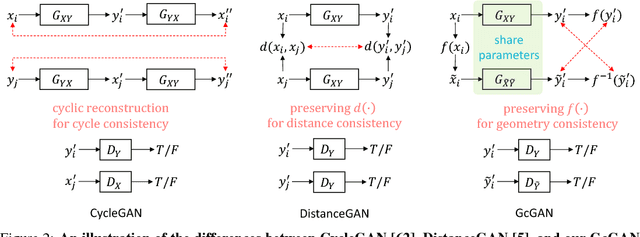
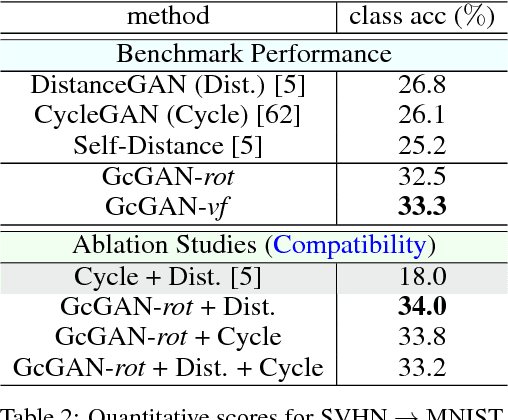
Unsupervised domain mapping aims at learning a function to translate domain X to Y (GXY : X to Y) in the absence of paired (X,Y) samples. Finding the optimal GXY without paired data is an ill-posed problem and hence appropriate constraints are required to obtain reasonable solutions. One of the most prominent constraint is cycle-consistency, which enforces the translated image by GXY to be translated back to the input image by an inverse mapping GYX. While cycle-consistency requires simultaneous training of GXY and GYX, recent methods have demonstrated one-sided domain mapping (only learn GXY) can be achieved by preserving pairwise distance between images before and after translation. Although cycle-consistency and distance preserving successfully constrain the solution space, they overlook the special properties of images that simple geometric transformations do not change the semantics of an image. Based on this special property, we develop a geometry-consistent adversarial network (GcGAN) which enables one-sided unsupervised domain mapping. Our GcGAN takes the original image and its counterpart image transformed by a predefined geometric transformation as inputs and generates two images in the new domain with the corresponding geometry-consistency constraint. The geometry-consistency constraint eliminates unreasonable solutions and produce more reliable solutions. Quantitative comparisons against baseline (GAN alone) and the state-of-the-art methods, including DistanceGAN and CycleGAN, demonstrate the superiority of our method in generating realistic images.
MoE-SPNet: A Mixture-of-Experts Scene Parsing Network
Jun 19, 2018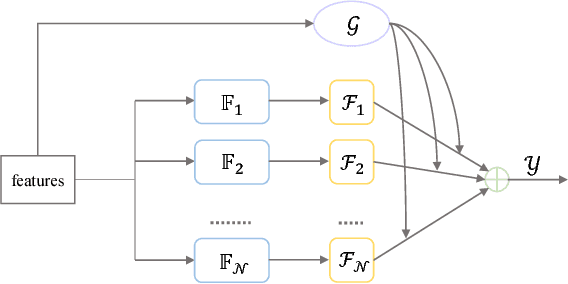
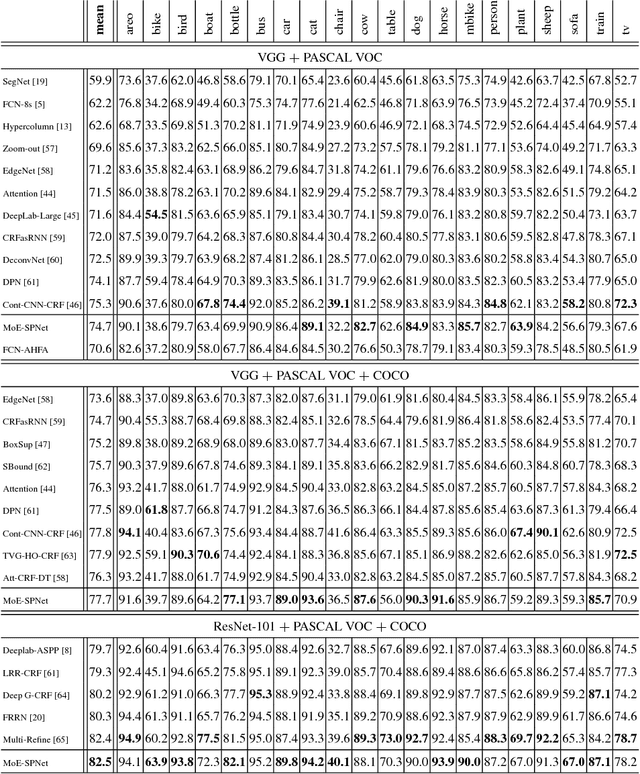
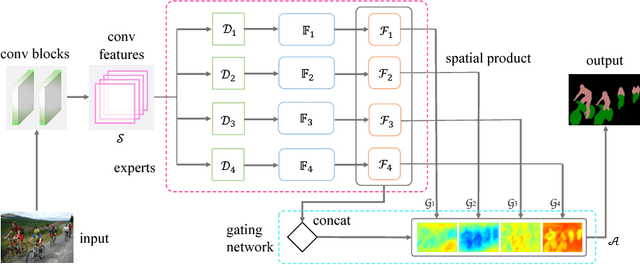
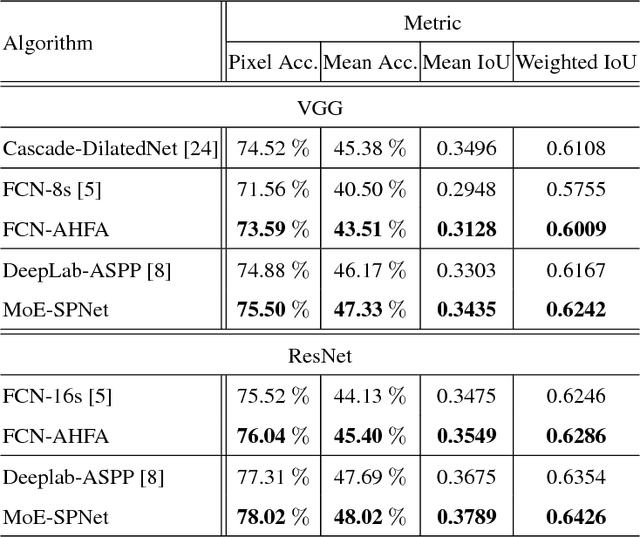
Scene parsing is an indispensable component in understanding the semantics within a scene. Traditional methods rely on handcrafted local features and probabilistic graphical models to incorporate local and global cues. Recently, methods based on fully convolutional neural networks have achieved new records on scene parsing. An important strategy common to these methods is the aggregation of hierarchical features yielded by a deep convolutional neural network. However, typical algorithms usually aggregate hierarchical convolutional features via concatenation or linear combination, which cannot sufficiently exploit the diversities of contextual information in multi-scale features and the spatial inhomogeneity of a scene. In this paper, we propose a mixture-of-experts scene parsing network (MoE-SPNet) that incorporates a convolutional mixture-of-experts layer to assess the importance of features from different levels and at different spatial locations. In addition, we propose a variant of mixture-of-experts called the adaptive hierarchical feature aggregation (AHFA) mechanism which can be incorporated into existing scene parsing networks that use skip-connections to fuse features layer-wisely. In the proposed networks, different levels of features at each spatial location are adaptively re-weighted according to the local structure and surrounding contextual information before aggregation. We demonstrate the effectiveness of the proposed methods on two scene parsing datasets including PASCAL VOC 2012 and SceneParse150 based on two kinds of baseline models FCN-8s and DeepLab-ASPP.
A Compromise Principle in Deep Monocular Depth Estimation
Jun 12, 2018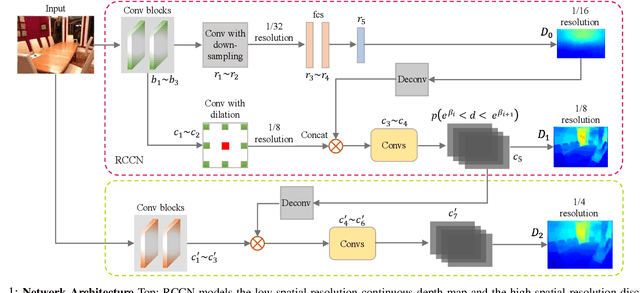

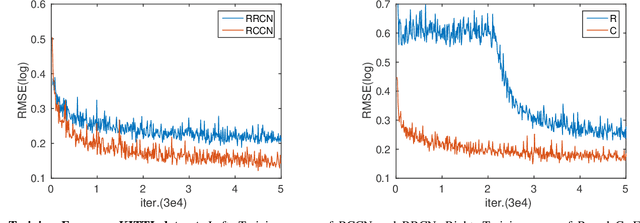

Monocular depth estimation, which plays a key role in understanding 3D scene geometry, is fundamentally an ill-posed problem. Existing methods based on deep convolutional neural networks (DCNNs) have examined this problem by learning convolutional networks to estimate continuous depth maps from monocular images. However, we find that training a network to predict a high spatial resolution continuous depth map often suffers from poor local solutions. In this paper, we hypothesize that achieving a compromise between spatial and depth resolutions can improve network training. Based on this "compromise principle", we propose a regression-classification cascaded network (RCCN), which consists of a regression branch predicting a low spatial resolution continuous depth map and a classification branch predicting a high spatial resolution discrete depth map. The two branches form a cascaded structure allowing the classification and regression branches to benefit from each other. By leveraging large-scale raw training datasets and some data augmentation strategies, our network achieves top or state-of-the-art results on the NYU Depth V2, KITTI, and Make3D benchmarks.
Deep Ordinal Regression Network for Monocular Depth Estimation
Jun 06, 2018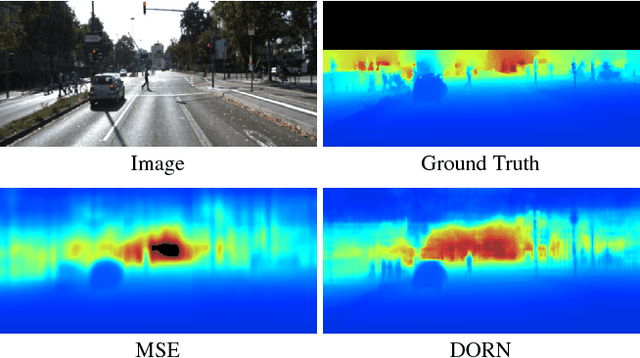
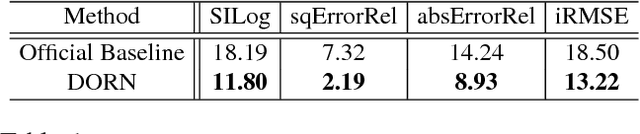
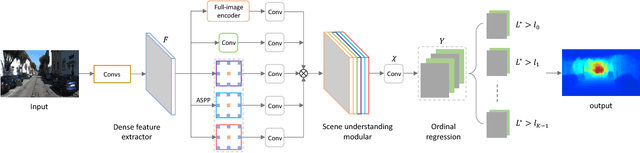
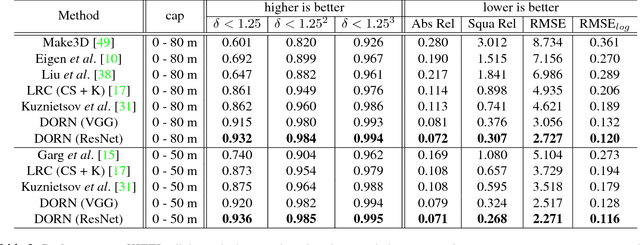
Monocular depth estimation, which plays a crucial role in understanding 3D scene geometry, is an ill-posed problem. Recent methods have gained significant improvement by exploring image-level information and hierarchical features from deep convolutional neural networks (DCNNs). These methods model depth estimation as a regression problem and train the regression networks by minimizing mean squared error, which suffers from slow convergence and unsatisfactory local solutions. Besides, existing depth estimation networks employ repeated spatial pooling operations, resulting in undesirable low-resolution feature maps. To obtain high-resolution depth maps, skip-connections or multi-layer deconvolution networks are required, which complicates network training and consumes much more computations. To eliminate or at least largely reduce these problems, we introduce a spacing-increasing discretization (SID) strategy to discretize depth and recast depth network learning as an ordinal regression problem. By training the network using an ordinary regression loss, our method achieves much higher accuracy and \dd{faster convergence in synch}. Furthermore, we adopt a multi-scale network structure which avoids unnecessary spatial pooling and captures multi-scale information in parallel. The method described in this paper achieves state-of-the-art results on four challenging benchmarks, i.e., KITTI [17], ScanNet [9], Make3D [50], and NYU Depth v2 [42], and win the 1st prize in Robust Vision Challenge 2018. Code has been made available at: https://github.com/hufu6371/DORN.
Perceptual Adversarial Networks for Image-to-Image Transformation
Jun 28, 2017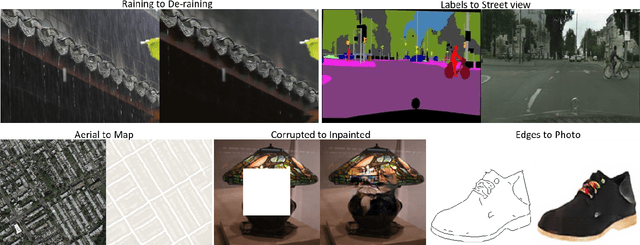



In this paper, we propose a principled Perceptual Adversarial Networks (PAN) for image-to-image transformation tasks. Unlike existing application-specific algorithms, PAN provides a generic framework of learning mapping relationship between paired images (Fig. 1), such as mapping a rainy image to its de-rained counterpart, object edges to its photo, semantic labels to a scenes image, etc. The proposed PAN consists of two feed-forward convolutional neural networks (CNNs), the image transformation network T and the discriminative network D. Through combining the generative adversarial loss and the proposed perceptual adversarial loss, these two networks can be trained alternately to solve image-to-image transformation tasks. Among them, the hidden layers and output of the discriminative network D are upgraded to continually and automatically discover the discrepancy between the transformed image and the corresponding ground-truth. Simultaneously, the image transformation network T is trained to minimize the discrepancy explored by the discriminative network D. Through the adversarial training process, the image transformation network T will continually narrow the gap between transformed images and ground-truth images. Experiments evaluated on several image-to-image transformation tasks (e.g., image de-raining, image inpainting, etc.) show that the proposed PAN outperforms many related state-of-the-art methods.