 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-Inspired Adversarial Attack Against Deep Neural Networks
Jun 30, 2021



The paper develops a new adversarial attack against deep neural networks (DNN), based on applying bio-inspired design to moving physical objects. To the best of our knowledge, this is the first work to introduce physical attacks with a moving object. Instead of following the dominating attack strategy in the existing literature, i.e., to introduce minor perturbations to a digital input or a stationary physical object, we show two new successful attack strategies in this paper. We show by superimposing several patterns onto one physical object, a DNN becomes confused and picks one of the patterns to assign a class label. Our experiment with three flapping wing robots demonstrates the possibility of developing an adversarial camouflage to cause a targeted mistake by DNN. We also show certain motion can reduce the dependency among consecutive frames in a video and make an object detector "blind", i.e., not able to detect an object exists in the video. Hence in a successful physical attack against DNN, targeted motion against the system should also be considered.
* Published in SafeAI 2020
Adversarial Machine Learning for Cybersecurity and Computer Vision: Current Developments and Challenges
Jun 30, 2021
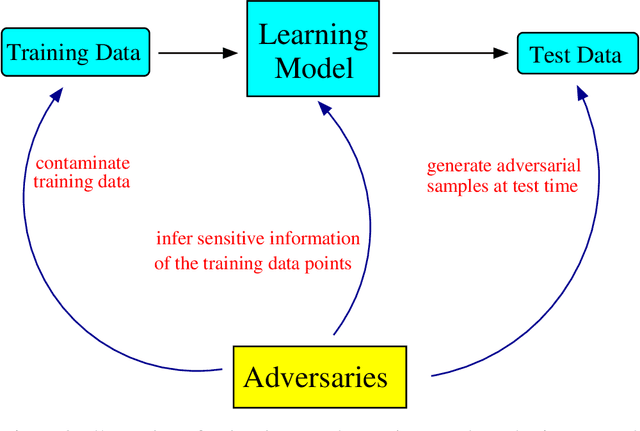
We provide a comprehensive overview of adversarial machine learning focusing on two application domains, i.e., cybersecurity and computer vision. Research in adversarial machine learning addresses a significant threat to the wide application of machine learning techniques -- they are vulnerable to carefully crafted attacks from malicious adversaries. For example, deep neural networks fail to correctly classify adversarial images, which are generated by adding imperceptible perturbations to clean images.We first discuss three main categories of attacks against machine learning techniques -- poisoning attacks, evasion attacks, and privacy attacks. Then the corresponding defense approaches are introduced along with the weakness and limitations of the existing defense approaches. We notice adversarial samples in cybersecurity and computer vision are fundamentally different. While adversarial samples in cybersecurity often have different properties/distributions compared with training data, adversarial images in computer vision are created with minor input perturbations. This further complicates the development of robust learning techniques, because a robust learning technique must withstand different types of attacks.
* Published in WIREs Computational Statistics
Understanding Adversarial Examples Through Deep Neural Network's Response Surface and Uncertainty Regions
Jun 30, 2021

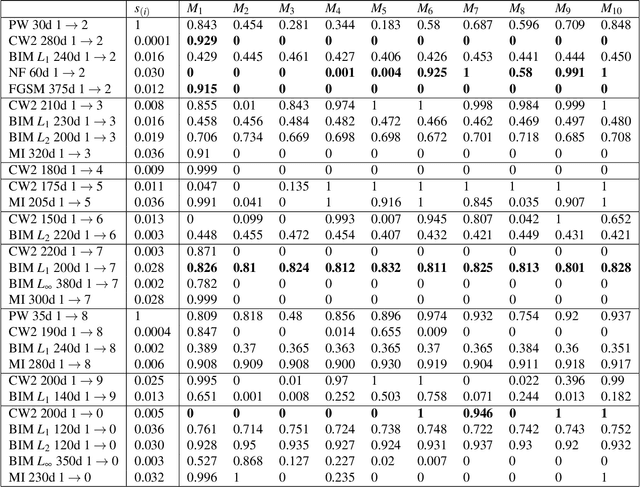
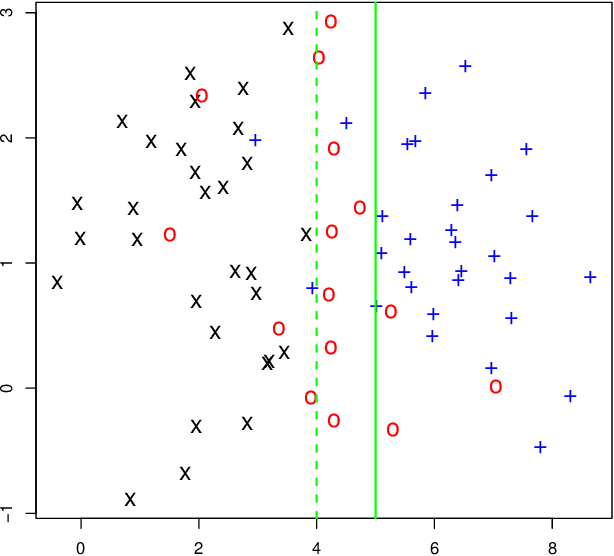
Deep neural network (DNN) is a popular model implemented in many systems to handle complex tasks such as image classification, object recognition, natural language processing etc. Consequently DNN structural vulnerabilities become part of the security vulnerabilities in those systems. In this paper we study the root cause of DNN adversarial examples. We examine the DNN response surface to understand its classification boundary. Our study reveals the structural problem of DNN classification boundary that leads to the adversarial examples. Existing attack algorithms can generate from a handful to a few hundred adversarial examples given one clean image. We show there are infinitely many adversarial images given one clean sample, all within a small neighborhood of the clean sample. We then define DNN uncertainty regions and show transferability of adversarial examples is not universal. We also argue that generalization error, the large sample theoretical guarantee established for DNN, cannot adequately capture the phenomenon of adversarial examples. We need new theory to measure DNN robustness.
Breaking Transferability of Adversarial Samples with Randomness
Jun 17, 2018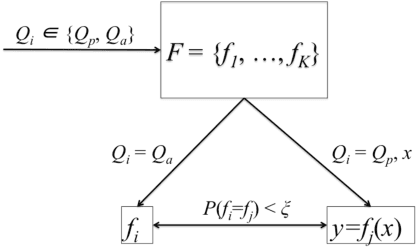
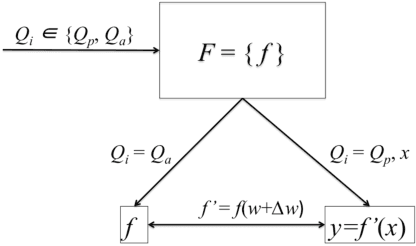
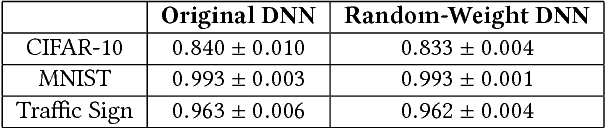

We investigate the role of transferability of adversarial attacks in the observed vulnerabilities of Deep Neural Networks (DNNs). We demonstrate that introducing randomness to the DNN models is sufficient to defeat adversarial attacks, given that the adversary does not have an unlimited attack budget. Instead of making one specific DNN model robust to perfect knowledge attacks (a.k.a, white box attacks), creating randomness within an army of DNNs completely eliminates the possibility of perfect knowledge acquisition, resulting in a significantly more robust DNN ensemble against the strongest form of attacks. We also show that when the adversary has an unlimited budget of data perturbation, all defensive techniques would eventually break down as the budget increases. Therefore, it is important to understand the game saddle point where the adversary would not further pursue this endeavor. Furthermore, we explore the relationship between attack severity and decision boundary robustness in the version space. We empirically demonstrate that by simply adding a small Gaussian random noise to the learned weights, a DNN model can increase its resilience to adversarial attacks by as much as 74.2%. More importantly, we show that by randomly activating/revealing a model from a pool of pre-trained DNNs at each query request, we can put a tremendous strain on the adversary's attack strategies. We compare our randomization techniques to the Ensemble Adversarial Training technique and show that our randomization techniques are superior under different attack budget constraints.
Adversarial Clustering: A Grid Based Clustering Algorithm Against Active Adversaries
Apr 13, 2018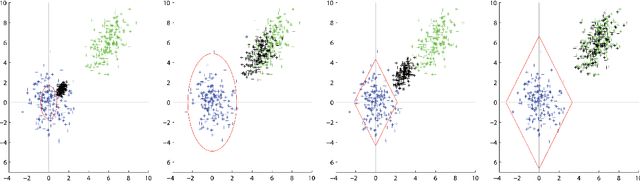
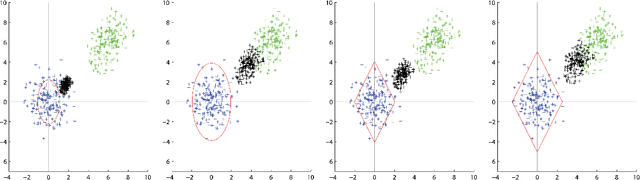
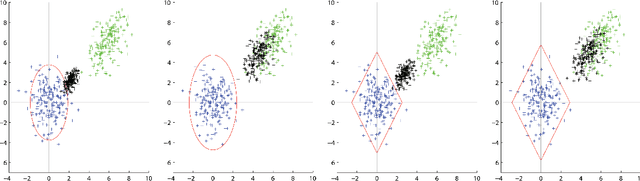
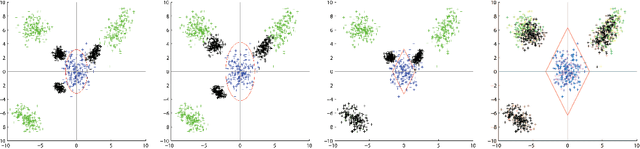
Nowadays more and more data are gathered for detecting and preventing cyber attacks. In cyber security applications, data analytics techniques have to deal with active adversaries that try to deceive the data analytics models and avoid being detected. The existence of such adversarial behavior motivates the development of robust and resilient adversarial learning techniques for various tasks. Most of the previous work focused on adversarial classification techniques, which assumed the existence of a reasonably large amount of carefully labeled data instances. However, in practice, labeling the data instances often requires costly and time-consuming human expertise and becomes a significant bottleneck. Meanwhile, a large number of unlabeled instances can also be used to understand the adversaries' behavior. To address the above mentioned challenges, in this paper, we develop a novel grid based adversarial clustering algorithm. Our adversarial clustering algorithm is able to identify the core normal regions, and to draw defensive walls around the centers of the normal objects utilizing game theoretic ideas. Our algorithm also identifies sub-clusters of attack objects, the overlapping areas within clusters, and outliers which may be potential anomalies.