 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Topological Data Analysis and Visualization for Evaluating Data-Driven Models in Scientific Applications
Jul 19, 2019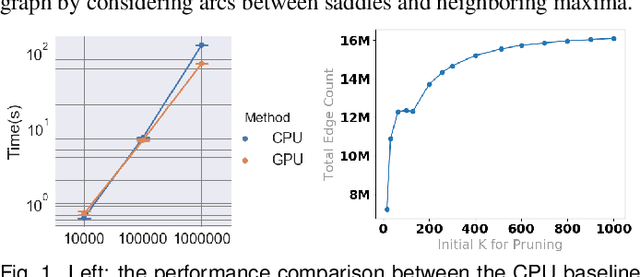
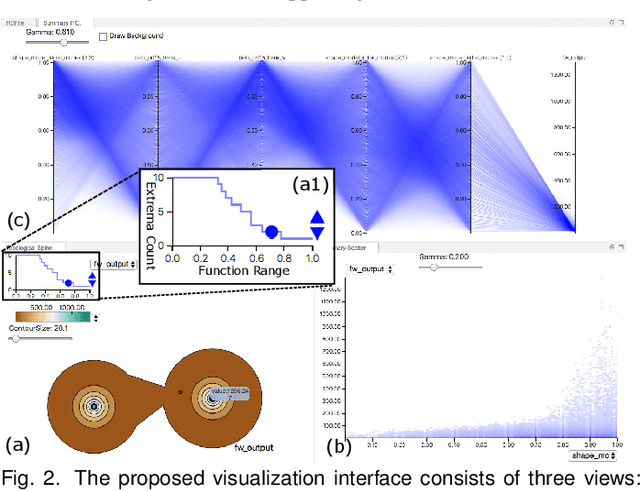
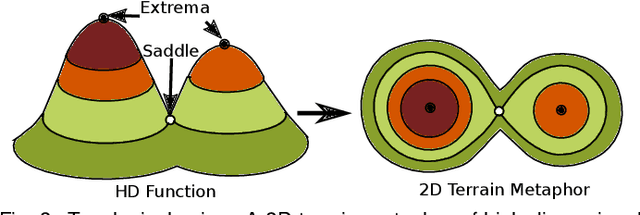
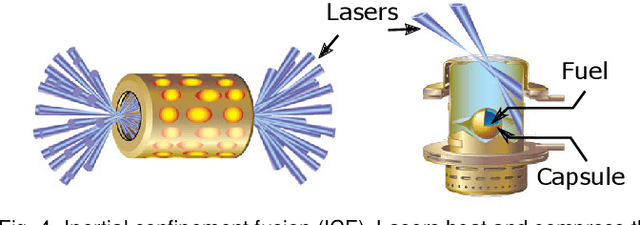
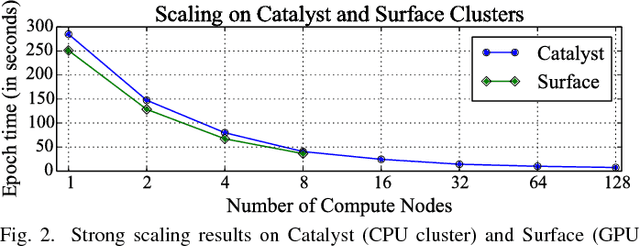
With the rapid adoption of machine learning techniques for large-scale applications in science and engineering comes the convergence of two grand challenges in visualization. First, the utilization of black box models (e.g., deep neural networks) calls for advanced techniques in exploring and interpreting model behaviors. Second, the rapid growth in computing has produced enormous datasets that require techniques that can handle millions or more samples. Although some solutions to these interpretability challenges have been proposed, they typically do not scale beyond thousands of samples, nor do they provide the high-level intuition scientists are looking for. Here, we present the first scalable solution to explore and analyze high-dimensional functions often encountered in the scientific data analysis pipeline. By combining a new streaming neighborhood graph construction, the corresponding topology computation, and a novel data aggregation scheme, namely topology aware datacubes, we enable interactive exploration of both the topological and the geometric aspect of high-dimensional data. Following two use cases from high-energy-density (HED) physics and computational biology, we demonstrate how these capabilities have led to crucial new insights in both applications.
Distinguishing between Normal and Cancer Cells Using Autoencoder Node Saliency
Jan 30, 2019
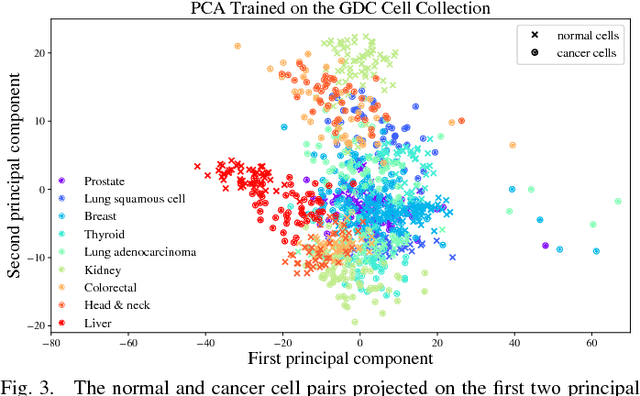
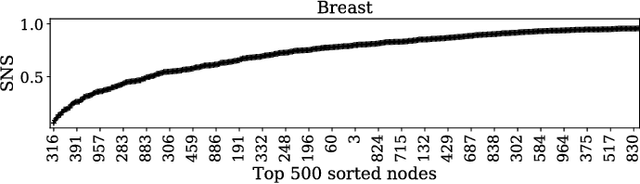
Gene expression profiles have been widely used to characterize patterns of cellular responses to diseases. As data becomes available, scalable learning toolkits become essential to processing large datasets using deep learning models to model complex biological processes. We present an autoencoder to capture nonlinear relationships recovered from gene expression profiles. The autoencoder is a nonlinear dimension reduction technique using an artificial neural network, which learns hidden representations of unlabeled data. We train the autoencoder on a large collection of tumor samples from the National Cancer Institute Genomic Data Commons, and obtain a generalized and unsupervised latent representation. We leverage a HPC-focused deep learning toolkit, Livermore Big Artificial Neural Network (LBANN) to efficiently parallelize the training algorithm, reducing computation times from several hours to a few minutes. With the trained autoencoder, we generate latent representations of a small dataset, containing pairs of normal and cancer cells of various tumor types. A novel measure called autoencoder node saliency (ANS) is introduced to identify the hidden nodes that best differentiate various pairs of cells. We compare our findings of the best classifying nodes with principal component analysis and the visualization of t-distributed stochastic neighbor embedding. We demonstrate that the autoencoder effectively extracts distinct gene features for multiple learning tasks in the dataset.